
Browse Source
Initial commit

commit
1b87d2cde7
91 changed files with 14974 additions and 0 deletions
Split View
Diff Options
-
+13 -0.gitignore
-
+25 -0blag.cabal
-
+45 -0css/code.css
-
+13 -0css/computermodern.css
-
+469 -0css/default.scss
-
+1 -0css/katex.min.css
-
+15 -0diagrams/cc/delimcc.tex
-
+1 -0diagrams/eq/0cube.tex
-
+4 -0diagrams/eq/1cube.tex
-
+6 -0diagrams/eq/2cube.tex
-
+5 -0diagrams/eq/interval.tex
-
+39 -0diagrams/gm/app_gx.tex
-
+51 -0diagrams/gm/app_kgx.tex
-
+25 -0diagrams/gm/entry.tex
-
+31 -0diagrams/gm/push_g.tex
-
+44 -0diagrams/gm/push_k.tex
-
+33 -0diagrams/gm/push_x.tex
-
+34 -0diagrams/gm/slide_3.tex
-
+25 -0diagrams/gm/spine+stack.tex
-
+14 -0diagrams/gm/spine.tex
-
+1 -0diagrams/template/step1.tex
-
+26 -0diagrams/template/step2.tex
-
+33 -0diagrams/template/step3.tex
-
+38 -0diagrams/template/step4.tex
-
+38 -0diagrams/template/step4red.tex
-
+22 -0diagrams/template/step5.tex
-
+2 -0hie.yaml
-
+140 -0package-lock.json
-
+21 -0package.json
-
+35 -0pages/contact.md
-
+13 -0pages/index.html
-
+14 -0pages/oss.md
-
+308 -0pages/posts/2016-08-17-parsec.md
-
+331 -0pages/posts/2016-08-23-hasochism.lhs
-
+172 -0pages/posts/2016-08-26-parsec2.lhs
-
+155 -0pages/posts/2017-08-01-delimcc.md
-
+231 -0pages/posts/2017-08-02-urnmatch.md
-
+276 -0pages/posts/2017-08-06-constraintprop.md
-
+280 -0pages/posts/2017-08-15-multimethods.md
-
+516 -0pages/posts/2017-09-08-dependent-types.md
-
+456 -0pages/posts/2018-01-18-amulet.md
-
+609 -0pages/posts/2018-02-18-amulet-tc2.md
-
+286 -0pages/posts/2018-03-14-amulet-safety.md
-
+247 -0pages/posts/2018-03-27-amulet-gadts.md
-
+304 -0pages/posts/2018-08-11-amulet-updates.md
-
+329 -0pages/posts/2019-01-28-mldelta.lhs
-
+191 -0pages/posts/2019-09-22-amulet-records.md
-
+136 -0pages/posts/2019-09-25-amc-prove.md
-
+202 -0pages/posts/2019-09-29-amc-prove-interactive.md
-
+369 -0pages/posts/2019-10-04-amulet-kinds.md
-
+126 -0pages/posts/2019-10-19-amulet-quicklook.md
-
+1355 -0pages/posts/2020-01-31-lazy-eval.lhs
-
+380 -0pages/posts/2020-07-12-continuations.md
-
+162 -0pages/posts/2020-09-09-typing-proof.md
-
+264 -0pages/posts/2020-10-30-reflecting-equality.md
-
+637 -0pages/posts/2021-01-15-induction.md
-
+321 -0site.hs
-
+6 -0stack.yaml
-
+33 -0stack.yaml.lock
-
+140 -0static/Parser.hs
-
+239 -0static/Parser.hs.html
-
+10 -0static/default.css
-
+100 -0static/demorgan-1.ml.html
-
+3024 -0static/doom.svg
-
+119 -0static/forth_machine.js
-
+22 -0static/generated_code.lua
-
+124 -0static/generated_code.lua.html
-
BINstatic/icon/android-chrome-192x192.png
-
BINstatic/icon/android-chrome-512x512.png
-
BINstatic/icon/apple-touch-icon.png
-
BINstatic/icon/favicon-16x16.png
-
BINstatic/icon/favicon-32x32.png
-
BINstatic/icon/favicon.ico
-
BINstatic/icon/valid-html20.png
-
+93 -0static/licenses/LICENSE.FantasqueSansMono
-
+21 -0static/licenses/LICENSE.KaTeX
-
BINstatic/pfp.jpg
-
+215 -0static/profunctor-impredicative.ml.html
-
+224 -0static/profunctors.ml.html
-
+26 -0static/tasks.lisp
-
+126 -0static/tasks.lisp.html
-
BINstatic/verify_error.png
-
BINstatic/verify_warn.png
-
+8 -0sync
-
+190 -0syntax/amcprove.xml
-
+222 -0syntax/amulet.xml
-
+2 -0templates/archive.html
-
+71 -0templates/default.html
-
+10 -0templates/post-list.html
-
+10 -0templates/post.html
-
+20 -0templates/tikz.tex
+ 13
- 0
.gitignore
View File
| @ -0,0 +1,13 @@ | |||
| /.site | |||
| /.store | |||
| /.stack-work | |||
| /.vscode | |||
| /node_modules | |||
| /uni | |||
| /portfolio.md | |||
| /fonts | |||
| /css/fonts | |||
| /.mailmap | |||
+ 25
- 0
blag.cabal
View File
| @ -0,0 +1,25 @@ | |||
| name: blag | |||
| version: 0.1.0.0 | |||
| build-type: Simple | |||
| cabal-version: >= 1.10 | |||
| executable site | |||
| main-is: site.hs | |||
| build-depends: base | |||
| , hakyll | |||
| , pandoc | |||
| , skylighting | |||
| , process | |||
| , containers | |||
| , directory | |||
| , pandoc-types | |||
| , bytestring | |||
| , uri-encode | |||
| , deepseq | |||
| , text | |||
| , hsass | |||
| , hakyll-sass | |||
| ghc-options: -threaded | |||
| default-language: Haskell2010 | |||
| ghc-options: -optl-fuse-ld=lld | |||
+ 45
- 0
css/code.css
View File
| @ -0,0 +1,45 @@ | |||
| code, div.sourceCode { | |||
| font-family: Fantasque Sans Mono, Fira Mono, monospace; | |||
| font-size: 15pt; | |||
| } | |||
| code.inline { | |||
| background-color: rgb(250,250,250); | |||
| /* border: 1px solid rgb(200,200,200); */ | |||
| } | |||
| table.sourceCode, tr.sourceCode, td.lineNumbers, td.sourceCode { | |||
| margin: 0; padding: 0; vertical-align: baseline; border: none; | |||
| } | |||
| table.sourceCode { | |||
| width: 100%; line-height: 100%; | |||
| } | |||
| td.lineNumbers { text-align: right; padding-right: 4px; padding-left: 4px; color: #aaaaaa; border-right: 1px solid #aaaaaa; } | |||
| td.sourceCode { padding-left: 5px; } | |||
| code.kw, span.kw { color: #af005f; } /* Keyword */ | |||
| code.dt, span.dt { color: #5f5faf; } /* DataType */ | |||
| code.dv, span.dv { color: #268bd2; } /* DecVal */ | |||
| code.bn, span.bn { color: #268bd2; } /* BaseN */ | |||
| code.fl, span.fl { color: #268bd2; } /* Float */ | |||
| code.ch, span.ch { color: #cb4b16; } /* Char */ | |||
| code.st, span.st { color: #cb4b16; } /* String */ | |||
| code.co, span.co { color: #8a8a8a; } /* Comment */ | |||
| code.ot, span.ot { color: #007020; } /* Other */ | |||
| code.al, span.al { color: #ff0000; } /* Alert */ | |||
| code.fu, span.fu { color: #666666; } /* Function */ | |||
| code.er, span.er { color: #ff0000; } /* Error */ | |||
| code.wa, span.wa { color: #60a0b0; } /* Warning */ | |||
| code.cn, span.cn { color: #880000; } /* Constant */ | |||
| code.sc, span.sc { color: #4070a0; } /* SpecialChar */ | |||
| code.vs, span.vs { color: #4070a0; } /* VerbatimString */ | |||
| code.ss, span.ss { color: #2aa198; } /* SpecialString */ | |||
| code.va, span.va { color: #073642; } /* Variable */ | |||
| code.cf, span.cf { color: #007020; } /* ControlFlow */ | |||
| code.op, span.op { color: #d33682; } /* Operator */ | |||
| code.pp, span.pp { color: #bc7a00; } /* Preprocessor */ | |||
| code.at, span.at { color: #7d9029; } /* Attribute */ | |||
| code.do, span.do { color: #ba2121; } /* Documentation */ | |||
| code.an, span.an { color: #60a0b0; } /* Annotation */ | |||
| code.cv, span.cv { color: #60a0b0; } /* CommentVar */ | |||
+ 13
- 0
css/computermodern.css
View File
| @ -0,0 +1,13 @@ | |||
| @font-face { | |||
| font-family: "Computer Modern"; | |||
| src: url('/static/cmunorm.woff'); | |||
| } | |||
| .math { | |||
| font-family: Computer Modern, serif; | |||
| } | |||
| .math .display { | |||
| font-size: 18px; | |||
| text-align: center; | |||
| } | |||
+ 469
- 0
css/default.scss
View File
| @ -0,0 +1,469 @@ | |||
| $purple: #424969; | |||
| $orange: #ffac5f; | |||
| $blonde: #f5ddbc; | |||
| $light-purple: #faf0fa; | |||
| $yugo: #ea8472; | |||
| $header: $orange; | |||
| $header-height: 50px; | |||
| $max-width: 95ch; | |||
| .mathpar, .math-paragraph { | |||
| display: flex; | |||
| flex-direction: row; | |||
| flex-wrap: wrap; | |||
| justify-content: space-around; | |||
| align-items: center; | |||
| } | |||
| a#mastodon { | |||
| display: none; | |||
| } | |||
| html, body { | |||
| min-height: 100%; | |||
| height: 100%; | |||
| margin: 0; | |||
| background-color: white; | |||
| font-family: -apple-system,BlinkMacSystemFont,"Segoe UI",Roboto,Oxygen-Sans,Ubuntu,Cantarell,"Helvetica Neue",sans-serif; | |||
| } | |||
| body { | |||
| display: flex; | |||
| flex-direction: column; | |||
| counter-reset: theorem figure; | |||
| } | |||
| div#header { | |||
| background-color: $header; | |||
| height: $header-height; | |||
| display: flex; | |||
| flex-direction: row; | |||
| align-items: stretch; | |||
| justify-content: space-between; | |||
| flex-wrap: nowrap; | |||
| overflow-x: auto; | |||
| div#logo { | |||
| margin-left: .5em; | |||
| line-height: $header-height; | |||
| padding-left: .5em; | |||
| padding-right: .5em; | |||
| font-size: 18pt; | |||
| a { | |||
| color: $purple; | |||
| text-decoration: none; | |||
| } | |||
| transition: background-color .2s ease-in-out; | |||
| } | |||
| div#logo:hover { | |||
| background-color: darken($header, 10%); | |||
| } | |||
| div#navigation { | |||
| margin-right: .5em; | |||
| display: flex; | |||
| flex-direction: row; | |||
| align-items: stretch; | |||
| align-self: flex-end; | |||
| justify-content: flex-end; | |||
| line-height: $header-height; | |||
| a { | |||
| color: $purple; | |||
| text-decoration: none; | |||
| margin-left: .5em; | |||
| margin-right: .5em; | |||
| } | |||
| div.nav-button { | |||
| height: 100%; | |||
| transition: background-color .2s ease-in-out; | |||
| } | |||
| div.nav-button:hover { | |||
| background-color: darken($header, 10%); | |||
| } | |||
| } | |||
| } | |||
| div#content { | |||
| max-width: $max-width; | |||
| margin: 0px auto 0px auto; | |||
| flex: 1 0 auto; | |||
| span.katex, span.together { | |||
| display: inline-block; | |||
| } | |||
| p { | |||
| text-align: justify; | |||
| letter-spacing: 1.75; | |||
| code { | |||
| display: inline-block; | |||
| } | |||
| span.qed { | |||
| float: right; | |||
| } | |||
| span.theorem ::after { | |||
| counter-increment: theorem; | |||
| content: " " counter(theorem); | |||
| } | |||
| span.theorem, span.paragraph-marker { | |||
| font-style: italic; | |||
| } | |||
| } | |||
| p.image { | |||
| text-align: center !important; | |||
| } | |||
| h1 { | |||
| font-variant: small-caps; | |||
| max-width: 120ch; | |||
| } | |||
| blockquote { | |||
| background-color: $light-purple; | |||
| border-radius: 10px; | |||
| border: 1px solid $purple; | |||
| padding: 0em 1em; | |||
| } | |||
| > article > blockquote { | |||
| width: 80%; | |||
| margin: auto; | |||
| } | |||
| > article > div.code-container { | |||
| width: 80%; | |||
| margin: auto; | |||
| pre { | |||
| padding: 0px 1em; | |||
| } | |||
| > span { | |||
| display: inline; | |||
| } | |||
| } | |||
| div.code-container { | |||
| background-color: $light-purple; | |||
| border-radius: 10px; | |||
| border: 1px solid darken($light-purple, 10%); | |||
| overflow-x: auto; | |||
| > span { | |||
| padding: 0.5em 1em 0.25em 1em; | |||
| background-color: darken($light-purple, 10%); | |||
| border-top-left-radius: 10px; | |||
| box-shadow: 1px 1px darken($light-purple, 20%); | |||
| display: none; | |||
| } | |||
| > span::after { | |||
| content: " code"; | |||
| } | |||
| div.sourceCode { | |||
| padding: 0px .5em; | |||
| } | |||
| } | |||
| div.code-container.custom-tag { | |||
| > span::after { | |||
| display: none; | |||
| } | |||
| } | |||
| div.code-container.continues { | |||
| > span { | |||
| display: none; | |||
| } | |||
| } | |||
| * { | |||
| max-width: 100%; | |||
| } | |||
| details { | |||
| summary { | |||
| margin-left: 1em; | |||
| font-size: 14pt; | |||
| padding: .2em 1em; | |||
| } | |||
| border-radius: 5px; | |||
| border: 1px solid $purple; | |||
| padding: .2em 1em; | |||
| background-color: white; | |||
| font-size: 0pt; | |||
| margin-top: 0.5em; | |||
| margin-bottom: 0.5em; | |||
| transition: font-size 0.3s ease-in-out, background-color 0.3s ease-in-out; | |||
| transform: rotate3d(0, 0, 0, 0); | |||
| } | |||
| details[open] { | |||
| background-color: $light-purple; | |||
| font-size: 14pt; | |||
| } | |||
| .special-thanks { | |||
| display: flex; | |||
| flex-direction: column; | |||
| align-items: center; | |||
| justify-content: space-around; | |||
| p { | |||
| font-size: 21pt; | |||
| margin-top: .5em; | |||
| margin-bottom: 0px; | |||
| } | |||
| ul { | |||
| list-style: none; | |||
| li { | |||
| margin: .5em 0px; | |||
| border-radius: 10px; | |||
| border: 1px solid $purple; | |||
| background-color: $light-purple; | |||
| padding: 1em; | |||
| a { | |||
| text-decoration: underline; | |||
| } | |||
| transition: all 0.2s ease-in-out; | |||
| } | |||
| li:hover { | |||
| border-radius: 5px; | |||
| transform: scale(1.01); | |||
| background-color: lighten($light-purple, 5%); | |||
| } | |||
| } | |||
| } | |||
| .eqn-list { | |||
| list-style: none; | |||
| direction: rtl; | |||
| counter-reset: equation; | |||
| li { | |||
| counter-increment: equation; | |||
| span.katex-display { | |||
| margin: 2px; | |||
| } | |||
| * { | |||
| direction: ltr; | |||
| } | |||
| } | |||
| li::marker { | |||
| content: "(" counter(equation) ")"; | |||
| font-family: KaTeX_Main, Times New Roman, serif; | |||
| } | |||
| } | |||
| font-size: 14pt; | |||
| line-height: 1.6; | |||
| } | |||
| div.info, span#reading-length { | |||
| padding-left: 1em; | |||
| font-style: italic; | |||
| } | |||
| span#reading-length::before { | |||
| content: "Word count: " | |||
| } | |||
| div#footer { | |||
| display: flex; | |||
| align-items: center; | |||
| justify-content: space-between; | |||
| padding-left: 1em; | |||
| padding-right: 1em; | |||
| background-color: $light-purple; | |||
| } | |||
| .definition { | |||
| text-decoration: dotted underline; | |||
| } | |||
| .post-list { | |||
| list-style: none; | |||
| padding: 0px; | |||
| div.post-list-item { | |||
| margin-top: .2em; | |||
| margin-bottom: .2em; | |||
| padding: 1em; | |||
| border-radius: 10px; | |||
| background-color: $light-purple; | |||
| display: flex; | |||
| justify-content: space-between; | |||
| flex-wrap: wrap; | |||
| align-items: flex-end; | |||
| font-size: 11pt; | |||
| a { | |||
| font-size: 14pt; | |||
| padding-right: 2em; | |||
| } | |||
| } | |||
| } | |||
| table { | |||
| margin: auto; | |||
| border-collapse: collapse; | |||
| td, th { | |||
| border: 1px solid $purple; | |||
| text-align: center; | |||
| padding: 0px 1em 0px 1em; | |||
| > * { | |||
| vertical-align: middle; | |||
| } | |||
| } | |||
| td.image { | |||
| padding: 0px; | |||
| img { | |||
| margin-top: auto; | |||
| } | |||
| } | |||
| } | |||
| figure { | |||
| width: 100%; | |||
| margin: auto; | |||
| display: flex; | |||
| flex-direction: column; | |||
| align-items: center; | |||
| justify-content: space-around; | |||
| div { | |||
| width: 100%; | |||
| overflow-x: auto; | |||
| } | |||
| figcaption { | |||
| font-size: 14pt; | |||
| } | |||
| figcaption::before { | |||
| counter-increment: figure; | |||
| content: "Figure " counter(figure) ". "; | |||
| } | |||
| } | |||
| @media only screen and (max-width: $max-width) { | |||
| div#content { | |||
| margin-left: 1em; | |||
| margin-right: 1em; | |||
| } | |||
| .mathpar { | |||
| overflow-x: auto; | |||
| justify-content: space-evenly; | |||
| > * { | |||
| margin-left: .2em; | |||
| margin-right: .2em; | |||
| flex-shrink: 0; | |||
| flex-grow: 0; | |||
| } | |||
| } | |||
| } | |||
| // Contact page | |||
| .contact-list { | |||
| display: flex; | |||
| flex-direction: row; | |||
| flex-wrap: wrap; | |||
| justify-content: space-around; | |||
| align-items: center; | |||
| .contact-card { | |||
| margin: 0px .5em; | |||
| border: 1px solid $purple; | |||
| border-radius: 10px; | |||
| background-color: $blonde; | |||
| padding: 0px 1em; | |||
| .username, .username * { | |||
| font-size: 21pt; | |||
| color: $purple; | |||
| } | |||
| p { | |||
| display: flex; | |||
| align-items: center; | |||
| justify-content: space-evenly; | |||
| max-width: 40ch !important; | |||
| } | |||
| transition: all 0.2s ease-in-out; | |||
| } | |||
| .contact-card:hover { | |||
| margin: 0px .55em; | |||
| background-color: darken($blonde, 10%); | |||
| border-radius: 5px; | |||
| transform: scale(1.01); | |||
| } | |||
| } | |||
| @font-face { | |||
| font-family: 'Fantasque Sans Mono'; | |||
| src: url('fonts/FantasqueSansMono-Regular.woff2') format('woff2'); | |||
| font-weight: 400; | |||
| font-style: normal; | |||
| } | |||
+ 1
- 0
css/katex.min.css
File diff suppressed because it is too large
View File
+ 15
- 0
diagrams/cc/delimcc.tex
View File
| @ -0,0 +1,15 @@ | |||
| \begin{scope}[node distance=0.75cm] | |||
| \node (Stk0) [draw, shape=rectangle, minimum width=1.5cm, minimum height=0.75cm, anchor=center] | |||
| at (-2.75, 0) {shift}; | |||
| \node (Stk1) [draw, shape=rectangle, minimum width=1.5cm, minimum height=0.75cm, anchor=center] | |||
| at (-2.75, -0.75) {foo}; | |||
| \node (Stk2) [draw, shape=rectangle, minimum width=1.5cm, minimum height=0.75cm, anchor=center] | |||
| at (-2.75, -1.5) {bar}; | |||
| \node (Stk3) [draw, shape=rectangle, minimum width=1.5cm, minimum height=0.75cm, anchor=center] | |||
| at (-2.75, -2.25) {reset}; | |||
| \node (Stk3) [draw, shape=rectangle, minimum width=1.5cm, minimum height=0.75cm, anchor=center] | |||
| at (-2.75, -3) {baz}; | |||
| \draw [red, very thick, dashed] (-3.6, -2.625) -- (-1.89, -2.625) -- (-1.89, 0.375) -- (-3.6, 0.375) -- cycle; | |||
| \draw [arrows={Latex}-] (-4, 0.375) -- (-4, -3.375); | |||
| \end{scope} | |||
+ 1
- 0
diagrams/eq/0cube.tex
View File
| @ -0,0 +1 @@ | |||
| \node[draw,circle,label=right:$A$,fill,outer sep=0.1cm, inner sep=0pt, minimum size=0.1cm] (i0) at (0, 0) {}; | |||
+ 4
- 0
diagrams/eq/1cube.tex
View File
| @ -0,0 +1,4 @@ | |||
| \node[draw,circle,label=left:{$A[0/i]$},fill,outer sep=0.1cm, inner sep=0pt, minimum size=0.1cm] (i0) at (-1, 0) {}; | |||
| \node[draw,circle,label=right:{$A[1/i]$},fill,outer sep=0.1cm, inner sep=0pt, minimum size=0.1cm] (i1) at (1, 0) {}; | |||
| \draw (i0) -- (i1); | |||
+ 6
- 0
diagrams/eq/2cube.tex
View File
| @ -0,0 +1,6 @@ | |||
| \node[draw,circle,label=left:{$A[0/i, 0/j]$},fill,outer sep=0.1cm, inner sep=0pt, minimum size=0.1cm] (i0j0) at (-1, -1) {}; | |||
| \node[draw,circle,label=right:{$A[1/i, 0/j]$},fill,outer sep=0.1cm, inner sep=0pt, minimum size=0.1cm] (i1j0) at (1, -1) {}; | |||
| \node[draw,circle,label=left:{$A[0/i, 1/j]$},fill,outer sep=0.1cm, inner sep=0pt, minimum size=0.1cm] (i0j1) at (-1, 1) {}; | |||
| \node[draw,circle,label=right:{$A[1/i, 1/j]$},fill,outer sep=0.1cm, inner sep=0pt, minimum size=0.1cm] (i1j1) at (1, 1) {}; | |||
| \draw (i0j0) -- (i1j0) -- (i1j1) -- (i0j1) -- (i0j0); | |||
+ 5
- 0
diagrams/eq/interval.tex
View File
| @ -0,0 +1,5 @@ | |||
| \node[draw,circle,label=below:$i_0$,fill,outer sep=0.1cm, inner sep=0pt, minimum size=0.1cm] (i0) at (-1, 0) {}; | |||
| \node[draw,circle,label=below:$i_1$,fill,outer sep=0.1cm, inner sep=0pt, minimum size=0.1cm] (i1) at (1, 0) {}; | |||
| \draw (i0) -- (i1) node [midway, above] (seg) {seg}; | |||
| % \draw[-] (i0) -- (i1); | |||
+ 39
- 0
diagrams/gm/app_gx.tex
View File
| @ -0,0 +1,39 @@ | |||
| \begin{scope}[node distance=0.75cm] | |||
| \node (FGX) [inner xsep=0.01cm, inner ysep=0.03cm] at (0, 0) {@}; | |||
| \node (FG) [xshift=0.25cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=FGX, left of=FGX] {@}; | |||
| \node (X) [xshift=-0.25cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=FGX, right of=FGX] {x}; | |||
| \node (F) [xshift=0.25cm, inner xsep=0.04cm, inner ysep=0.05cm, below of=FG, left of=FG, xshift=2] {f}; | |||
| \node (G) [xshift=-0.25cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=FG, right of=FG, xshift=-2] {g}; | |||
| \node (GX) | |||
| [xshift=-0.25cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=F, xshift=0.75cm] | |||
| {@}; | |||
| \draw[->] (FGX) to (X); | |||
| \draw[->] (FGX) to (FG); | |||
| \draw[->] (FG) to (F.north east); | |||
| \draw[->] (FG) to (G.north west); | |||
| \draw[->] (GX) to ([shift=({-0.35cm,-0.35cm})]GX) | |||
| -- ++(0, -0.10cm) | |||
| -| (G); | |||
| \draw[->] (GX) to ([shift=({0.45cm,-0.35cm})]GX) | |||
| -| (X); | |||
| \node (Stk0) [draw, shape=rectangle, minimum width=1.5cm, minimum height=0.75cm, anchor=center] | |||
| at (-2.75, 0) {}; | |||
| \node (Stk1) [draw, shape=rectangle, minimum width=1.5cm, minimum height=0.75cm, anchor=center] | |||
| at (-2.75, -0.75) {}; | |||
| \node (Stk2) [draw, shape=rectangle, minimum width=1.5cm, minimum height=0.75cm, anchor=center] | |||
| at (-2.75, -1.5) {}; | |||
| \node (Stk3) [draw, shape=rectangle, minimum width=1.5cm, minimum height=0.75cm, anchor=center] | |||
| at (-2.75, -2.25) {}; | |||
| \draw[->] (Stk0.center) to (FGX); | |||
| \draw[->] (Stk1.center) to (FG); | |||
| \draw[->] (Stk2.center) to (F); | |||
| \draw[->] (Stk3.center) to (GX); | |||
| \end{scope} | |||
+ 51
- 0
diagrams/gm/app_kgx.tex
View File
| @ -0,0 +1,51 @@ | |||
| \begin{scope}[node distance=0.75cm] | |||
| \node (FGX) [inner xsep=0.01cm, inner ysep=0.03cm] at (0, 0) {@}; | |||
| \node (FG) [xshift=0.25cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=FGX, left of=FGX] {@}; | |||
| \node (X) [xshift=-0.25cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=FGX, right of=FGX] {x}; | |||
| \node (F) [xshift=0.25cm, inner xsep=0.04cm, inner ysep=0.05cm, below of=FG, left of=FG, xshift=2] {f}; | |||
| \node (G) [xshift=-0.25cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=FG, right of=FG, xshift=-2] {g}; | |||
| \node (KGX) | |||
| [xshift=-0.55cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=F, xshift=0.75cm] | |||
| {@}; | |||
| \node (K) | |||
| [xshift=0.25cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=KGX, left of=KGX] | |||
| {K}; | |||
| \node (GX) | |||
| [xshift=-0.45cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=KGX, right of=KGX] | |||
| {@}; | |||
| \draw[->] (FGX) to (X); | |||
| \draw[->] (FGX) to (FG); | |||
| \draw[->] (FG) to (F.north east); | |||
| \draw[->] (FG) to (G.north west); | |||
| \draw[->] (KGX) to (K); | |||
| \draw[->] (KGX) to (GX); | |||
| \draw[->] (GX) to ([shift=({-0.35cm,-0.35cm})]GX) | |||
| -- ++(0, -0.10cm) | |||
| -| (G); | |||
| \draw[->] (GX) to ([shift=({0.45cm,-0.35cm})]GX) | |||
| -| (X); | |||
| \node (Stk0) [draw, shape=rectangle, minimum width=1.5cm, minimum height=0.75cm, anchor=center] | |||
| at (-2.75, 0) {}; | |||
| \node (Stk1) [draw, shape=rectangle, minimum width=1.5cm, minimum height=0.75cm, anchor=center] | |||
| at (-2.75, -0.75) {}; | |||
| \node (Stk2) [draw, shape=rectangle, minimum width=1.5cm, minimum height=0.75cm, anchor=center] | |||
| at (-2.75, -1.5) {}; | |||
| \node (Stk3) [draw, shape=rectangle, minimum width=1.5cm, minimum height=0.75cm, anchor=center] | |||
| at (-2.75, -2.25) {}; | |||
| \draw[->] (Stk0.center) to (FGX); | |||
| \draw[->] (Stk1.center) to (FG); | |||
| \draw[->] (Stk2.center) to (F); | |||
| \draw[->] (Stk3.center) to (KGX); | |||
| \end{scope} | |||
+ 25
- 0
diagrams/gm/entry.tex
View File
| @ -0,0 +1,25 @@ | |||
| \begin{scope}[node distance=0.75cm] | |||
| \node (FGX) [inner xsep=0.01cm, inner ysep=0.03cm] at (0, 0) {@}; | |||
| \node (FG) [xshift=0.25cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=FGX, left of=FGX] {@}; | |||
| \node (X) [xshift=-0.25cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=FGX, right of=FGX] {x}; | |||
| \node (F) [xshift=0.25cm, inner xsep=0.04cm, inner ysep=0.05cm, below of=FG, left of=FG, xshift=2] {f}; | |||
| \node (G) [xshift=-0.25cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=FG, right of=FG, xshift=-2] {g}; | |||
| \draw[->] (FGX) to (X); | |||
| \draw[->] (FGX) to (FG); | |||
| \draw[->] (FG) to (F.north east); | |||
| \draw[->] (FG) to (G.north west); | |||
| \node (Stk0) [draw, shape=rectangle, minimum width=1.5cm, minimum height=0.75cm, anchor=center] | |||
| at (-2.75, 0) {}; | |||
| \node (Stk1) [draw, shape=rectangle, minimum width=1.5cm, minimum height=0.75cm, anchor=center] | |||
| at (-2.75, -0.75) {}; | |||
| \node (Stk2) [draw, shape=rectangle, minimum width=1.5cm, minimum height=0.75cm, anchor=center] | |||
| at (-2.75, -1.5) {}; | |||
| \draw[->] (Stk0.center) to (FGX); | |||
| \draw[->] (Stk1.center) to (FG); | |||
| \draw[->] (Stk2.center) to (F); | |||
| \end{scope} | |||
+ 31
- 0
diagrams/gm/push_g.tex
View File
| @ -0,0 +1,31 @@ | |||
| \begin{scope}[node distance=0.75cm] | |||
| \node (FGX) [inner xsep=0.01cm, inner ysep=0.03cm] at (0, 0) {@}; | |||
| \node (FG) [xshift=0.25cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=FGX, left of=FGX] {@}; | |||
| \node (X) [xshift=-0.25cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=FGX, right of=FGX] {x}; | |||
| \node (F) [xshift=0.25cm, inner xsep=0.04cm, inner ysep=0.05cm, below of=FG, left of=FG, xshift=2] {f}; | |||
| \node (G) [xshift=-0.25cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=FG, right of=FG, xshift=-2] {g}; | |||
| \draw[->] (FGX) to (X); | |||
| \draw[->] (FGX) to (FG); | |||
| \draw[->] (FG) to (F.north east); | |||
| \draw[->] (FG) to (G.north west); | |||
| \node (Stk0) [draw, shape=rectangle, minimum width=1.5cm, minimum height=0.75cm, anchor=center] | |||
| at (-2.75, 0) {}; | |||
| \node (Stk1) [draw, shape=rectangle, minimum width=1.5cm, minimum height=0.75cm, anchor=center] | |||
| at (-2.75, -0.75) {}; | |||
| \node (Stk2) [draw, shape=rectangle, minimum width=1.5cm, minimum height=0.75cm, anchor=center] | |||
| at (-2.75, -1.5) {}; | |||
| \node (Stk3) [draw, shape=rectangle, minimum width=1.5cm, minimum height=0.75cm, anchor=center] | |||
| at (-2.75, -2.25) {}; | |||
| \node (Stk4) [draw, shape=rectangle, minimum width=1.5cm, minimum height=0.75cm, anchor=center] | |||
| at (-2.75, -3) {}; | |||
| \draw[->] (Stk0.center) to (FGX); | |||
| \draw[->] (Stk1.center) to (FG); | |||
| \draw[->] (Stk2.center) to (F); | |||
| \draw[->] (Stk3.center) to (X |- 0, -2.25cm) -- (X); | |||
| \draw[->] (Stk4.center) to (G |- 0, -3cm) -- (G); | |||
| \end{scope} | |||
+ 44
- 0
diagrams/gm/push_k.tex
View File
| @ -0,0 +1,44 @@ | |||
| \begin{scope}[node distance=0.75cm] | |||
| \node (FGX) [inner xsep=0.01cm, inner ysep=0.03cm] at (0, 0) {@}; | |||
| \node (FG) [xshift=0.25cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=FGX, left of=FGX] {@}; | |||
| \node (X) [xshift=-0.25cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=FGX, right of=FGX] {x}; | |||
| \node (F) [xshift=0.25cm, inner xsep=0.04cm, inner ysep=0.05cm, below of=FG, left of=FG, xshift=2] {f}; | |||
| \node (G) [xshift=-0.25cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=FG, right of=FG, xshift=-2] {g}; | |||
| \node (GX) | |||
| [xshift=-0.25cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=F, xshift=0.75cm] | |||
| {@}; | |||
| \draw[->] (FGX) to (X); | |||
| \draw[->] (FGX) to (FG); | |||
| \draw[->] (FG) to (F.north east); | |||
| \draw[->] (FG) to (G.north west); | |||
| \draw[->] (GX) to ([shift=({-0.35cm,-0.35cm})]GX) | |||
| -- ++(0, -0.10cm) | |||
| -| (G); | |||
| \draw[->] (GX) to ([shift=({0.45cm,-0.35cm})]GX) | |||
| -| (X); | |||
| \node (Stk0) [draw, shape=rectangle, minimum width=1.5cm, minimum height=0.75cm, anchor=center] | |||
| at (-2.75, 0) {}; | |||
| \node (Stk1) [draw, shape=rectangle, minimum width=1.5cm, minimum height=0.75cm, anchor=center] | |||
| at (-2.75, -0.75) {}; | |||
| \node (Stk2) [draw, shape=rectangle, minimum width=1.5cm, minimum height=0.75cm, anchor=center] | |||
| at (-2.75, -1.5) {}; | |||
| \node (Stk3) [draw, shape=rectangle, minimum width=1.5cm, minimum height=0.75cm, anchor=center] | |||
| at (-2.75, -2.25) {}; | |||
| \node (Stk4) [draw, shape=rectangle, minimum width=1.5cm, minimum height=0.75cm, anchor=center] | |||
| at (-2.75, -3) {}; | |||
| \node (K) [right of=Stk4, xshift=1.5cm] {K}; | |||
| \draw[->] (Stk0.center) to (FGX); | |||
| \draw[->] (Stk1.center) to (FG); | |||
| \draw[->] (Stk2.center) to (F); | |||
| \draw[->] (Stk3.center) to (GX); | |||
| \draw[->] (Stk4.center) to (K); | |||
| \end{scope} | |||
+ 33
- 0
diagrams/gm/push_x.tex
View File
| @ -0,0 +1,33 @@ | |||
| \begin{scope}[node distance=0.75cm] | |||
| \node (FGX) [inner xsep=0.01cm, inner ysep=0.03cm] | |||
| at (0, 0) {@}; | |||
| \node (FG) [xshift=0.25cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=FGX, left of=FGX] | |||
| {@}; | |||
| \node (X) [xshift=-0.25cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=FGX, right of=FGX] | |||
| {x}; | |||
| \node (F) [xshift=0.25cm, inner xsep=0.04cm, inner ysep=0.05cm, below of=FG, left of=FG, xshift=2] | |||
| {f}; | |||
| \node (G) [xshift=-0.25cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=FG, right of=FG, xshift=-2] | |||
| {g}; | |||
| \draw[->] (FGX) to (X); | |||
| \draw[->] (FGX) to (FG); | |||
| \draw[->] (FG) to (F.north east); | |||
| \draw[->] (FG) to (G.north west); | |||
| \node (Stk0) [draw, shape=rectangle, minimum width=1.5cm, minimum height=0.75cm, anchor=center] | |||
| at (-2.75, 0) {}; | |||
| \node (Stk1) [draw, shape=rectangle, minimum width=1.5cm, minimum height=0.75cm, anchor=center] | |||
| at (-2.75, -0.75) {}; | |||
| \node (Stk2) [draw, shape=rectangle, minimum width=1.5cm, minimum height=0.75cm, anchor=center] | |||
| at (-2.75, -1.5) {}; | |||
| \node (Stk3) [draw, shape=rectangle, minimum width=1.5cm, minimum height=0.75cm, anchor=center] | |||
| at (-2.75, -2.25) {}; | |||
| \draw[->] (Stk0.center) to (FGX); | |||
| \draw[->] (Stk1.center) to (FG); | |||
| \draw[->] (Stk2.center) to (F); | |||
| \draw[->] (Stk3.center) to (0.5cm, -2.25cm) -- (X); | |||
| \end{scope} | |||
+ 34
- 0
diagrams/gm/slide_3.tex
View File
| @ -0,0 +1,34 @@ | |||
| \begin{scope}[node distance=0.75cm] | |||
| \node (KGX) | |||
| [xshift=-0.55cm, inner xsep=0.01cm, inner ysep=0.03cm] | |||
| at (0, 0) {@}; | |||
| \node (K) | |||
| [xshift=0.25cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=KGX, left of=KGX] | |||
| {K}; | |||
| \node (GX) | |||
| [xshift=-0.45cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=KGX, right of=KGX] | |||
| {@}; | |||
| \node (G) | |||
| [xshift=0.45cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=GX, left of=GX] | |||
| {g}; | |||
| \node (X) | |||
| [xshift=-0.45cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=GX, right of=GX] | |||
| {x}; | |||
| \draw[->] (KGX) to (K); | |||
| \draw[->] (KGX) to (GX); | |||
| \draw[->] (GX) to (G); | |||
| \draw[->] (GX) to (X); | |||
| \node (Stk0) [draw, shape=rectangle, minimum width=1.5cm, minimum height=0.75cm, anchor=center] | |||
| at (-2.75, 0) {}; | |||
| \draw[->] (Stk0.center) to (KGX); | |||
| \end{scope} | |||
+ 25
- 0
diagrams/gm/spine+stack.tex
View File
| @ -0,0 +1,25 @@ | |||
| \begin{scope}[node distance=0.75cm] | |||
| \node (FGX) [color=blue,inner xsep=0.01cm, inner ysep=0.03cm] at (0, 0) {@}; | |||
| \node (FG) [color=blue,xshift=0.25cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=FGX, left of=FGX] {@}; | |||
| \node (X) [xshift=-0.25cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=FGX, right of=FGX] {y}; | |||
| \node (F) [color=blue,xshift=0.25cm, inner xsep=0.04cm, inner ysep=0.05cm, below of=FG, left of=FG, xshift=2] {f}; | |||
| \node (G) [xshift=-0.25cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=FG, right of=FG, xshift=-2] {x}; | |||
| \draw[->] (FGX) to (X); | |||
| \draw[->,color=blue] (FGX) to (FG); | |||
| \draw[->,color=blue] (FG) to (F.north east); | |||
| \draw[->] (FG) to (G.north west); | |||
| \node (Stk0) [draw, shape=rectangle, minimum width=1.5cm, minimum height=0.75cm, anchor=center] | |||
| at (-2.75, 0) {}; | |||
| \node (Stk1) [draw, shape=rectangle, minimum width=1.5cm, minimum height=0.75cm, anchor=center] | |||
| at (-2.75, -0.75) {}; | |||
| \node (Stk2) [draw, shape=rectangle, minimum width=1.5cm, minimum height=0.75cm, anchor=center] | |||
| at (-2.75, -1.5) {}; | |||
| \draw[->] (Stk0.center) to (FGX); | |||
| \draw[->] (Stk1.center) to (FG); | |||
| \draw[->] (Stk2.center) to (F); | |||
| \end{scope} | |||
+ 14
- 0
diagrams/gm/spine.tex
View File
| @ -0,0 +1,14 @@ | |||
| \begin{scope}[node distance=0.75cm] | |||
| \node (FGX) [color=blue,inner xsep=0.01cm, inner ysep=0.03cm] at (0, 0) {@}; | |||
| \node (FG) [color=blue,xshift=0.25cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=FGX, left of=FGX] {@}; | |||
| \node (X) [xshift=-0.25cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=FGX, right of=FGX] {y}; | |||
| \node (F) [color=blue,xshift=0.25cm, inner xsep=0.04cm, inner ysep=0.05cm, below of=FG, left of=FG, xshift=2] {f}; | |||
| \node (G) [xshift=-0.25cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=FG, right of=FG, xshift=-2] {x}; | |||
| \draw[->] (FGX) to (X); | |||
| \draw[->,color=blue] (FGX) to (FG); | |||
| \draw[->,color=blue] (FG) to (F.north east); | |||
| \draw[->] (FG) to (G.north west); | |||
| \end{scope} | |||
+ 1
- 0
diagrams/template/step1.tex
View File
| @ -0,0 +1 @@ | |||
| \node at (0, 0) {main}; | |||
+ 26
- 0
diagrams/template/step2.tex
View File
| @ -0,0 +1,26 @@ | |||
| \begin{scope}[node distance=0.75cm] | |||
| \node (DoDo4) [inner xsep=0.01cm, inner ysep=0.03cm] at (0, 0) {@}; | |||
| \node (Do) | |||
| [xshift=0.25cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=DoDo4, left of=DoDo4] | |||
| {double}; | |||
| \node (Do4) | |||
| [xshift=-0.25cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=DoDo4, right of=DoDo4] | |||
| {@}; | |||
| \node (Do_2) | |||
| [xshift=0.25cm, inner xsep=0.04cm, inner ysep=0.05cm, below of=Do4, left of=Do4, xshift=2] | |||
| {double}; | |||
| \node (4) | |||
| [xshift=-0.25cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=Do4, right of=Do4, xshift=-2] | |||
| {4}; | |||
| \draw[->] (DoDo4) to (Do); | |||
| \draw[->] (DoDo4) to (Do4); | |||
| \draw[->] (Do4) to (Do_2); | |||
| \draw[->] (Do4) to (4); | |||
| \end{scope} | |||
+ 33
- 0
diagrams/template/step3.tex
View File
| @ -0,0 +1,33 @@ | |||
| \begin{scope}[node distance=0.75cm] | |||
| \node (DoDo4) [inner xsep=0.01cm, inner ysep=0.03cm] at (0, 0) {@}; | |||
| \node (TimesAp) | |||
| [xshift=0.25cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=DoDo4, left of=DoDo4] | |||
| {@}; | |||
| \node (Times) | |||
| [xshift=0.25cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=TimesAp, left of=TimesAp] | |||
| {$+$}; | |||
| \node (Do4) | |||
| [xshift=-0.5cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=DoDo4, | |||
| right of=DoDo4, yshift=-0.5cm] | |||
| {@}; | |||
| \node (Do_2) | |||
| [xshift=0.25cm, inner xsep=0.04cm, inner ysep=0.05cm, below of=Do4, left of=Do4, xshift=2] | |||
| {double}; | |||
| \node (4) | |||
| [xshift=-0.25cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=Do4, right of=Do4, xshift=-2] | |||
| {4}; | |||
| \draw[->] (DoDo4) to (TimesAp); | |||
| \draw[->] (TimesAp) to (Times); | |||
| \draw[->] (TimesAp) |- (Do4); | |||
| \draw[->] (DoDo4) to (Do4); | |||
| \draw[->] (Do4) to (Do_2); | |||
| \draw[->] (Do4) to (4); | |||
| \end{scope} | |||
+ 38
- 0
diagrams/template/step4.tex
View File
| @ -0,0 +1,38 @@ | |||
| \begin{scope}[node distance=0.75cm] | |||
| \node (DoDo4) [inner xsep=0.01cm, inner ysep=0.03cm] at (0, 0) {@}; | |||
| \node (TimesAp) | |||
| [xshift=0.25cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=DoDo4, left of=DoDo4] | |||
| {@}; | |||
| \node (Times) | |||
| [xshift=0.25cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=TimesAp, left of=TimesAp] | |||
| {$+$}; | |||
| \node (Times44) | |||
| [xshift=-0.5cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=DoDo4, right of=DoDo4, yshift=-0.5cm] | |||
| {@}; | |||
| \node (4) | |||
| [xshift=-0.25cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=Times44, right of=Times44, yshift=-0.75cm] | |||
| {4}; | |||
| \node (Times4) | |||
| [xshift=0.25cm, inner xsep=0.04cm, inner ysep=0.05cm, below of=Times44, left of=Times44, xshift=2] | |||
| {@}; | |||
| \node (Times2) | |||
| [xshift=0.25cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=Times4, left of=Times4] | |||
| {$+$}; | |||
| \draw[->] (DoDo4) to (TimesAp); | |||
| \draw[->] (TimesAp) to (Times); | |||
| \draw[->] (TimesAp) to (Times44); | |||
| \draw[->] (DoDo4) to (Times44); | |||
| \draw[->] (Times44) to (Times4); | |||
| \draw[->] (Times4) to (Times2); | |||
| \draw[->] (Times4) |- (4); | |||
| \draw[->] (Times44) to (4); | |||
| \end{scope} | |||
+ 38
- 0
diagrams/template/step4red.tex
View File
| @ -0,0 +1,38 @@ | |||
| \begin{scope}[node distance=0.75cm] | |||
| \node (DoDo4) [inner xsep=0.01cm, inner ysep=0.03cm] at (0, 0) {@}; | |||
| \node (TimesAp) | |||
| [xshift=0.25cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=DoDo4, left of=DoDo4] | |||
| {@}; | |||
| \node (Times) | |||
| [xshift=0.25cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=TimesAp, left of=TimesAp] | |||
| {$+$}; | |||
| \node (Times44) | |||
| [xshift=-0.5cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=DoDo4, right of=DoDo4, yshift=-0.5cm, color=blue] | |||
| {@}; | |||
| \node (4) | |||
| [xshift=-0.25cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=Times44, right of=Times44, yshift=-0.75cm, color=blue] | |||
| {4}; | |||
| \node (Times4) | |||
| [xshift=0.25cm, inner xsep=0.04cm, inner ysep=0.05cm, below of=Times44, left of=Times44, xshift=2, color=blue] | |||
| {@}; | |||
| \node (Times2) | |||
| [xshift=0.25cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=Times4, left of=Times4, color=blue] | |||
| {$+$}; | |||
| \draw[->] (DoDo4) to (TimesAp); | |||
| \draw[->] (TimesAp) to (Times); | |||
| \draw[->] (TimesAp) to (Times44); | |||
| \draw[->] (DoDo4) to (Times44); | |||
| \draw[->,color=blue,dashed] (Times44) to (Times4); | |||
| \draw[->,color=blue,dashed] (Times4) to (Times2); | |||
| \draw[->,color=blue,dashed] (Times4) |- (4); | |||
| \draw[->,color=blue,dashed] (Times44) to (4); | |||
| \end{scope} | |||
+ 22
- 0
diagrams/template/step5.tex
View File
| @ -0,0 +1,22 @@ | |||
| \begin{scope}[node distance=0.75cm] | |||
| \node (DoDo4) [inner xsep=0.01cm, inner ysep=0.03cm] at (0, 0) {@}; | |||
| \node (TimesAp) | |||
| [xshift=0.25cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=DoDo4, left of=DoDo4] | |||
| {@}; | |||
| \node (Times) | |||
| [xshift=0.25cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=TimesAp, left of=TimesAp] | |||
| {$+$}; | |||
| \node (8) | |||
| [xshift=-0.5cm, inner xsep=0.01cm, inner ysep=0.03cm, below of=DoDo4, right of=DoDo4, yshift=-0.75cm] | |||
| {8}; | |||
| \draw[->] (DoDo4) to (TimesAp); | |||
| \draw[->] (TimesAp) to (Times); | |||
| \draw[->] (TimesAp) |- (8); | |||
| \draw[->] (DoDo4) to (8); | |||
| \end{scope} | |||
+ 2
- 0
hie.yaml
View File
| @ -0,0 +1,2 @@ | |||
| cradle: | |||
| stack: | |||
+ 140
- 0
package-lock.json
View File
| @ -0,0 +1,140 @@ | |||
| { | |||
| "name": "blag", | |||
| "version": "1.0.0", | |||
| "lockfileVersion": 1, | |||
| "requires": true, | |||
| "dependencies": { | |||
| "anymatch": { | |||
| "version": "3.1.1", | |||
| "resolved": "https://registry.npmjs.org/anymatch/-/anymatch-3.1.1.tgz", | |||
| "integrity": "sha512-mM8522psRCqzV+6LhomX5wgp25YVibjh8Wj23I5RPkPppSVSjyKD2A2mBJmWGa+KN7f2D6LNh9jkBCeyLktzjg==", | |||
| "requires": { | |||
| "normalize-path": "^3.0.0", | |||
| "picomatch": "^2.0.4" | |||
| } | |||
| }, | |||
| "binary-extensions": { | |||
| "version": "2.1.0", | |||
| "resolved": "https://registry.npmjs.org/binary-extensions/-/binary-extensions-2.1.0.tgz", | |||
| "integrity": "sha512-1Yj8h9Q+QDF5FzhMs/c9+6UntbD5MkRfRwac8DoEm9ZfUBZ7tZ55YcGVAzEe4bXsdQHEk+s9S5wsOKVdZrw0tQ==" | |||
| }, | |||
| "braces": { | |||
| "version": "3.0.2", | |||
| "resolved": "https://registry.npmjs.org/braces/-/braces-3.0.2.tgz", | |||
| "integrity": "sha512-b8um+L1RzM3WDSzvhm6gIz1yfTbBt6YTlcEKAvsmqCZZFw46z626lVj9j1yEPW33H5H+lBQpZMP1k8l+78Ha0A==", | |||
| "requires": { | |||
| "fill-range": "^7.0.1" | |||
| } | |||
| }, | |||
| "chokidar": { | |||
| "version": "3.4.3", | |||
| "resolved": "https://registry.npmjs.org/chokidar/-/chokidar-3.4.3.tgz", | |||
| "integrity": "sha512-DtM3g7juCXQxFVSNPNByEC2+NImtBuxQQvWlHunpJIS5Ocr0lG306cC7FCi7cEA0fzmybPUIl4txBIobk1gGOQ==", | |||
| "requires": { | |||
| "anymatch": "~3.1.1", | |||
| "braces": "~3.0.2", | |||
| "fsevents": "~2.1.2", | |||
| "glob-parent": "~5.1.0", | |||
| "is-binary-path": "~2.1.0", | |||
| "is-glob": "~4.0.1", | |||
| "normalize-path": "~3.0.0", | |||
| "readdirp": "~3.5.0" | |||
| } | |||
| }, | |||
| "commander": { | |||
| "version": "2.20.3", | |||
| "resolved": "https://registry.npmjs.org/commander/-/commander-2.20.3.tgz", | |||
| "integrity": "sha512-GpVkmM8vF2vQUkj2LvZmD35JxeJOLCwJ9cUkugyk2nuhbv3+mJvpLYYt+0+USMxE+oj+ey/lJEnhZw75x/OMcQ==" | |||
| }, | |||
| "fill-range": { | |||
| "version": "7.0.1", | |||
| "resolved": "https://registry.npmjs.org/fill-range/-/fill-range-7.0.1.tgz", | |||
| "integrity": "sha512-qOo9F+dMUmC2Lcb4BbVvnKJxTPjCm+RRpe4gDuGrzkL7mEVl/djYSu2OdQ2Pa302N4oqkSg9ir6jaLWJ2USVpQ==", | |||
| "requires": { | |||
| "to-regex-range": "^5.0.1" | |||
| } | |||
| }, | |||
| "fsevents": { | |||
| "version": "2.1.3", | |||
| "resolved": "https://registry.npmjs.org/fsevents/-/fsevents-2.1.3.tgz", | |||
| "integrity": "sha512-Auw9a4AxqWpa9GUfj370BMPzzyncfBABW8Mab7BGWBYDj4Isgq+cDKtx0i6u9jcX9pQDnswsaaOTgTmA5pEjuQ==", | |||
| "optional": true | |||
| }, | |||
| "glob-parent": { | |||
| "version": "5.1.1", | |||
| "resolved": "https://registry.npmjs.org/glob-parent/-/glob-parent-5.1.1.tgz", | |||
| "integrity": "sha512-FnI+VGOpnlGHWZxthPGR+QhR78fuiK0sNLkHQv+bL9fQi57lNNdquIbna/WrfROrolq8GK5Ek6BiMwqL/voRYQ==", | |||
| "requires": { | |||
| "is-glob": "^4.0.1" | |||
| } | |||
| }, | |||
| "is-binary-path": { | |||
| "version": "2.1.0", | |||
| "resolved": "https://registry.npmjs.org/is-binary-path/-/is-binary-path-2.1.0.tgz", | |||
| "integrity": "sha512-ZMERYes6pDydyuGidse7OsHxtbI7WVeUEozgR/g7rd0xUimYNlvZRE/K2MgZTjWy725IfelLeVcEM97mmtRGXw==", | |||
| "requires": { | |||
| "binary-extensions": "^2.0.0" | |||
| } | |||
| }, | |||
| "is-extglob": { | |||
| "version": "2.1.1", | |||
| "resolved": "https://registry.npmjs.org/is-extglob/-/is-extglob-2.1.1.tgz", | |||
| "integrity": "sha1-qIwCU1eR8C7TfHahueqXc8gz+MI=" | |||
| }, | |||
| "is-glob": { | |||
| "version": "4.0.1", | |||
| "resolved": "https://registry.npmjs.org/is-glob/-/is-glob-4.0.1.tgz", | |||
| "integrity": "sha512-5G0tKtBTFImOqDnLB2hG6Bp2qcKEFduo4tZu9MT/H6NQv/ghhy30o55ufafxJ/LdH79LLs2Kfrn85TLKyA7BUg==", | |||
| "requires": { | |||
| "is-extglob": "^2.1.1" | |||
| } | |||
| }, | |||
| "is-number": { | |||
| "version": "7.0.0", | |||
| "resolved": "https://registry.npmjs.org/is-number/-/is-number-7.0.0.tgz", | |||
| "integrity": "sha512-41Cifkg6e8TylSpdtTpeLVMqvSBEVzTttHvERD741+pnZ8ANv0004MRL43QKPDlK9cGvNp6NZWZUBlbGXYxxng==" | |||
| }, | |||
| "katex": { | |||
| "version": "0.11.1", | |||
| "resolved": "https://registry.npmjs.org/katex/-/katex-0.11.1.tgz", | |||
| "integrity": "sha512-5oANDICCTX0NqYIyAiFCCwjQ7ERu3DQG2JFHLbYOf+fXaMoH8eg/zOq5WSYJsKMi/QebW+Eh3gSM+oss1H/bww==", | |||
| "requires": { | |||
| "commander": "^2.19.0" | |||
| } | |||
| }, | |||
| "normalize-path": { | |||
| "version": "3.0.0", | |||
| "resolved": "https://registry.npmjs.org/normalize-path/-/normalize-path-3.0.0.tgz", | |||
| "integrity": "sha512-6eZs5Ls3WtCisHWp9S2GUy8dqkpGi4BVSz3GaqiE6ezub0512ESztXUwUB6C6IKbQkY2Pnb/mD4WYojCRwcwLA==" | |||
| }, | |||
| "picomatch": { | |||
| "version": "2.2.2", | |||
| "resolved": "https://registry.npmjs.org/picomatch/-/picomatch-2.2.2.tgz", | |||
| "integrity": "sha512-q0M/9eZHzmr0AulXyPwNfZjtwZ/RBZlbN3K3CErVrk50T2ASYI7Bye0EvekFY3IP1Nt2DHu0re+V2ZHIpMkuWg==" | |||
| }, | |||
| "readdirp": { | |||
| "version": "3.5.0", | |||
| "resolved": "https://registry.npmjs.org/readdirp/-/readdirp-3.5.0.tgz", | |||
| "integrity": "sha512-cMhu7c/8rdhkHXWsY+osBhfSy0JikwpHK/5+imo+LpeasTF8ouErHrlYkwT0++njiyuDvc7OFY5T3ukvZ8qmFQ==", | |||
| "requires": { | |||
| "picomatch": "^2.2.1" | |||
| } | |||
| }, | |||
| "sass": { | |||
| "version": "1.28.0", | |||
| "resolved": "https://registry.npmjs.org/sass/-/sass-1.28.0.tgz", | |||
| "integrity": "sha512-9FWX/0wuE1KxwfiP02chZhHaPzu6adpx9+wGch7WMOuHy5npOo0UapRI3FNSHva2CczaYJu2yNUBN8cCSqHz/A==", | |||
| "requires": { | |||
| "chokidar": ">=2.0.0 <4.0.0" | |||
| } | |||
| }, | |||
| "to-regex-range": { | |||
| "version": "5.0.1", | |||
| "resolved": "https://registry.npmjs.org/to-regex-range/-/to-regex-range-5.0.1.tgz", | |||
| "integrity": "sha512-65P7iz6X5yEr1cwcgvQxbbIw7Uk3gOy5dIdtZ4rDveLqhrdJP+Li/Hx6tyK0NEb+2GCyneCMJiGqrADCSNk8sQ==", | |||
| "requires": { | |||
| "is-number": "^7.0.0" | |||
| } | |||
| } | |||
| } | |||
| } | |||
+ 21
- 0
package.json
View File
| @ -0,0 +1,21 @@ | |||
| { | |||
| "name": "blag", | |||
| "version": "1.0.0", | |||
| "description": "[Go here instead](https://abby.how)", | |||
| "main": "index.js", | |||
| "dependencies": { | |||
| "katex": "^0.11.1", | |||
| "sass": "^1.28.0" | |||
| }, | |||
| "devDependencies": {}, | |||
| "scripts": { | |||
| "up": "stack run -- build && stack run -- deploy", | |||
| "watch": "stack run -- watch" | |||
| }, | |||
| "repository": { | |||
| "type": "git", | |||
| "url": "[email protected]:plt-hokusai/blag.git" | |||
| }, | |||
| "author": "", | |||
| "license": "ISC" | |||
| } | |||
+ 35
- 0
pages/contact.md
View File
| @ -0,0 +1,35 @@ | |||
| --- | |||
| title: Contact | |||
| --- | |||
| Here are the easiest ways to reach me: | |||
| <style> | |||
| span#reading-length { display: none; } | |||
| </style> | |||
| <div class="contact-list"> | |||
| <div class="contact-card"> | |||
| <span class="username">@abby#4600</span> | |||
| My Discord friend requests are always open. Feel free to add me for questions or comments! | |||
| </div> | |||
| <div class="contact-card"> | |||
| <span class="username">{abby}</span> | |||
| <span> | |||
| Message me directly on <a href="https://webchat.freenode.net/">Freenode</a> IRC, or join `##dependent` to talk about types! | |||
| </span> | |||
| </div> | |||
| </div> | |||
| If you like what I do, here are some ways you can support this blog: | |||
| <div class="contact-list"> | |||
| <div class="contact-card"> | |||
| <span class="username"><a href="https://ko-fi.com/pltabby">Ko-fi</a></span> | |||
| You can send me a one-time donation on Ko-Fi. Just remember not to read the name on the receipt! | |||
| (Paypal sucks) | |||
| </div> | |||
| </div> | |||
+ 13
- 0
pages/index.html
View File
| @ -0,0 +1,13 @@ | |||
| --- | |||
| title: Home | |||
| --- | |||
| <p> | |||
| You've reached Abigail's blog, a place where I exposit and reflect on programming languages and type theory. | |||
| Here's the posts I've written recently: | |||
| </p> | |||
| <h2>Posts</h2> | |||
| $partial("templates/post-list.html")$ | |||
| <p>…or you can find more in the <a href="/archive.html">archives</a>.</p> | |||
+ 14
- 0
pages/oss.md
View File
| @ -0,0 +1,14 @@ | |||
| --- | |||
| title: Open-source Licenses | |||
| --- | |||
| <style> | |||
| span#reading-length { display: none; } | |||
| </style> | |||
| This blog redistributes (parts of) the following free software projects: | |||
| * **KaTeX** is a fast JavaScript library for rendering LaTeX on the client. I use it to pre-generate amazing looking mathematics at compile time. **KaTeX is licensed under the terms of the MIT license, with a copy available [here](/static/licenses/LICENSE.KaTeX)**. | |||
| * **Fantasque Sans Mono** is the programming font I've used for the past 3 years, including on this website. **Fantasque Sans Mono is distributed under the terms of the Open Font License (OFL), with a copy available [here](/static/licenses/LICENSE.FantasqueSansMono)**. | |||
+ 308
- 0
pages/posts/2016-08-17-parsec.md
View File
| @ -0,0 +1,308 @@ | |||
| --- | |||
| title: You could have invented Parsec | |||
| date: August 17, 2016 01:29 AM | |||
| --- | |||
| As most of us should know, [Parsec](https://hackage.haskell.org/package/parsec) | |||
| is a relatively fast, lightweight monadic parser combinator library. | |||
| In this post I aim to show that monadic parsing is not only useful, but a simple | |||
| concept to grok. | |||
| We shall implement a simple parsing library with instances of common typeclasses | |||
| of the domain, such as Monad, Functor and Applicative, and some example | |||
| combinators to show how powerful this abstraction really is. | |||
| --- | |||
| Getting the buzzwords out of the way, being _monadic_ just means that Parsers | |||
| instances of `Monad`{.haskell}. Recall the Monad typeclass, as defined in | |||
| `Control.Monad`{.haskell}, | |||
| ```haskell | |||
| class Applicative m => Monad m where | |||
| return :: a -> m a | |||
| (>>=) :: m a -> (a -> m b) -> m b | |||
| {- Some fields omitted -} | |||
| ``` | |||
| How can we fit a parser in the above constraints? To answer that, we must first | |||
| define what a parser _is_. | |||
| A naïve implementation of the `Parser`{.haskell} type would be a simple type | |||
| synonym. | |||
| ```haskell | |||
| type Parser a = String -> (a, String) | |||
| ``` | |||
| This just defines that a parser is a function from a string to a result pair | |||
| with the parsed value and the resulting stream. This would mean that parsers are | |||
| just state transformers, and if we define it as a synonym for the existing mtl | |||
| `State`{.haskell} monad, we get the Monad, Functor and Applicative instances for | |||
| free! But alas, this will not do. | |||
| Apart from modeling the state transformation that a parser expresses, we need a | |||
| way to represent failure. You already know that `Maybe a`{.haskell} expresses | |||
| failure, so we could try something like this: | |||
| ```haskell | |||
| type Parser a = String -> Maybe (a, String) | |||
| ``` | |||
| But, as you might have guessed, this is not the optimal representation either: | |||
| `Maybe`{.haskell} _does_ model failure, but in a way that is lacking. It can | |||
| only express that a computation was successful or that it failed, not why it | |||
| failed. We need a way to fail with an error message. That is, the | |||
| `Either`{.haskell} monad. | |||
| ```haskell | |||
| type Parser e a = String -> Either e (a, String) | |||
| ``` | |||
| Notice how we have the `Maybe`{.haskell} and `Either`{.haskell} outside the | |||
| tuple, so that when an error happens we stop parsing immediately. We could | |||
| instead have them inside the tuple for better error reporting, but that's out of | |||
| scope for a simple blag post. | |||
| This is pretty close to the optimal representation, but there are still some | |||
| warts things to address: `String`{.haskell} is a bad representation for textual | |||
| data, so ideally you'd have your own `Stream`{.haskell} class that has instances | |||
| for things such as `Text`{.haskell}, `ByteString`{.haskell} and | |||
| `String`{.haskell}. | |||
| One issue, however, is more glaring: You _can't_ define typeclass instances for | |||
| type synonyms! The fix, however, is simple: make `Parser`{.haskell} a newtype. | |||
| ```haskell | |||
| newtype Parser a | |||
| = Parser { parse :: String -> Either String (a, String) } | |||
| ``` | |||
| --- | |||
| Now that that's out of the way, we can actually get around to instancing some | |||
| typeclasses. | |||
| Since the AMP landed in GHC 7.10 (base 4.8), the hierarchy of the Monad | |||
| typeclass is as follows: | |||
| ```haskell | |||
| class Functor (m :: * -> *) where | |||
| class Functor m => Applicative m where | |||
| class Applicative m => Monad m where | |||
| ``` | |||
| That is, we need to implement Functor and Applicative before we can actually | |||
| implement Monad. | |||
| We shall also add an `Alternative`{.haskell} instance for expressing choice. | |||
| First we need some utility functions, such as `runParser`{.haskell}, that runs a | |||
| parser from a given stream. | |||
| ```haskell | |||
| runParser :: Parser a -> String -> Either String a | |||
| runParser (Parser p) s = fst <$> p s | |||
| ``` | |||
| We could also use function for modifying error messages. For convenience, we | |||
| make this an infix operator, `<?>`{.haskell}. | |||
| ```haskell | |||
| (<?>) :: Parser a -> String -> Parser a | |||
| (Parser p) <?> err = Parser go where | |||
| go s = case p s of | |||
| Left _ -> Left err | |||
| Right x -> return x | |||
| infixl 2 <?> | |||
| ``` | |||
| `Functor` | |||
| ======= | |||
| Remember that Functor models something that can be mapped over (technically, | |||
| `fmap`-ed over). | |||
| We need to define semantics for `fmap` on Parsers. A sane implementation would | |||
| only map over the result, and keeping errors the same. This is a homomorphism, | |||
| and follows the Functor laws. | |||
| However, since we can't modify a function in place, we need to return a new | |||
| parser that applies the given function _after_ the parsing is done. | |||
| ```haskell | |||
| instance Functor Parser where | |||
| fn `fmap` (Parser p) = Parser go where | |||
| go st = case p st of | |||
| Left e -> Left e | |||
| Right (res, str') -> Right (fn res, str') | |||
| ``` | |||
| ### `Applicative` | |||
| While Functor is something that can be mapped over, Applicative defines | |||
| semantics for applying a function inside a context to something inside a | |||
| context. | |||
| The Applicative class is defined as | |||
| ```haskell | |||
| class Functor m => Applicative m where | |||
| pure :: a -> m a | |||
| (<*>) :: f (a -> b) -> f a -> f b | |||
| ``` | |||
| Notice how the `pure`{.haskell} and the `return`{.haskell} methods are | |||
| equivalent, so we only have to implement one of them. | |||
| Let's go over this by parts. | |||
| ```haskell | |||
| instance Applicative Parser where | |||
| pure x = Parser $ \str -> Right (x, str) | |||
| ``` | |||
| The `pure`{.haskell} function leaves the stream untouched, and sets the result | |||
| to the given value. | |||
| The `(<*>)`{.haskell} function needs to to evaluate and parse the left-hand side | |||
| to get the in-context function to apply it. | |||
| ```haskell | |||
| (Parser p) <*> (Parser p') = Parser go where | |||
| go st = case p st of | |||
| Left e -> Left e | |||
| Right (fn, st') -> case p' st' of | |||
| Left e' -> Left e' | |||
| Right (v, st'') -> Right (fn v, st'') | |||
| ``` | |||
| ### `Alternative` | |||
| Since the only superclass of Alternative is Applicative, we can instance it | |||
| without a Monad instance defined. We do, however, need an import of | |||
| `Control.Applicative`{.haskell}. | |||
| ```haskell | |||
| instance Alternative Parser where | |||
| empty = Parser $ \_ -> Left "empty parser" | |||
| (Parser p) <|> (Parser p') = Parser go where | |||
| go st = case p st of | |||
| Left _ -> p' st | |||
| Right x -> Right x | |||
| ``` | |||
| ### `Monad` | |||
| After almost a thousand words, one would be excused for forgetting we're | |||
| implementing a _monadic_ parser combinator library. That means, we need an | |||
| instance of the `Monad`{.haskell} typeclass. | |||
| Since we have an instance of Applicative, we don't need an implementation of | |||
| return: it is equivalent to `pure`, save for the class constraint. | |||
| ```haskell | |||
| instance Monad Parser where | |||
| return = pure | |||
| ``` | |||
| The `(>>=)`{.haskell} implementation, however, needs a bit more thought. Its | |||
| type signature is | |||
| ```haskell | |||
| (>>=) :: m a -> (a -> m b) -> m b | |||
| ``` | |||
| That means we need to extract a value from the Parser monad and apply it to the | |||
| given function, producing a new Parser. | |||
| ```haskell | |||
| (Parser p) >>= f = Parser go where | |||
| go s = case p s of | |||
| Left e -> Left e | |||
| Right (x, s') -> parse (f x) s' | |||
| ``` | |||
| While some people think that the `fail`{.haskell} is not supposed to be in the | |||
| Monad typeclass, we do need an implementation for when pattern matching fails. | |||
| It is also convenient to use `fail`{.haskell} for the parsing action that | |||
| returns an error with a given message. | |||
| ```haskell | |||
| fail m = Parser $ \_ -> Left m | |||
| ``` | |||
| --- | |||
| We now have a `Parser`{.haskell} monad, that expresses a parsing action. But, a | |||
| parser library is no good when actual parsing is made harder than easier. To | |||
| make parsing easier, we define _combinators_, functions that modify a parser in | |||
| one way or another. | |||
| But first, we should get some parsing functions. | |||
| ### any, satisfying | |||
| `any` is the parsing action that pops a character off the stream and returns | |||
| that. It does no further parsing at all. | |||
| ```haskell | |||
| any :: Parser Char | |||
| any = Parser go where | |||
| go [] = Left "any: end of file" | |||
| go (x:xs) = Right (x,xs) | |||
| ``` | |||
| `satisfying` tests the parsed value against a function of type `Char -> | |||
| Bool`{.haskell} before deciding if it's successful or a failure. | |||
| ```haskell | |||
| satisfy :: (Char -> Bool) -> Parser Char | |||
| satisfy f = d | |||
| x <- any | |||
| if f x | |||
| then return x | |||
| else fail "satisfy: does not satisfy" | |||
| ``` | |||
| We use the `fail`{.haskell} function defined above to represent failure. | |||
| ### `oneOf`, `char` | |||
| These functions are defined in terms of `satisfying`, and parse individual | |||
| characters. | |||
| ```haskell | |||
| char :: Char -> Parser Char | |||
| char c = satisfy (c ==) <?> "char: expected literal " ++ [c] | |||
| oneOf :: String -> Parser Char | |||
| oneOf s = satisfy (`elem` s) <?> "oneOf: expected one of '" ++ s ++ "'" | |||
| ``` | |||
| ### `string` | |||
| This parser parses a sequence of characters, in order. | |||
| ```haskell | |||
| string :: String -> Parser String | |||
| string [] = return [] | |||
| string (x:xs) = do | |||
| char x | |||
| string xs | |||
| return $ x:xs | |||
| ``` | |||
| --- | |||
| And that's it! In a few hundred lines, we have built a working parser combinator | |||
| library with Functor, Applicative, Alternative, and Monad instances. While it's | |||
| not as complex or featureful as Parsec in any way, it is powerful enough to | |||
| define grammars for simple languages. | |||
| [A transcription](/static/Parser.hs) ([with syntax | |||
| highlighting](/static/Parser.hs.html)) of this file is available as runnable | |||
| Haskell. The transcription also features some extra combinators for use. | |||
+ 331
- 0
pages/posts/2016-08-23-hasochism.lhs
View File
| @ -0,0 +1,331 @@ | |||
| --- | |||
| title: Dependent types in Haskell - Sort of | |||
| date: August 23, 2016 | |||
| --- | |||
| **Warning**: An intermediate level of type-fu is necessary for understanding | |||
| *this post. | |||
| The glorious Glasgow Haskell Compilation system, since around version 6.10 has | |||
| had support for indexed type familes, which let us represent functional | |||
| relationships between types. Since around version 7, it has also supported | |||
| datatype-kind promotion, which lifts arbitrary data declarations to types. Since | |||
| version 8, it has supported an extension called `TypeInType`, which unifies the | |||
| kind and type level. | |||
| With this in mind, we can implement the classical dependently-typed example: | |||
| Length-indexed lists, also called `Vectors`{.haskell}. | |||
| ---- | |||
| > {-# LANGUAGE TypeInType #-} | |||
| `TypeInType` also implies `DataKinds`, which enables datatype promotion, and | |||
| `PolyKinds`, which enables kind polymorphism. | |||
| `TypeOperators` is needed for expressing type-level relationships infixly, and | |||
| `TypeFamilies` actually lets us define these type-level functions. | |||
| > {-# LANGUAGE TypeOperators #-} | |||
| > {-# LANGUAGE TypeFamilies #-} | |||
| Since these are not simple-kinded types, we'll need a way to set their kind | |||
| signatures[^kind] explicitly. We'll also need Generalized Algebraic Data Types | |||
| (or GADTs, for short) for defining these types. | |||
| > {-# LANGUAGE KindSignatures #-} | |||
| > {-# LANGUAGE GADTs #-} | |||
| Since GADTs which couldn't normally be defined with regular ADT syntax can't | |||
| have deriving clauses, we also need `StandaloneDeriving`. | |||
| > {-# LANGUAGE StandaloneDeriving #-} | |||
| > module Vector where | |||
| > import Data.Kind | |||
| ---- | |||
| Natural numbers | |||
| =============== | |||
| We could use the natural numbers (and singletons) implemented in `GHC.TypeLits`, | |||
| but since those are not defined inductively, they're painful to use for our | |||
| purposes. | |||
| Recall the definition of natural numbers proposed by Giuseppe Peano in his | |||
| axioms: **Z**ero is a natural number, and the **s**uccessor of a natural number | |||
| is also a natural number. | |||
| If you noticed the bold characters at the start of the words _zero_ and | |||
| _successor_, you might have already assumed the definition of naturals to be | |||
| given by the following GADT: | |||
| < data Nat where | |||
| < Z :: Nat | |||
| < S :: Nat -> Nat | |||
| This is fine if all you need are natural numbers at the _value_ level, but since | |||
| we'll be parametrising the Vector type with these, they have to exist at the | |||
| type level. The beauty of datatype promotion is that any promoted type will | |||
| exist at both levels: A kind with constructors as its inhabitant types, and a | |||
| type with constructors as its... constructors. | |||
| Since we have TypeInType, this declaration was automatically lifted, but we'll | |||
| use explicit kind signatures for clarity. | |||
| > data Nat :: Type where | |||
| > Z :: Nat | |||
| > S :: Nat -> Nat | |||
| The `Type` kind, imported from `Data.Kind`, is a synonym for the `*` (which will | |||
| eventually replace the latter). | |||
| Vectors | |||
| ======= | |||
| Vectors, in dependently-typed languages, are lists that apart from their content | |||
| encode their size along with their type. | |||
| If we assume that lists can not have negative length, and an empty vector has | |||
| length 0, this gives us a nice inductive definition using the natural number | |||
| ~~type~~ kind[^kinds] | |||
| > 1. An empty vector of `a` has size `Z`{.haskell}. | |||
| > 2. Adding an element to the front of a vector of `a` and length `n` makes it | |||
| > have length `S n`{.haskell}. | |||
| We'll represent this in Haskell as a datatype with a kind signature of `Nat -> | |||
| Type -> Type` - That is, it takes a natural number (remember, these were | |||
| automatically lifted to kinds), a regular type, and produces a regular type. | |||
| Note that, `->` still means a function at the kind level. | |||
| > data Vector :: Nat -> Type -> Type where | |||
| Or, without use of `Type`, | |||
| < data Vector :: Nat -> * -> * where | |||
| We'll call the empty vector `Nil`{.haskell}. Remember, it has size | |||
| `Z`{.haskell}. | |||
| > Nil :: Vector Z a | |||
| Also note that type variables are implicit in the presence of kind signatures: | |||
| They are assigned names in order of appearance. | |||
| Consing onto a vector, represented by the infix constructor `:|`, sets its | |||
| length to the successor of the existing length, and keeps the type of elements | |||
| intact. | |||
| > (:|) :: a -> Vector x a -> Vector (S x) a | |||
| Since this constructor is infix, we also need a fixidity declaration. For | |||
| consistency with `(:)`, cons for regular lists, we'll make it right-associative | |||
| with a precedence of `5`. | |||
| > infixr 5 :| | |||
| We'll use derived `Show`{.haskell} and `Eq`{.haskell} instances for | |||
| `Vector`{.haskell}, for clarity reasons. While the derived `Eq`{.haskell} is | |||
| fine, one would prefer a nicer `Show`{.haskell} instance for a | |||
| production-quality library. | |||
| > deriving instance Show a => Show (Vector n a) | |||
| > deriving instance Eq a => Eq (Vector n a) | |||
| Slicing up Vectors {#slicing} | |||
| ================== | |||
| Now that we have a vector type, we'll start out by implementing the 4 basic | |||
| operations for slicing up lists: `head`, `tail`, `init` and `last`. | |||
| Since we're working with complicated types here, it's best to always use type | |||
| signatures. | |||
| Head and Tail {#head-and-tail} | |||
| ------------- | |||
| Head is easy - It takes a vector with length `>1`, and returns its first | |||
| element. This could be represented in two ways. | |||
| < head :: (S Z >= x) ~ True => Vector x a -> a | |||
| This type signature means that, if the type-expression `S Z >= x`{.haskell} | |||
| unifies with the type `True` (remember - datakind promotion at work), then head | |||
| takes a `Vector x a` and returns an `a`. | |||
| There is, however, a much simpler way of doing the above. | |||
| > head :: Vector (S x) a -> a | |||
| That is, head takes a vector whose length is the successor of a natural number | |||
| `x` and returns its first element. | |||
| The implementation is just as concise as the one for lists: | |||
| > head (x :| _) = x | |||
| That's it. That'll type-check and compile. | |||
| Trying, however, to use that function on an empty vector will result in a big | |||
| scary type error: | |||
| ```plain | |||
| Vector> Vector.head Nil | |||
| <interactive>:1:13: error: | |||
| • Couldn't match type ‘'Z’ with ‘'S x0’ | |||
| Expected type: Vector ('S x0) a | |||
| Actual type: Vector 'Z a | |||
| • In the first argument of ‘Vector.head’, namely ‘Nil’ | |||
| In the expression: Vector.head Nil | |||
| In an equation for ‘it’: it = Vector.head Nil | |||
| ``` | |||
| Simplified, it means that while it was expecting the successor of a natural | |||
| number, it got zero instead. This function is total, unlike the one in | |||
| `Data.List`{.haskell}, which fails on the empty list. | |||
| < head [] = error "Prelude.head: empty list" | |||
| < head (x:_) = x | |||
| Tail is just as easy, except in this case, instead of discarding the predecessor | |||
| of the vector's length, we'll use it as the length of the resulting vector. | |||
| This makes sense, as, logically, getting the tail of a vector removes its first | |||
| length, thus "unwrapping" a level of `S`. | |||
| > tail :: Vector (S x) a -> Vector x a | |||
| > tail (_ :| xs) = xs | |||
| Notice how neither of these have a base case for empty vectors. In fact, adding | |||
| one will not typecheck (with the same type of error - Can't unify `Z`{.haskell} | |||
| with `S x`{.haskell}, no matter how hard you try.) | |||
| Init {#init} | |||
| ---- | |||
| What does it mean to take the initial of an empty vector? That's obviously | |||
| undefined, much like taking the tail of an empty vector. That is, `init` and | |||
| `tail` have the same type signature. | |||
| > init :: Vector (S x) a -> Vector x a | |||
| The `init` of a singleton list is nil. This type-checks, as the list would have | |||
| had length `S Z` (that is - 1), and now has length `Z`. | |||
| > init (x :| Nil) = Nil | |||
| To take the init of a vector with more than one element, all we do is recur on | |||
| the tail of the list. | |||
| > init (x :| y :| ys) = x :| Vector.init (y :| ys) | |||
| That pattern is a bit weird - it's logically equivalent to `(x :| | |||
| xs)`{.haskell}. But, for some reason, that doesn't make the typechecker happy, | |||
| so we use the long form. | |||
| Last {#last} | |||
| ---- | |||
| Last can, much like the list version, be implemented in terms of a left fold. | |||
| The type signature is like the one for head, and the fold is the same as that | |||
| for lists. The foldable instance for vectors is given [here](#Foldable). | |||
| > last :: Vector (S x) a -> a | |||
| > last = foldl (\_ x -> x) impossible where | |||
| Wait - what's `impossible`? Since this is a fold, we do still need an initial | |||
| element - We could use a pointful fold with the head as the starting point, but | |||
| I feel like this helps us to understand the power of dependently-typed vectors: | |||
| That error will _never_ happen. Ever. That's why it's `impossible`! | |||
| > impossible = error "Type checker, you have failed me!" | |||
| That's it for the basic vector operations. We can now slice a vector anywhere | |||
| that makes sense - Though, there's one thing missing: `uncons`. | |||
| Uncons {#uncons} | |||
| ------ | |||
| Uncons splits a list (here, a vector) into a pair of first element and rest. | |||
| With lists, this is generally implemented as returning a `Maybe`{.haskell} type, | |||
| but since we can encode the type of a vector in it's type, there's no need for | |||
| that here. | |||
| > uncons :: Vector (S x) a -> (a, Vector x a) | |||
| > uncons (x :| xs) = (x, xs) | |||
| Mapping over Vectors {#functor} | |||
| ==================== | |||
| We'd like a `map` function that, much like the list equivalent, applies a | |||
| function to all elements of a vector, and returns a vector with the same length. | |||
| This operation should hopefully be homomorphic: That is, it keeps the structure | |||
| of the list intact. | |||
| The `base` package has a typeclass for this kind of morphism, can you guess what | |||
| it is? If you guessed Functor, then you're right! If you didn't, you might | |||
| aswell close the article now - Heavy type-fu inbound, though not right now. | |||
| The functor instance is as simple as can be: | |||
| > instance Functor (Vector x) where | |||
| The fact that functor expects something of kind `* -> *`, we need to give the | |||
| length in the instance head - And since we do that, the type checker guarantees | |||
| that this is, in fact, a homomorphic relationship. | |||
| Mapping over `Nil` just returns `Nil`. | |||
| > f `fmap` Nil = Nil | |||
| Mapping over a list is equivalent to applying the function to the first element, | |||
| then recurring over the tail of the vector. | |||
| > f `fmap` (x :| xs) = f x :| (fmap f xs) | |||
| We didn't really need an instance of Functor, but I think standalone map is | |||
| silly. | |||
| Folding Vectors {#foldable} | |||
| =============== | |||
| The Foldable class head has the same kind signature as the Functor class head: | |||
| `(* -> *) -> Constraint` (where `Constraint` is the kind of type classes), that | |||
| is, it's defined by the class head | |||
| < class Foldable (t :: Type -> Type) where | |||
| So, again, the length is given in the instance head. | |||
| > instance Foldable (Vector x) where | |||
| > foldr f z Nil = z | |||
| > foldr f z (x :| xs) = f x $ foldr f z xs | |||
| This is _exactly_ the Foldable instance for `[a]`, except the constructors are | |||
| different. Hopefully, by now you've noticed that Vectors have the same | |||
| expressive power as lists, but with more safety enforced by the type checker. | |||
| Conclusion | |||
| ========== | |||
| Two thousand words in, we have an implementation of functorial, foldable vectors | |||
| with implementations of `head`, `tail`, `init`, `last` and `uncons`. Since | |||
| going further (implementing `++`, since a Monoid instance is impossible) would | |||
| require implementing closed type familes, we'll leave that for next time. | |||
| Next time, we'll tackle the implementation of `drop`, `take`, `index` (`!!`, but | |||
| for vectors), `append`, `length`, and many other useful list functions. | |||
| Eventually, you'd want an implementation of all functions in `Data.List`. We | |||
| shall tackle `filter` in a later issue. | |||
| [^kind]: You can read about [Kind polymorphism and | |||
| Type-in-Type](https://downloads.haskell.org/~ghc/latest/docs/html/users_guide/glasgow_exts.html#kind-polymorphism-and-type-in-type) | |||
| in the GHC manual. | |||
| [^kinds]: The TypeInType extension unifies the type and kind level, but this | |||
| article still uses the word `kind` throughout. This is because it's easier to | |||
| reason about types, datatype promotion and type familes if you have separate | |||
| type and kind levels. | |||
+ 172
- 0
pages/posts/2016-08-26-parsec2.lhs
View File
| @ -0,0 +1,172 @@ | |||
| --- | |||
| title: Monadic Parsing with User State | |||
| date: August 26, 2016 | |||
| --- | |||
| > {-# LANGUAGE FlexibleInstances, MultiParamTypeClasses #-} | |||
| > module StatefulParsing where | |||
| > import Control.Monad.State.Class | |||
| > import Control.Applicative | |||
| In this post I propose an extension to the monadic parser framework | |||
| introduced in a previous post, _[You could have invented | |||
| Parsec](/posts/2016-08-17.html)_, that extends | |||
| the parser to also support embedded user state in your parsing. | |||
| This could be used, for example, for parsing a language with | |||
| user-extensible operators: The precedences and fixidities of operators | |||
| would be kept in a hashmap threaded along the bind chain. | |||
| Instead of posing these changes as diffs, we will rewrite the parser | |||
| framework from scratch with the updated type. | |||
| --- | |||
| Parser `newtype`{.haskell} | |||
| ========================= | |||
| Our new parser is polymorphic in both the return type and the user state | |||
| that, so we have to update the `newtype`{.haskell} declaration to match. | |||
| > newtype Parser state result | |||
| > = Parser { runParser :: String | |||
| > -> state | |||
| > -> Either String (result, state, String) } | |||
| Our tuple now contains the result of the parsing operation and the new | |||
| user state, along with the stream. We still need to supply a stream to | |||
| parse, and now also supply the initial state. This will be reflected in | |||
| our functions. | |||
| For convenience, we also make a `Parser' a`{.haskell} type alias for | |||
| parsers with no user state. | |||
| < type Parser' a = Parser () a | |||
| Seeing as type constructors are also curried, we can apply η-reduction | |||
| to get the following, which is what we'll go | |||
| with. | |||
| > type Parser' = Parser () | |||
| `Functor`{.haskell} instance | |||
| ============================ | |||
| > instance Functor (Parser st) where | |||
| The functor instance remains mostly the same, except now we have to | |||
| thread the user state around, too. | |||
| The instance head also changes to fit the kind signature of the | |||
| `Functor`{.haskell} typeclass. Since user state can not change from | |||
| fmapping, this is fine. | |||
| > fn `fmap` (Parser p) = Parser go where | |||
| > go st us = case p st us of | |||
| > Left e -> Left e | |||
| > Right (r, us', st') -> Right (fn r, us', st') | |||
| As you can see, the new user state (`us'`) is just returned as is. | |||
| `Applicative`{.haskell} instance | |||
| ================================ | |||
| > instance Applicative (Parser st) where | |||
| The new implementations of `pure`{.haskell} and `<*>`{.haskell} need to | |||
| correctly manipulate the user state. In the case of `pure`, it's just passed | |||
| as-is to the `Right`{.haskell} constructor. | |||
| > pure ret = Parser go where | |||
| > go st us = Right (ret, us, st) | |||
| Since `(<*>)` needs to evaluate both sides before applying the function, we need | |||
| to pass the right-hand side's generated user state to the right-hand side for | |||
| evaluation. | |||
| > (Parser f) <*> (Parser v) = Parser go where | |||
| > go st us = case f st us of | |||
| > Left e -> Left e | |||
| > Right (fn, us', st') -> case v st' us' of | |||
| > Left e -> Left e | |||
| > Right (vl, us'', st'') -> Right (fn vl, us'', st'') | |||
| `Monad`{.haskell} instance | |||
| ========================== | |||
| > instance Monad (Parser st) where | |||
| Since we already have an implementation of `pure`{.haskell} from the Applicative | |||
| instance, we don't need to worry about an implementation of `return`. | |||
| > return = pure | |||
| The monad instance is much like the existing monad instance, except now we have | |||
| to give the updated parser state to the new computation. | |||
| > (Parser p) >>= f = Parser go where | |||
| > go s u = case p s u of | |||
| > Left e -> Left e | |||
| > Right (x, u', s') -> runParser (f x) s' u' | |||
| `MonadState`{.haskell} instance | |||
| =============================== | |||
| > instance MonadState st (Parser st) where | |||
| Since we now have a state transformer in the parser, we can make it an instance | |||
| of the MTL's `MonadState` class. | |||
| The implementation of `put`{.haskell} must return `()` (the unit value), and | |||
| needs to replace the existing state with the supplied one. This operation can | |||
| not fail. | |||
| Since this is a parsing framework, we also need to define how the stream is | |||
| going to be affected: In this case, it isn't. | |||
| > put us' = Parser go where | |||
| > go st _ = Right ((), us', st) | |||
| The `get`{.haskell} function returns the current user state, and leaves it | |||
| untouched. This operation also does not fail. | |||
| > get = Parser go where | |||
| > go st us = Right (us, us, st) | |||
| Since we're an instance of `MonadState`{.haskell}, we needn't an implementation | |||
| of `modify` and friends - They're given by the MTL. | |||
| `Alternative`{.haskell} instance | |||
| ================================ | |||
| > instance Alternative (Parser st) where | |||
| The `Alternative`{.haskell} instance uses the same state as it was given for | |||
| trying the next parse. | |||
| The `empty`{.haskell} parser just fails unconditionally. | |||
| > empty = Parser go where | |||
| > go _ _ = Left "empty parser" | |||
| `(<|>)` will try both parsers in order, reusing both the state and the stream. | |||
| > (Parser p) <|> (Parser q) = Parser go where | |||
| > go st us = case p st us of | |||
| > Left e -> q st us | |||
| > Right v -> Right v | |||
| Conclusion | |||
| ========== | |||
| This was a relatively short post. This is because many of the convenience | |||
| functions defined in the previous post also work with this parser framework, if | |||
| you replace `Parser` with `Parser'`. You can now use `get`, `put` and `modify` | |||
| to work on the parser's user state. As a closing note, a convenience function | |||
| for running parsers with no state is given. | |||
| > parse :: Parser' a -> String -> Either String a | |||
| > parse str = case runParser str () of | |||
| > Left e -> Left e | |||
| > Right (x, _, _) -> x | |||
+ 155
- 0
pages/posts/2017-08-01-delimcc.md
View File
| @ -0,0 +1,155 @@ | |||
| --- | |||
| title: Delimited Continuations, Urn and Lua | |||
| date: August 1, 2017 | |||
| --- | |||
| As some of you might know, [Urn](https://squiddev.github.io/urn) is my | |||
| current pet project. This means that any potential upcoming blag posts | |||
| are going to involve it in some way or another, and that includes this | |||
| one. For the uninitiated, Urn is a programming language which compiles | |||
| to Lua[^1], in the Lisp tradition, with no clear ascendance: We take | |||
| inspiration from several Lisps, most notably Common Lisp and Scheme. | |||
| As functional programmers at heart, we claim to be minimalists: Urn is | |||
| reduced to 12 core forms before compilation, with some of those being | |||
| redundant (e.g. having separate `define` and `define-macro` builtins | |||
| instead of indicating that the definition is a macro through | |||
| a parameter). On top of these primitives we build all our abstraction, | |||
| and one such abstraction is what this post is about: _Delimited | |||
| continuations_. | |||
| Delimited continuations are a powerful control abstraction first | |||
| introduced by Matthias Felleisein[^2], initially meant as | |||
| a generalisation of several other control primitives such as | |||
| `call-with-current-continuation`{.scheme} from Scheme among others. | |||
| However, whereas `call-with-current-continuation`{.scheme} captures | |||
| a continuation representing the state of the entire program after that | |||
| point, delimited continuations only reify a slice of program state. In | |||
| this, they are cheaper to build and invoke, and as such may be used to | |||
| implement e.g. lightweight threading primitives. | |||
| While this may sound rather limiting, there are very few constructs that | |||
| can simultaneously be implemented with | |||
| `call-with-current-continuation`{.scheme} without also being expressible | |||
| in terms of delimited continuations. The converse, however, is untrue. | |||
| While `call/cc`{.scheme} be used to implement any control abstraction, | |||
| it can't implement any _two_ control abstractions: the continuations it | |||
| reifies are uncomposable[^3]. | |||
| ### Delimited Continuations in Urn | |||
| Our implementation of delimited continuations follows the Guile Scheme | |||
| tradition of two functions `call-with-prompt` and `abort-to-prompt`, | |||
| which are semantically equivalent to the more traditional | |||
| `shift`/`reset`. This is, however, merely an implementation detail, as | |||
| both schemes are available. | |||
| We have decided to base our implementation on Lua's existing coroutine | |||
| machinery instead of implementing an ad-hoc solution especially for Urn. | |||
| This lets us reuse and integrate with existing Lua code, which is one of | |||
| the goals for the language. | |||
| `call-with-prompt` is used to introduce a _prompt_ into scope, which | |||
| delimits a frame execution and sets up an abort handler with the | |||
| specified tag. Later on, calls to `abort-to-prompt` reify the rest of | |||
| the program slice's state and jump into the handler set up. | |||
| ```lisp | |||
| (call/p 'a-prompt-tag | |||
| (lambda () | |||
| ; code to run with the prompt | |||
| ) | |||
| (lambda (k) | |||
| ; abort handler | |||
| )) | |||
| ``` | |||
| One limitation of the current implementation is that the continuation, | |||
| when invoked, will no longer have the prompt in scope. A simple way to | |||
| get around this is to store the prompt tag and handler in values and use | |||
| `call/p`[^4] again instead of directly calling the continuation. | |||
| Unfortunately, being implemented on top of Lua coroutines does bring one | |||
| significant disadvantage: The reified continuations are single-use. | |||
| After a continuation has reached the end of its control frame, there's | |||
| no way to make it go back, and there's no way to copy continuations | |||
| either (while we have a wrapper around coroutines, the coroutines | |||
| themselves are opaque objects, and there's no equivalent of | |||
| `string.dump`{.lua} to, for instance, decompile and recompile them) | |||
| ### Why? | |||
| In my opinion (which, like it or not, is the opinion of the Urn team), | |||
| Guile-style delimited continuations provide a much better abstraction | |||
| than operating with Lua coroutines directly, which may be error prone | |||
| and feels out of place in a functional-first programming language. | |||
| As a final motivating example, below is an in-depth explanation of | |||
| a tiny cooperative task scheduler. | |||
| ```lisp | |||
| (defun run-tasks (&tasks) ; 1 | |||
| (loop [(queue tasks)] ; 2 | |||
| [(empty? queue)] ; 2 | |||
| (call/p 'task (car queue) | |||
| (lambda (k) | |||
| (when (alive? k) | |||
| (push-cdr! queue k)))) ; 3 | |||
| (recur (cdr queue)))) ; 4 | |||
| ``` | |||
| 1. We begin, of course, by defining our function. As inputs, we take | |||
| a list of tasks to run, which are generally functions, but may be Lua | |||
| coroutines (`threads`) or existing continuations, too. As a sidenote, | |||
| in Urn, variadic arguments have `&` prepended to them, instead of | |||
| having symbols beginning of `&` acting as modifiers in a lambda-list. | |||
| For clarity, that is wholly equivalent to `(defun run-tasks (&rest | |||
| tasks)`{.lisp}. | |||
| 2. Then, we take the first element of the queue as the current task to | |||
| run, and set up a prompt of execution. The task will run until it | |||
| hits an `abort-to-prompt`, at which point it will be interrupted and | |||
| the handler will be invoked. | |||
| 3. The handler inspects the reified continuation to see if it is | |||
| suitable for being scheduled again, and if so, pushes it to the end | |||
| of the queue. This means it'll be the first task to execute again | |||
| when the scheduler is done with the current set of working tasks. | |||
| 4. We loop back to the start with the first element (the task we just | |||
| executed) removed. | |||
| Believe it or not, the above is a fully functioning cooperative | |||
| scheduler that can execute any number of tasks.[^5] | |||
| ### Conclusion | |||
| I think that the addition of delimited continuations to Urn brings | |||
| a much needer change in the direction of the project: Moving away from | |||
| ad-hoc abstraction to structured, proven abstraction. Hopefully this is | |||
| the first of many to come. | |||
| [^1]: Though this might come off as a weird decision to some, there is | |||
| a logical reason behind it: Urn was initially meant to be used in the | |||
| [ComputerCraft](https://computercraft.info) mod for Minecraft, which | |||
| uses the Lua programming language, though the language has outgrown it | |||
| by now. For example, the experimental `readline` support is being | |||
| implemented with the LuaJIT foreign function interface. | |||
| [^2]: [The Theory and Practice of First-Class | |||
| Prompts](http://www.cs.tufts.edu/~nr/cs257/archive/matthias-felleisen/prompts.pdf). | |||
| [^3]: Oleg Kiselyov demonstrates | |||
| [here](http://okmij.org/ftp/continuations/against-callcc.html#traps) | |||
| that abstractions built on `call/cc`{.scheme} do not compose. | |||
| [^4]: `call-with-prompt` is a bit of a mouthful, so the alias `call/p` | |||
| is blessed. | |||
| [^5]: There's a working example [here](/static/tasks.lisp) ([with syntax | |||
| highlighting](/static/tasks.lisp.html)) as runnable Urn. Clone the | |||
| compiler then execute `lua bin/urn.lua --run tasks.lisp`. | |||
| <!-- vim: tw=72 | |||
| --> | |||
+ 231
- 0
pages/posts/2017-08-02-urnmatch.md
View File
| @ -0,0 +1,231 @@ | |||
| --- | |||
| title: The Urn Pattern Matching Library | |||
| date: August 2, 2017 | |||
| --- | |||
| Efficient compilation of pattern matching is not exactly an open problem | |||
| in computer science in the same way that implementing say, type systems, | |||
| might be, but it's still definitely possible to see a lot of mysticism | |||
| surrounding it. | |||
| In this post I hope to clear up some misconceptions regarding the | |||
| implementation of pattern matching by demonstrating one such | |||
| implementation. Do note that our pattern matching engine is strictly | |||
| _linear_, in that pattern variables may only appear once in the match | |||
| head. This is unlike other languages, such as Prolog, in which variables | |||
| appearing more than once in the pattern are unified together. | |||
| ### Structure of a Pattern Match | |||
| Pattern matching always involves a pattern (the _match head_, as we call | |||
| it) and a value to be compared against that pattern, the _matchee_. | |||
| Sometimes, however, a pattern match will also include a body, to be | |||
| evaluated in case the pattern does match. | |||
| ```lisp | |||
| (case 'some-value ; matchee | |||
| [some-pattern ; match head | |||
| (print! "some body")]) ; match body | |||
| ``` | |||
| As a side note, keep in mind that `case`{.lisp} has linear lookup of | |||
| match bodies. Though logarithmic or constant-time lookup might be | |||
| possible, it is left as an exercise for the reader. | |||
| ### Compiling Patterns | |||
| To simplify the task of compiling patterns to an intermade form without | |||
| them we divide their compilation into two big steps: compiling the | |||
| pattern's test and compiling the pattern's bindings. We do so | |||
| _inductively_ - there are a few elementary pattern forms on which the | |||
| more complicated ones are built upon. | |||
| Most of these elementary forms are very simple, but two are the | |||
| simplest: _atomic forms_ and _pattern variables_. An atomic form is the | |||
| pattern correspondent of a self-evaluating form in Lisp: a string, an | |||
| integer, a symbol. We compare these for pointer equality. Pattern | |||
| variables represent unknowns in the structure of the data, and a way to | |||
| capture these unknowns. | |||
| +------------------+----------+-------------+ | |||
| | Pattern | Test | Bindings | | |||
| +:=================+:=========+:============+ | |||
| | Atomic form | Equality | Nothing | | |||
| +------------------+----------+-------------+ | |||
| | Pattern variable | Nothing | The matchee | | |||
| +------------------+----------+-------------+ | |||
| All compilation forms take as input the pattern to compile along with | |||
| a symbol representing the matchee. Patterns which involve other patterns | |||
| (for instance, lists, conses) will call the appropriate compilation | |||
| forms with the symbol modified to refer to the appropriate component of | |||
| the matchee. | |||
| Let's quickly have a look at compiling these elementary patterns before | |||
| looking at the more interesting ones. | |||
| ```lisp | |||
| (defun atomic-pattern-test (pat sym) | |||
| `(= ,pat ,sym)) | |||
| (defun atomic-pattern-bindings (pat sym) | |||
| '()) | |||
| ``` | |||
| Atomic forms are the simplest to compile - we merely test that the | |||
| symbol's value is equal (with `=`, which compares identities, instead of | |||
| with `eq?` which checks for equivalence - more complicated checks, such | |||
| as handling list equality, need not be handled by the equality function | |||
| as we handle them in the pattern matching library itself) and emit no | |||
| bindings. | |||
| ```lisp | |||
| (defun variable-pattern-test (pat sym) | |||
| `true) | |||
| (defun variable-pattern-bindings (pat sym) | |||
| (list `(,pat ,sym))) | |||
| ``` | |||
| The converse is true for pattern variables, which have no test and bind | |||
| themselves. The returned bindings are in association list format, and | |||
| the top-level macro that users invoke will collect these and them bind | |||
| them with `let*`{.lisp}. | |||
| Composite forms are a bit more interesting: These include list patterns | |||
| and cons patterns, for instance, and we'll look at implementing both. | |||
| Let's start with list patterns. | |||
| To determine if a list matches a pattern we need to test for several | |||
| things: | |||
| 1. First, we need to test if it actually is a list at all! | |||
| 2. The length of the list is also tested, to see if it matches the length | |||
| of the elements stated in the pattern | |||
| 3. We check every element of the list against the corresponding elements | |||
| of the pattern | |||
| With the requirements down, here's the implementation. | |||
| ```lisp | |||
| (defun list-pattern-test (pat sym) | |||
| `(and (list? ,sym) ; 1 | |||
| (= (n ,sym) ,(n pat)) ; 2 | |||
| ,@(map (lambda (index) ; 3 | |||
| (pattern-test (nth pat index) `(nth ,sym ,index))) | |||
| (range :from 1 :to (n pat))))) | |||
| ``` | |||
| To test for the third requirement, we call a generic dispatch function | |||
| (which is trivial, and thus has been inlined) to compile the $n$th pattern | |||
| in the list against the $n$th element of the actual list. | |||
| List pattern bindings are similarly easy: | |||
| ```lisp | |||
| (defun list-pattern-bindings (pat sym) | |||
| (flat-map (lambda (index) | |||
| (pattern-bindings (nth pat index) `(nth ,sym ,index))) | |||
| (range :from 1 :to (n pat)))) | |||
| ``` | |||
| Compiling cons patterns is similarly easy if your Lisp is proper: We | |||
| only need to check for `cons`{.lisp}-ness (or `list`{.lisp}-ness, less | |||
| generally), then match the given patterns against the car and the cdr. | |||
| ```lisp | |||
| (defun cons-pattern-test (pat sym) | |||
| `(and (list? ,sym) | |||
| ,(pattern-test (cadr pat) `(car ,sym)) | |||
| ,(pattern-test (caddr pat) `(cdr ,sym)))) | |||
| (defun cons-pattern-bindings (pat sym) | |||
| (append (pattern-bindings (cadr pat) `(car ,sym)) | |||
| (pattern-bindings (caddr pat) `(cdr ,sym)))) | |||
| ``` | |||
| Note that, in Urn, `cons` patterns have the more general form `(pats* | |||
| . pat)` (using the asterisk with the usual meaning of asterisk), and can | |||
| match any number of elements in the head. It is also less efficient than | |||
| expected, due to the nature of `cdr` copying the list's tail. (Our lists | |||
| are not linked - rather, they are implemented over Lua arrays, and as | |||
| such, removing the first element is rather inefficient.) | |||
| ### Using patterns | |||
| Now that we can compile a wide assortment of patterns, we need a way to | |||
| actually use them to scrutinize data. For this, we implement two forms: | |||
| an improved version of `destructuring-bind`{.lisp} and `case`{.lisp}. | |||
| Implementing `destructuring-bind`{.lisp} is simple: We only have | |||
| a single pattern to test against, and thus no search is nescessary. We | |||
| simply generate the pattern test and the appropriate bindings, and | |||
| generate an error if the pattern does not mind. Generating a friendly | |||
| error message is similarly left as an exercise for the reader. | |||
| Note that as a well-behaving macro, destructuring bind will not evaluate | |||
| the given variable more than once. It does this by binding it to | |||
| a temporary name and scrutinizing that name instead. | |||
| ```lisp | |||
| (defmacro destructuring-bind (pat var &body) | |||
| (let* [(variable (gensym 'var)) | |||
| (test (pattern-test pat variable)) | |||
| (bindings (pattern-bindings pat variable))] | |||
| `(with (,variable ,var) | |||
| (if ,test | |||
| (progn ,@body) | |||
| (error! "pattern matching failure"))))) | |||
| ``` | |||
| Implementing case is a bit more difficult in a language without | |||
| `cond`{.lisp}, since the linear structure of a pattern-matching case | |||
| statement would have to be transformed into a tree of `if`-`else` | |||
| combinations. Fortunately, this is not our case (pun intended, | |||
| definitely.) | |||
| ```lisp | |||
| (defmacro case (var &cases) | |||
| (let* [(variable (gensym 'variable))] | |||
| `(with (,variable ,var) | |||
| (cond ,@(map (lambda (c) | |||
| `(,(pattern-test (car c) variable) | |||
| (let* ,(pattern-bindings (car c) variable) | |||
| ,@(cdr c)))) | |||
| cases))))) | |||
| ``` | |||
| Again, we prevent reevaluation of the matchee by binding it to | |||
| a temporary symbol. This is especially important in an impure, | |||
| expression-oriented language as evaluating the matchee might have side | |||
| effects! Consider the following contrived example: | |||
| ```lisp | |||
| (case (progn (print! "foo") | |||
| 123) | |||
| [1 (print! "it is one")] | |||
| [2 (print! "it is two")] | |||
| [_ (print! "it is neither")]) ; _ represents a wild card pattern. | |||
| ``` | |||
| If the matchee wasn't bound to a temporary value, `"foo"` would be | |||
| printed thrice in this example. Both the toy implementation presented | |||
| here and the implementation in the Urn standard library will only | |||
| evaluate matchees once, thus preventing effect duplication. | |||
| ### Conclusion | |||
| Unlike previous blog posts, this one isn't runnable Urn. If you're | |||
| interested, I recommend checking out [the actual | |||
| implementation](https://gitlab.com/urn/urn/blob/master/lib/match.lisp). | |||
| It gets a bit hairy at times, particularly with handling of structure | |||
| patterns (which match Lua tables), but it's similar enough to the above | |||
| that this post should serve as a vague map of how to read it. | |||
| In a bit of a meta-statement I want to point out that this is the first | |||
| (second, technically!) of a series of posts detailing the interesting | |||
| internals of the Urn standard library: It fixes two things in the sorely | |||
| lacking category: content in this blag, and standard library | |||
| documentation. | |||
| Hopefully this series is as nice to read as it is for me to write, and | |||
| here's hoping I don't forget about this blag for a year again. | |||
+ 276
- 0
pages/posts/2017-08-06-constraintprop.md
View File
| @ -0,0 +1,276 @@ | |||
| --- | |||
| title: Optimisation through Constraint Propagation | |||
| date: August 06, 2017 | |||
| --- | |||
| Constraint propagation is a new optimisation proposed for implementation | |||
| in the Urn compiler[^mr]. It is a variation on the idea of | |||
| flow-sensitive typing in that it is not applied to increasing program | |||
| safety, rather being used to improve _speed_. | |||
| ### Motivation | |||
| The Urn compiler is decently fast for being implemented in Lua. | |||
| Currently, it manages to compile itself (and a decent chunk of the | |||
| standard library) in about 4.5 seconds (when using LuaJIT; When using | |||
| the lua.org interpreter, this time roughly doubles). Looking at | |||
| a call-stack profile of the compiler, we notice a very interesting data | |||
| point: about 11% of compiler runtime is spent in the `(type)` function. | |||
| There are two ways to fix this: Either we introduce a type system (which | |||
| is insanely hard to do for a language as dynamic as Urn - or Lisp in | |||
| general) or we reduce the number of calls to `(type)` by means of | |||
| optimisation. Our current plan is to do the latter. | |||
| ### How | |||
| The proposed solution is to collect all the branches that the program | |||
| has taken to end up in the state it currently is. Thus, every branch | |||
| grows the set of "constraints" - the predicates which have been invoked | |||
| to get the program here. | |||
| Most useful predicates involve a variable: Checking if it is or isn't | |||
| nil, if is positive or negative, even or odd, a list or a string, and | |||
| etc. However, when talking about a single variable, this test only has | |||
| to be performed _once_ (in general - mutating the variable invalidates | |||
| the set of collected constraints), and their truthiness can be kept, by | |||
| the compiler, for later use. | |||
| As an example, consider the following code. It has three branches, all | |||
| of which imply something different about the type of the variable `x`. | |||
| ```lisp | |||
| (cond | |||
| [(list? x)] ; first case | |||
| [(string? x)] ; second case | |||
| [(number? x)]) ; third case | |||
| ``` | |||
| If, in the first case, the program then evaluated `(car x)`, it'd end up | |||
| doing a redundant type check. `(car)`, is, in the standard library, | |||
| implemented like so: | |||
| ```lisp | |||
| (defun car (x) | |||
| (assert-type! x list) | |||
| (.> x 0)) | |||
| ``` | |||
| `assert-type!` is merely a macro to make checking the types of arguments | |||
| more convenient. Let's make the example of branching code a bit more | |||
| complicated by making it take and print the `car` of the list. | |||
| ```lisp | |||
| (cond | |||
| [(list? x) | |||
| (print! (car x))]) | |||
| ; other branches elided for clarity | |||
| ``` | |||
| To see how constraint propagation would aid the runtime performance of | |||
| this code, let's play optimiser for a bit, and see what this code would | |||
| end up looking like at each step. | |||
| First, `(car x)` is inlined. | |||
| ```lisp | |||
| (cond | |||
| [(list? x) | |||
| (print! (progn (assert-type! x list) | |||
| (.> x 0)))]) | |||
| ``` | |||
| `assert-type!` is expanded, and the problem becomes apparent: the type | |||
| of `x` is being computed _twice_! | |||
| ```lisp | |||
| (cond | |||
| [(list? x) | |||
| (print! (progn (if (! (list? x)) | |||
| (error! "the argument x is not a list")) | |||
| (.> x 0)))]) | |||
| ``` | |||
| If the compiler had constraint propagation (and the associated code | |||
| motions), this code could be simplified further. | |||
| ```lisp | |||
| (cond | |||
| [(list? x) | |||
| (print! (.> x 0))]) | |||
| ``` | |||
| Seeing as we already know that `(list? x)` is true, we don't need to | |||
| test anymore, and the conditional can be entirely eliminated. Figuring | |||
| out `(! (list? x))` from `(list? x)` is entirely trivial constant | |||
| folding (the compiler already does it) | |||
| This code is optimal. The `(list? x)` test can't be eliminated because | |||
| nothing else is known about `x`. If its value were statically known, the | |||
| compiler could eliminate the branch and invocation of `(car x)` | |||
| completely by constant propagation and folding (`(car)` is, type | |||
| assertion notwithstanding, a pure function - it returns the same results | |||
| for the same inputs. Thus, it is safe to execute at compile time) | |||
| ### How, exactly | |||
| In this section I'm going to outline a very simple implementation of the | |||
| constraint propagation algorithm to be employed in the Urn compiler. | |||
| It'll work on a simple Lisp with no quoting or macros (thus, basically | |||
| the lambda calculus). | |||
| ```lisp | |||
| (lambda (var1 var2) exp) ; λ-abstraction | |||
| (foo bar baz) ; procedure application | |||
| var ; variable reference | |||
| (list x y z) ; list | |||
| t, nil ; boolean | |||
| (cond [t1 b1] [t2 b2]) ; conditional | |||
| ``` | |||
| The language has very simple semantics. It has three kinds of values | |||
| (closures, lists and booleans), and only a couple reduction rules. The | |||
| evaluation rules are presented as an interpretation function (in Urn, | |||
| not the language itself). | |||
| ```lisp | |||
| (defun interpret (x env) | |||
| (case x | |||
| [(lambda ?params . ?body) | |||
| `(:closure ,params ,body ,(copy env))] ; 1 | |||
| [(list . ?xs) | |||
| (map (cut interpret <> env) xs)] ; 2 | |||
| [t true] [nil false] ; 3 | |||
| [(cond . ?alts) ; 4 | |||
| (interpret | |||
| (block (map (lambda (alt) | |||
| (when (interpret (car alt) env) | |||
| (break (cdr alt)))))) | |||
| env)] | |||
| [(?fn . ?args) | |||
| (case (eval fn env) | |||
| [(:closure ?params ?body ?cl-env) ; 5 | |||
| (map (lambda (a k) | |||
| (.<! cl-env (symbol->string a) (interpret k env))) | |||
| params args) | |||
| (last (map (cut interpret <> env) body))] | |||
| [_ (error! $"not a procedure: ${fn}")])] | |||
| [else (.> env (symbol->string x))])) | |||
| ``` | |||
| 1. In the case the expression currently being evaluated is a lambda, we | |||
| make a copy of the current environment and store it in a _closure_. | |||
| 2. If a list is being evaluated, we recursively evaluate each | |||
| sub-expression and store all of them in a list. | |||
| 3. If a boolean is being interpreted, they're mapped to the respective | |||
| values in the host language. | |||
| 4. If a conditional is being evaluated, each test is performed in order, | |||
| and we abort to interpret with the corresponding body. | |||
| 5. When evaluating a procedure application, the procedure to apply is | |||
| inspected: If it is a closure, we evaluate all the arguments, bind | |||
| them along with the closure environment, and interpret the body. If | |||
| not, an error is thrown. | |||
| Collecting constraints in a language as simple as this is fairly easy, | |||
| so here's an implementation. | |||
| ```lisp | |||
| (defun collect-constraints (expr (constrs '())) | |||
| (case expr | |||
| [(lambda ?params . ?body) | |||
| `(:constraints (lambda ,params | |||
| ,@(map (cut collect-constraints <> constrs) body)) | |||
| ,constrs)] | |||
| ``` | |||
| Lambda expressions incur no additional constraints, so the inner | |||
| expressions (namely, the body) receive the old set. | |||
| The same is true for lists: | |||
| ```lisp | |||
| [(list . ?xs) | |||
| `(:constraints (list ,@(map (cut collect-constraints <> constrs) xs)) | |||
| ,constrs)] | |||
| ``` | |||
| Booleans are simpler: | |||
| ```lisp | |||
| [t `(:constraints ,'t ,constrs)] | |||
| [nil `(:constraints ,'nil ,constrs)] | |||
| ``` | |||
| Since there are no sub-expressions to go through, we only associate the | |||
| constraints with the boolean values. | |||
| Conditionals are where the real work happens. For each case, we add that | |||
| case's test as a constraint in its body. | |||
| ```lisp | |||
| [(cond . ?alts) | |||
| `(:constraints | |||
| (cond | |||
| ,@(map (lambda (x) | |||
| `(,(collect-constraints (car x) constrs) | |||
| ,(collect-constraints (cadr x) (cons (car x) constrs)))) | |||
| alts)) | |||
| ,constrs)] | |||
| ``` | |||
| Applications are as simple as lists. Note that we make no distinction | |||
| between valid applications and invalid ones, and just tag both. | |||
| ```lisp | |||
| [(?fn . ?args) | |||
| `(:constraints | |||
| (,(collect-constraints fn constrs) | |||
| ,@(map (cut collect-constraints <> constrs) | |||
| args)) | |||
| ,constrs)] | |||
| ``` | |||
| References are also straightforward: | |||
| ```lisp | |||
| [else `(:constraints ,expr ,constrs)])) | |||
| ``` | |||
| That's it! Now, this information can be exploited to select a case | |||
| branch at compile time, and eliminate the overhead of performing the | |||
| test again. | |||
| This is _really_ easy to do in a compiler that already has constant | |||
| folding of alternatives. All we have to do is associate constraints to | |||
| truthy values. For instance: | |||
| ```lisp | |||
| (defun fold-on-constraints (x) | |||
| (case x | |||
| [((:constraints ?e ?x) | |||
| :when (known? e x)) | |||
| 't] | |||
| [else x])) | |||
| ``` | |||
| That's it! We check if the expression is in the set of known | |||
| constraints, and if so, reduce it to true. Then, the constant folding | |||
| code will take care of eliminating the redundant branches. | |||
| ### When | |||
| This is a really complicated question. The Urn core language, | |||
| unfortunately, is a tad more complicated, as is the existing optimiser. | |||
| Collecting constraints and eliminating tests would be in completely | |||
| different parts of the compiler. | |||
| There is also a series of code motions that need to be in place for | |||
| constraints to be propagated optimally, especially when panic edges are | |||
| involved. Fortunately, these are all simple to implement, but it's still | |||
| a whole lot of work. | |||
| I don't feel confident setting a specific timeframe for this, but | |||
| I _will_ post more blags on this topic. It's fascinating (for me, at | |||
| least) and will hopefully make the compiler faster! | |||
| [^mr]: The relevant merge request can be found | |||
| [here](https://gitlab.com/urn/urn/issues/27). | |||
+ 280
- 0
pages/posts/2017-08-15-multimethods.md
View File
| @ -0,0 +1,280 @@ | |||
| --- | |||
| title: Multimethods in Urn | |||
| date: August 15, 2017 | |||
| --- | |||
| `multimethod`, noun. A procedure which decides runtime behaviour based | |||
| on the types of its arguments. | |||
| ### Introduction | |||
| At some point, most programming language designers realise that they've | |||
| outgrown the language's original feature set and must somehow expand it. | |||
| Sometimes, this expansion is painless for example, if the language had | |||
| already features in place to facilitate this, such as type classes or | |||
| message passing. | |||
| In our case, however, we had to decide on and implement a performant | |||
| system for extensibility in the standard library, from scratch. For | |||
| a while, Urn was using Lua's scheme for modifying the behaviour of | |||
| standard library functions: metamethods in metatables. For the | |||
| uninitiated, Lua tables can have _meta_-tables attached to modify their | |||
| behaviour with respect to several language features. As an example, the | |||
| metamethod `__add`{.lua} controls how Lua will add two tables. | |||
| However, this was not satisfactory, the most important reason as to why | |||
| being the fact that metamethods are associated with particular object | |||
| _instances_, instead of being associated with the _types_ themselves. | |||
| This meant that all the operations you'd like to modify had to be | |||
| modified in one big go - inside the constructor. Consider the | |||
| constructor for hash-sets as it was implemented before the addition of | |||
| multimethods. | |||
| ```lisp | |||
| (defun make-set (hash-function) | |||
| (let* [(hash (or hash-function id))] | |||
| (setmetatable | |||
| { :tag "set" | |||
| :hash hash | |||
| :data {} } | |||
| { :--pretty-print | |||
| (lambda (x) | |||
| (.. "«hash-set: " (concat (map pretty (set->list x)) " ") "»")) | |||
| :--compare #| elided for brevity |# }))) | |||
| ``` | |||
| That second table, the meta table, is entirely noise. The fact that | |||
| constructors also had to specify behaviour, instead of just data, was | |||
| annoying from a code style point of view and _terrible_ from a reuse | |||
| point of view. Behaviour is closely tied to the implementation - remember | |||
| that metamethods are tied to the _instance_. To extend the behaviour of | |||
| standard library functions (which you can't redefine) for a type you do | |||
| not control (whose constructor you also can not override), you suddenly | |||
| need to wrap the constructor and add your own metamethods. | |||
| ### Finding a Solution | |||
| Displeased with the situation as it stood, I set out to discover what | |||
| other Lisps did, and it seemed like the consensus solution was to | |||
| implement open multimethods. And so we did. | |||
| Multimethods - or multiple dispatch in general - is one of the best | |||
| solutions to the expression problem. We can easily add new types, and | |||
| new operations to work on existing types - and most importantly, this | |||
| means touching _no_ existing code. | |||
| Our implementation is, like almost everything in Urn, a combination of | |||
| clever (ab)use of macros, tables and functions. A method is represented | |||
| as a table - more specifically, a n-ary tree of possible cases, with | |||
| a metamethod, `__call`{.lua}, which means multimethods can be called and | |||
| passed around like regular functions - they are first-order. | |||
| Upon calling a multimethod, it'll look up the correct method body to | |||
| call for the given arguments - or the default method, or throw an error, | |||
| if no default method is provided - and tail-call that, with all the | |||
| arguments. | |||
| Before diving into the ridiculously simple implementation, let's look at | |||
| a handful of examples. | |||
| #### Pretty printing | |||
| Pretty printing is, quite possibly, the simplest application of multiple | |||
| dispatch to extensibility. As of | |||
| [`ba289d2d`](https://gitlab.com/urn/urn/commit/ba829d2de30e3b1bef4fa1a22a5e4bbdf243426b), | |||
| the standard library implementation of `pretty` is a multimethod. | |||
| Before, the implementation[^1] would perform a series of type tests and | |||
| decide on the behaviour, including testing if the given object had | |||
| a metatable which overrides the pretty-printing behaviour. | |||
| The new implementation is _significantly_ shorter, so much so that I'm | |||
| comfortable pasting it here. | |||
| ```lisp | |||
| (defgeneric pretty (x) | |||
| "Pretty-print a value.") | |||
| ``` | |||
| That's it! All of the logic that used to exist is now provided by the | |||
| `defgeneric` macro, and adding support for your types is as simple as | |||
| using `defmethod`.[^2] | |||
| ```lisp | |||
| (defmethod (pretty string) (x) | |||
| (format "%q" x)) | |||
| ``` | |||
| As another example, let's define - and assume the following are separate | |||
| modules - a new type, and add pretty printing support for that. | |||
| ```lisp | |||
| ; Module A - A box. | |||
| (defun box (x) | |||
| { :tag "box" | |||
| :value x }) | |||
| ``` | |||
| The Urn function `type` will look for a `tag` element in tables and | |||
| report that as the type if it is present, and that function is what the | |||
| multimethod infrastructure uses to determine the correct body to call. | |||
| This means that all we need to do if we want to add support for | |||
| pretty-printing boxes is use defmethod again! | |||
| ```lisp | |||
| (defmethod (pretty box) (x) "🎁") | |||
| ``` | |||
| #### Comparison | |||
| A more complicated application of multiple dispatch for extensibility is | |||
| the implementation of the `eq?` method in the standard library. | |||
| Before[^3], based on a series of conditionals, the equality test was | |||
| chosen at runtime. | |||
| Anyone with experience optimising code is wincing at the mere thought of | |||
| this code. | |||
| The new implementation of `eq?` is also comically short - a mere 2 lines | |||
| for the definition, and only a handful of lines for all the previously | |||
| existing cases. | |||
| ```lisp | |||
| (defgeneric eq? (x y) | |||
| "Compare values for equality deeply.") | |||
| (defmethod (eq? symbol symbol) (x y) | |||
| (= (get-idx x :contents) (get-idx y :contents))) | |||
| (defmethod (eq? string symbol) (x y) (= x (get-idx y :contents))) | |||
| (defmethod (eq? symbol string) (x y) (= (get-idx x :contents) y)) | |||
| ``` | |||
| If we would, as an example, add support for comparing boxes, the | |||
| implementation would similarly be short. | |||
| ```lisp | |||
| (defmethod (eq? box box) (x y) | |||
| (= (.> x :value) (.> y :value))) | |||
| ``` | |||
| ### Implementation | |||
| `defgeneric` and `defmethod` are, quite clearly, macros. However, | |||
| contrary to what one would expect, both their implementations are | |||
| _quite_ simple. | |||
| ```lisp | |||
| (defmacro defgeneric (name ll &attrs) | |||
| (let* [(this (gensym 'this)) | |||
| (method (gensym 'method))] | |||
| `(define ,name | |||
| ,@attrs | |||
| (setmetatable | |||
| { :lookup {} } | |||
| { :__call (lambda (,this ,@ll) | |||
| (let* [(,method (deep-get ,this :lookup ,@(map (lambda (x) | |||
| `(type ,x)) ll)))] | |||
| (unless ,method | |||
| (if (get-idx ,this :default) | |||
| (set! ,method (get-idx ,this :default)) | |||
| (error "elided for brevity"))) | |||
| (,method ,@ll))) })))) | |||
| ``` | |||
| Everything `defgeneric` has to do is define a top-level symbol to hold | |||
| the multimethod table, and generate, at compile time, a lookup function | |||
| specialised for the correct number of arguments. In a language without | |||
| macros, multimethod calls would have to - at runtime - loop over the | |||
| provided arguments, take their types, and access the correct elements in | |||
| the table. | |||
| As an example of how generating the lookup function at compile time is | |||
| better for performance, consider the (cleaned up[^4]) lookup function | |||
| generated for the `(eq?)` method defined above. | |||
| ```lua | |||
| function(this, x, y) | |||
| local method | |||
| if this.lookup then | |||
| local temp1 = this.lookup[type(x)] | |||
| if temp1 then | |||
| method = temp1[type(y)] or nil | |||
| else | |||
| method = nil | |||
| end | |||
| elseif this.default then | |||
| method = this.default | |||
| end | |||
| if not method then | |||
| error("No matching method to call for...") | |||
| end | |||
| return method(x, y) | |||
| end | |||
| ``` | |||
| `defmethod` and `defdefault` are very simple and uninteresting macros: | |||
| All they do is wrap the provided body in a lambda expression along with | |||
| the proper argument list and associate them to the correct element in | |||
| the tree. | |||
| ```lisp | |||
| (defmacro defmethod (name ll &body) | |||
| `(put! ,(car name) (list :lookup ,@(map s->s (cdr name))) | |||
| (let* [(,'myself nil)] | |||
| (set! ,'myself (lambda ,ll ,@body)) | |||
| ,'myself))) | |||
| ``` | |||
| ### Conclusion | |||
| Switching to methods instead of a big if-else chain improved compiler | |||
| performance by 12% under LuaJIT, and 2% under PUC Lua. The performace | |||
| increase under LuaJIT can be attributed to the use of polymorphic inline | |||
| caches to speed up dispatch, which is now just a handful of table | |||
| accesses - Doing it with the if-else chain is _much_ harder. | |||
| Defining complex multiple-dispatch methods used to be an unthinkable | |||
| hassle what with keeping straight which cases have been defined yet and | |||
| which cases haven't, but they're now very simple to define: Just state | |||
| out the number of arguments and list all possible cases. | |||
| The fact that multimethods are _open_ means that new cases can be added | |||
| on the fly, at runtime (though this is not officially supported, and we | |||
| don't claim responsibility if you shoot your own foot), and that modules | |||
| loaded later may improve upon the behaviour of modules loaded earlier. | |||
| This means less coupling between the standard library, which has been | |||
| growing to be quite large. | |||
| This change has, in my opinion, made Urn a lot more expressive as | |||
| a language, and I'd like to take a minute to point out the power of the | |||
| Lisp family in adding complicated features such as these as merely | |||
| library code: no changes were made to the compiler, apart from a tiny | |||
| one regarding environments in the REPL - previously, it'd use the | |||
| compiler's version of `(pretty)` even if the user had overridden it, | |||
| which wasn't a problem with the metatable approach, but definitely is | |||
| with the multimethod approach. | |||
| Of course, no solution is all _good_. Compiled code size has increased | |||
| a fair bit, and for the Urn compiler to inline across multimethod | |||
| boundaries would be incredibly difficult - These functions are | |||
| essentially opaque boxes to the compiler. | |||
| Dead code elimination is harder, what with defining functions now being | |||
| a side-effect to be performed at runtime - Telling which method cases | |||
| are or aren't used is incredibly difficult with the extent of the | |||
| dynamicity. | |||
| [^1]: | |||
| [Here](https://gitlab.com/urn/urn/blob/e1e9777498e1a7d690e3b39c56f616501646b5da/lib/base.lisp#L243-270). | |||
| Do keep in mind that the implementation is _quite_ hairy, and grew to be | |||
| like that because of our lack of a standard way of making functions | |||
| extensible. | |||
| [^2]: `%q` is the format specifier for quoted strings. | |||
| [^3]: | |||
| [Here](https://gitlab.com/urn/urn/blob/e1e9777498e1a7d690e3b39c56f616501646b5da/lib/type.lisp#L116-1420). | |||
| Do keep in mind that that the above warnings apply to this one, too. | |||
| [^4]: [The original generated code](/static/generated_code.lua.html) is | |||
| quite similar, except the generated variable names make it a tad harder | |||
| to read. | |||
+ 516
- 0
pages/posts/2017-09-08-dependent-types.md
View File
| @ -0,0 +1,516 @@ | |||
| --- | |||
| title: Dependent Types | |||
| date: September 08, 2017 | |||
| maths: true | |||
| --- | |||
| Dependent types are pretty cool, yo. This post is a semi-structured | |||
| ramble about [dtt](https://ahti-saarelainen.zgrep.org/git/hydraz/dtt), | |||
| a small dependently-typed "programming language" inspired by Thierry | |||
| Coquand's Calculus of (inductive) Constructions (though, note that the | |||
| _induction_ part is still lacking: There is support for defining | |||
| inductive data types, and destructuring them by pattern matching, but | |||
| since there's no totality checker, recursion is disallowed). | |||
| `dtt` is written in Haskell, and served as a learning experience both in | |||
| type theory and in writing programs using [extensible | |||
| effects](https://hackage.haskell.org/package/freer). I *do* partly regret | |||
| the implementation of effects I chose (the more popular | |||
| [`extensible-effects`](https://hackage.haskell.org/package/extensible-effects) | |||
| did not build on the Nixpkgs channel I had, so I went with `freer`; | |||
| Refactoring between these should be easy enough, but I still haven't | |||
| gotten around to it, yet) | |||
| I originally intended for this post to be a Literate Haskell file, | |||
| interleaving explanation with code. However, for a pet project, `dtt`'s | |||
| code base quickly spiralled out of control, and is now over a thousand | |||
| lines long: It's safe to say I did not expect this one bit. | |||
| ### The language | |||
| `dtt` is a very standard $\lambda_{\prod{}}$ calculus. We have all 4 axes of | |||
| Barendgret's lambda cube, in virtue of having types be first class | |||
| values: Values depending on values (functions), values depending on | |||
| types (polymorphism), types depending on types (type operators), and | |||
| types depending on values (dependent types). This places dtt squarely at | |||
| the top, along with other type theories such as the Calculus of | |||
| Constructions (the theoretical basis for the Coq proof assistant) and TT | |||
| (the type theory behind the Idris programming language). | |||
| The syntax is very simple. We have the standard lambda calculus | |||
| constructs - $\lambda$-abstraction, application and variables - along | |||
| with `let`{.haskell}-bindings, pattern matching `case` expression, and | |||
| the dependent type goodies: $\prod$-abstraction and `Set`{.haskell}. | |||
| _As an aside_, pi types are called as so because the dependent function | |||
| space may (if you follow the "types are sets of values" line of | |||
| thinking) be viewed as the cartesian product of types. Consider a type | |||
| `A`{.haskell} with inhabitants `Foo`{.haskell}, `Bar`{.haskell} and | |||
| a type `B`{.haskell} with inhabitant `Quux`{.haskell}. A dependent | |||
| product $\displaystyle\prod_{(x: \mathtt{A})}\mathtt{B}$, then, has | |||
| inhabitants `(Foo, Quux)`{.haskell} and `(Bar, Quux)`{.haskell}. | |||
| You'll notice that dtt does not have a dedicated arrow type. Indeed, the | |||
| dependent product subsumes both the $\forall$ quantifier of System $F$, | |||
| and the arrow type $\to$ of the simply-typed lambda calculus. Keep this | |||
| in mind: It'll be important later. | |||
| Since dtt's syntax is unified (i.e., there's no stratification of terms | |||
| and types), the language can be - and is - entirely contained in | |||
| a single algebraic data type. All binders are _explicitly typed_, seeing | |||
| as inference for dependent types is undecidable (and, therefore, | |||
| bad).[^1] | |||
| ```haskell | |||
| type Type = Term | |||
| data Term | |||
| = Variable Var | |||
| | Set Int | |||
| | TypeHint Term Type | |||
| | Pi Var Type Type | |||
| | Lam Var Type Term | |||
| | Let Var Term Term | |||
| | App Term Term | |||
| | Match Term [(Pattern, Term)] | |||
| deriving (Eq, Show, Ord) | |||
| ``` | |||
| The `TypeHint`{.haskell} term constructor, not mentioned before, is | |||
| merely a convenience: It allows the programmer to check their | |||
| assumptions and help the type checker by supplying a type (Note that we | |||
| don't assume this type is correct, as you'll see later; It merely helps | |||
| guide inference.) | |||
| Variables aren't merely strings because of the large amount of | |||
| substitutions we have to perform: For this, instead of generating a new | |||
| name, we increment a counter attached to the variable - the pretty | |||
| printer uses the original name to great effect, when unambiguous. | |||
| ```haskell | |||
| data Var | |||
| = Name String | |||
| | Refresh String Int | |||
| | Irrelevant | |||
| deriving (Eq, Show, Ord) | |||
| ``` | |||
| The `Irrelevant`{.haskell} variable constructor is used to support $a | |||
| \to b$ as sugar for $\displaystyle\prod_{(x: a)} b$ when $x$ does not | |||
| appear free in $b$. As soon as the type checker encounters an | |||
| `Irrelevant`{.haskell} variable, it is refreshed with a new name. | |||
| `dtt` does not have implicit support (as in Idris), so all parameters, | |||
| including type parameters, must be bound explicitly. For this, we | |||
| support several kinds of syntatic sugar. First, all abstractions support | |||
| multiple variables in a _binding group_. This allows the programmer to | |||
| write `(a, b, c : α) -> β` instead of `(a : α) -> (b : α) -> (c : α) -> | |||
| β`. Furthermore, there is special syntax `/\a` for single-parameter | |||
| abstraction with type `Set 0`{.haskell}, and lambda abstractions support | |||
| multiple binding groups. | |||
| As mentioned before, the language does not support recursion (either | |||
| general or well-founded). Though I would like to, writing a totality | |||
| checker is hard - way harder than type checking $\lambda_{\prod{}}$, in | |||
| fact. However, an alternative way of inspecting inductive values _does_ | |||
| exist: eliminators. These are dependent versions of catamorphisms, and | |||
| basically encode a proof by induction. An inductive data type as Nat | |||
| gives rise to an eliminator much like it gives rise to a natural | |||
| catamorphism. | |||
| ``` | |||
| inductive Nat : Type of { | |||
| Z : Nat; | |||
| S : Nat -> Nat | |||
| } | |||
| natElim : (P : Nat -> Type) | |||
| -> P Z | |||
| -> ((k : Nat) -> P k -> P (S k)) | |||
| -> (n : Nat) | |||
| -> P n | |||
| ``` | |||
| If you squint, you'll see that the eliminator models a proof by | |||
| induction (of the proposition $P$) on the natural number $n$: The type | |||
| signature basically states "Given a proposition $P$ on $\mathbb{N}$, | |||
| a proof of $P_0$, a proof that $P_{(k + 1)}$ follows from $P_k$ and | |||
| a natural number $n$, I'll give you a proof of $P_n$." | |||
| This understanding of computations as proofs and types as propositions, | |||
| by the way, is called the [Curry-Howard | |||
| Isomorphism](https://en.wikipedia.org/wiki/Curry-Howard_correspondence). | |||
| The regular, simply-typed lambda calculus corresponds to natural | |||
| deduction, while $\lambda_{\prod{}}$ corresponds to predicate logic. | |||
| ### The type system | |||
| Should this be called the term system? | |||
| Our type inference algorithm, contrary to what you might expect for such | |||
| a complicated system, is actually quite simple. Unfortunately, the code | |||
| isn't, and thus isn't reproduced in its entirety below. | |||
| #### Variables | |||
| The simplest case in any type system. The typing judgement that gives | |||
| rise to this case is pretty much the identity: $\Gamma \vdash \alpha: | |||
| \tau \therefore \Gamma \vdash \alpha: \tau$. If, from the current typing | |||
| context we know that $\alpha$ has type $\tau$, then we know that | |||
| $\alpha$ has type $\tau$. | |||
| ```haskell | |||
| Variable x -> do | |||
| ty <- lookupType x -- (I) | |||
| case ty of | |||
| Just t -> pure t -- (II) | |||
| Nothing -> throwError (NotFound x) -- (III) | |||
| ``` | |||
| 1. Look up the type of the variable in the current context. | |||
| 2. If we found a type for it, then return that (this is the happy path) | |||
| 3. If we didn't find a type for it, we raise a type error. | |||
| #### `Set`{.haskell}s | |||
| Since dtt has a cummulative hierarchy of universes, $\mathtt{Set}_k: | |||
| \mathtt{Set}_{(k + 1)}$. This helps us avoid the logical inconsistency | |||
| introduced by having _type-in-type_[^2], i.e. $\mathtt{Type}: | |||
| \mathtt{Type}$. We say that $\mathtt{Set}_0$ is the type of _small | |||
| types_: in fact, $\mathtt{Set}_0$ is where most computation actually | |||
| happens, seeing as $\mathtt{Set}_k$ for $k \ge 1$ is reserved for | |||
| $\prod$-abstractions quantifying over such types. | |||
| ```haskell | |||
| Set k -> pure . Set . (+1) $ k | |||
| ``` | |||
| #### Type hints | |||
| Type hints are the first appearance of the unification engine, by far | |||
| the most complex part of dtt's type checker. But for now, suffices to | |||
| know that ``t1 `assertEquality` t2``{.haskell} errors if the types t1 | |||
| and t2 can't be made to _line up_, i.e., unify. | |||
| For type hints, we infer the type of given expression, and compare it | |||
| against the user-provided type, raising an error if they don't match. | |||
| Because of how the unification engine works, the given type may be more | |||
| general (or specific) than the inferred one. | |||
| ```haskell | |||
| TypeHint v t -> do | |||
| it <- infer v | |||
| t `assertEquality` it | |||
| pure t | |||
| ``` | |||
| #### $\prod$-abstractions | |||
| This is where it starts to get interesting. First, we mandate that the | |||
| parameter type is inhabited (basically, that it _is_, in fact, a type). | |||
| The dependent product $\displaystyle\prod_{(x : 0)} \alpha$, while allowed by the | |||
| language's grammar, is entirely meaningless: There's no way to construct | |||
| an inhabitant of $0$, and thus this function may never be applied. | |||
| Then, in the context extended with $(\alpha : \tau)$, we require that | |||
| the consequent is also a type itself: The function | |||
| $\displaystyle\prod_{(x: \mathbb{N})} 0$, while again a valid parse, is | |||
| also meaningless. | |||
| The type of the overall abstraction is, then, the maximum value of the | |||
| indices of the universes of the parameter and the consequent. | |||
| ```haskell | |||
| Pi x p c -> do | |||
| k1 <- inferSet tx | |||
| k2 <- local (insertType (x, p)) $ | |||
| inferSet c | |||
| pure $ Set (k1 `max` k2) | |||
| ``` | |||
| #### $\lambda$-abstractions | |||
| Much like in the simply-typed lambda calculus, the type of | |||
| a $\lambda$-abstraction is an arrow between the type of its parameter | |||
| and the type of its body. Of course, $\lambda_{\prod{}}$ incurs the | |||
| additional constraint that the type of the parameter is inhabited. | |||
| Alas, we don't have arrows. So, we "lift" the lambda's parameter to the | |||
| type level, and bind it in a $\prod$-abstraction. | |||
| ```haskell | |||
| Lam x t b -> do | |||
| _ <- inferSet t | |||
| Pi x t <$> local (insertType (x, t)) (infer b) | |||
| ``` | |||
| Note that, much like in the `Pi`{.haskell} case, we type-check the body | |||
| in a context extended with the parameter's type. | |||
| #### Application | |||
| Application is the most interesting rule, as it has to not only handle | |||
| inference, it also has to handle instantiation of $\prod$-abstractions. | |||
| Instantation is, much like application, handled by $\beta$-reduction, | |||
| with the difference being that instantiation happens during type | |||
| checking (applying a $\prod$-abstraction is meaningless) and application | |||
| happens during normalisation (instancing a $\lambda$-abstraction is | |||
| meaningless). | |||
| The type of the function being applied needs to be | |||
| a $\prod$-abstraction, while the type of the operand needs to be | |||
| inhabited. Note that the second constraint is not written out | |||
| explicitly: It's handled by the `Pi`{.haskell} case above, and | |||
| furthermore by the unification engine. | |||
| ```haskell | |||
| App e1 e2 -> do | |||
| t1 <- infer e1 | |||
| case t1 of | |||
| Pi vr i o -> do | |||
| t2 <- infer e2 | |||
| t `assertEquality` i | |||
| N.normalise =<< subst [(vr, e2)] o -- (I) | |||
| e -> throwError (ExpectedPi e) -- (II) | |||
| ``` | |||
| 1. Notice that, here, we don't substitute the $\prod$-bound variable by | |||
| the type of $e_2$: That'd make us equivalent to System $F$. The whole | |||
| _deal_ with dependent types is that types depend on values, and that | |||
| entirely stems from this one line. By instancing a type variable with | |||
| a value, we allow _types_ to depend on _values_. | |||
| 2. Oh, and if we didn't get a $\prod$-abstraction, error. | |||
| --- | |||
| You'll notice that two typing rules are missing here: One for handling | |||
| `let`{.haskell}s, which was not included because it is entirely | |||
| uninteresting, and one for `case ... of`{.haskell} expressions, which | |||
| was redacted because it is entirely a mess. | |||
| Hopefully, in the future, the typing of `case` expressions is simpler | |||
| - if not, they'll probably be replaced by eliminators. | |||
| ### Unification and Constraint Solving | |||
| The unification engine is the man behind the curtain in type checking: | |||
| We often don't pay attention to it, but it's the driving force behind it | |||
| all. Fortunately, in our case, unification is entirely trivial: Solving | |||
| is the hard bit. | |||
| The job of the unification engine is to produce a set of constraints | |||
| that have to be satisfied in order for two types to be equal. Then, the | |||
| solver is run on these constraints to assert that they are logically | |||
| consistent, and potentially produce substitutions that _reify_ those | |||
| constraints. | |||
| Our solver isn't that cool, though, so it just verifies consitency. | |||
| The kinds of constraints we can generate are as in the data type below. | |||
| ```haskell | |||
| data Constraint | |||
| = Instance Var Term -- (1) | |||
| | Equal Term Term -- (2) | |||
| | EqualTypes Type Type -- (3) | |||
| | IsSet Type -- (4) | |||
| deriving (Eq, Show, Ord) | |||
| ``` | |||
| 1. The constraint `Instance v t`{.haskell} corresponds to a substitution | |||
| between `v` and the term `t`. | |||
| 2. A constraint `Equal a b`{.haskell} states that the two terms `a` and | |||
| `b` are equal under normalisation. | |||
| 3. Ditto, but with their _types_ (We normalise, infer, and check for | |||
| equality) | |||
| 4. A constraint `IsSet t`{.haskell} asserts that the provided type has | |||
| inhabitants. | |||
| #### Unification | |||
| Unification of most terms is entirely uninteresting. Simply line up the | |||
| structures and produce the appropriate equality (or instance) | |||
| constraints. | |||
| ```haskell | |||
| unify (Variable a) b = instanceC a b | |||
| unify b (Variable a) = instanceC a b | |||
| unify (Set a) (Set b) | a == b = pure [] | |||
| unify (App x y) (App x' y') = | |||
| (++) <$> unify x x' <*> unify y y' | |||
| unify (TypeHint a b) (TypeHint c d) = | |||
| (++) <$> unify a c <*> unify b d | |||
| unify a b = throwError (NotEqual a b) | |||
| ``` | |||
| Those are all the boring cases, and I'm not going to comment on them. | |||
| Similarly boring are binders, which were abstracted out because hlint | |||
| told me to. | |||
| ```haskell | |||
| unify (Lam v1 t1 b1) (Lam v2 t2 b2) = unifyBinder (v1, v2) (t1, t2) (b1, b2) | |||
| unify (Pi v1 t1 b1) (Pi v2 t2 b2) = unifyBinder (v1, v2) (t1, t2) (b1, b2) | |||
| unify (Let v1 t1 b1) (Let v2 t2 b2) = unifyBinder (v1, v2) (t1, t2) (b1, b2) | |||
| unifyBinder (v1, v2) (t1, t2) (b1, b2) = do | |||
| (a, b) <- (,) <$> unify (Variable v1) (Variable v2) <*> unify t1 t2 | |||
| ((a ++ b) ++) <$> unify b1 b2 | |||
| ``` | |||
| There are two interesting cases: Unification between some term and a pi | |||
| abstraction, and unification between two variables. | |||
| ```haskell | |||
| unify ta@(Variable a) tb@(Variable b) | |||
| | a == b = pure [] | |||
| | otherwise = do | |||
| (x, y) <- (,) <$> lookupType a <*> lookupType b | |||
| case (x, y) of | |||
| (Just _, Just _) -> do | |||
| ca <- equalTypesC ta tb | |||
| cb <- equalC ta tb | |||
| pure (ca ++ cb) | |||
| (Just x', Nothing) -> instanceC b x' | |||
| (Nothing, Just x') -> instanceC a x' | |||
| (Nothing, Nothing) -> instanceC a (Variable b) | |||
| ``` | |||
| If the variables are syntactically the same, then we're done, and no | |||
| constraints have to be generated (Technically you could generate an | |||
| entirely trivial equality constraint, but this puts unnecessary pressure | |||
| on the solver). | |||
| If either variable has a known type, then we generate an instance | |||
| constraint between the unknown variable and the known one. | |||
| If both variables have a value, we equate their types' types and their | |||
| types. This is done mostly for error messages' sakes, seeing as if two | |||
| values are propositionally equal, so are their types. | |||
| Unification between a term and a $\prod$-abstraction is the most | |||
| interesting case: We check that the $\prod$ type abstracts over a type | |||
| (i.e., it corresponds to a System F $\forall$ instead of a System | |||
| F $\to$), and _instance_ the $\prod$ with a fresh type variable. | |||
| ```haskell | |||
| unifyPi v1 t1 b1 a = do | |||
| id <- refresh Irrelevant | |||
| ss <- isSetC t1 | |||
| pi' <- subst [(v1, Variable id)] b1 | |||
| (++ ss) <$> unify a pi' | |||
| unify a (Pi v1 t1 b1) = unifyPi v1 t1 b1 a | |||
| unify (Pi v1 t1 b1) a = unifyPi v1 t1 b1 a | |||
| ``` | |||
| #### Solving | |||
| Solving is a recursive function of the list of constraints (a | |||
| catamorphism!) with some additional state: Namely, a strict map of | |||
| already-performed substitutions. Let's work through the cases in reverse | |||
| order of complexity (and, interestingly, reverse order of how they're in | |||
| the source code). | |||
| ##### No constraints | |||
| Solving an empty list of constraints is entirely trivial. | |||
| ```haskell | |||
| solveInner _ [] = pure () | |||
| ``` | |||
| #### `IsSet`{.haskell} | |||
| We infer the index of the universe of the given type, much like in the | |||
| inferrence case for $\prod$-abstractions, and check the remaining | |||
| constraints. | |||
| ```haskell | |||
| solveInner map (IsSet t:xs) = do | |||
| _ <- inferSet t | |||
| solveInner map xs | |||
| ``` | |||
| #### `EqualTypes`{.haskell} | |||
| We infer the types of both provided values, and generate an equality | |||
| constraint. | |||
| ```haskell | |||
| solveInner map (EqualTypes a b:xs) = do | |||
| ta <- infer a | |||
| tb <- infer b | |||
| solveInner map (Equal ta tb:xs) | |||
| ``` | |||
| #### `Equal`{.haskell} | |||
| We merely have to check for syntactic equality of the (normal forms of) | |||
| terms, because the hard lifting of destructuring and lining up was done | |||
| by the unification engine. | |||
| ```haskell | |||
| solveInner map (Equal a b:xs) = do | |||
| a' <- N.normalise a | |||
| b' <- N.normalise b | |||
| eq <- equal a' b' | |||
| if eq | |||
| then solveInner map xs | |||
| else throwError (NotEqual a b) | |||
| ``` | |||
| #### `Instance`{.haskell} | |||
| If the variable we're instancing is already in the map, and the thing | |||
| we're instancing it to _now_ is not the same as before, we have an | |||
| inconsistent set of substitutions and must error. | |||
| ```haskell | |||
| solveInner map (Instance a b:xs) | |||
| | a `M.member` map | |||
| , b /= map M.! a | |||
| , Irrelevant /= a | |||
| = throwError $ InconsistentSubsts (a, b) (map M.! a) | |||
| ``` | |||
| Otherwise, if we have a coherent set of instances, we add the instance | |||
| both to scope and to our local state map and continue checking. | |||
| ```haskell | |||
| | otherwise = | |||
| local (insertType (a, b)) $ | |||
| solveInner (M.insert a b map) xs | |||
| ``` | |||
| --- | |||
| Now that we have both `unify` and `solve`, we can write | |||
| `assertEquality`: We unify the two types, and then try to solve the set | |||
| of constraints. | |||
| ```haskell | |||
| assertEquality t1 t2 = do | |||
| cs <- unify t1 t2 | |||
| solve cs | |||
| ``` | |||
| The real implementation will catch and re-throw any errors raised by | |||
| `solve` to add appropriate context, and that's not the only case where | |||
| "real implementation" and "blag implementation" differ. | |||
| ### Conclusion | |||
| Wow, that was a lot of writing. This conclusion begins on exactly the | |||
| 500th line of the Markdown source of this article, and this is the | |||
| longest article on this blag (by far). However, that's not to say it's | |||
| bad: It was amazing to write, and writing `dtt` was also amazing. I am | |||
| not good at conclusions. | |||
| `dtt` is available under the BSD 3-clause licence, though I must warn | |||
| you that the source code hasn't many comments. | |||
| I hope you learned nearly as much as I did writing this by reading it. | |||
| [^1]: As [proven](https://link.springer.com/chapter/10.1007/BFb0037103) by Gilles Dowek. | |||
| [^2]: See [System U](https://en.wikipedia.org/wiki/System_U), also | |||
| Girard's paradox - the type theory equivalent of [Russell's | |||
| paradox](https://en.wikipedia.org/wiki/Russell%27s_paradox). | |||
+ 456
- 0
pages/posts/2018-01-18-amulet.md
View File
| @ -0,0 +1,456 @@ | |||
| --- | |||
| title: The Amulet Programming Language | |||
| date: January 18, 2018 | |||
| --- | |||
| As you might have noticed, I like designing and implementing programming | |||
| languages. This is another of these projects. Amulet is a | |||
| strictly-evaluated, statically typed impure roughly functional | |||
| programming language with support for parametric data types and rank-1 | |||
| polymorphism _à la_ Hindley-Milner (but [no | |||
| let-generalization](#letgen)), along with row-polymorphic records. While | |||
| syntactically inspired by the ML family, it's a disservice to those | |||
| languages to group Amulet with them, mostly because of the (present) | |||
| lack of modules. | |||
| Planned features (that I haven't even started working on, as of writing | |||
| this post) include generalized algebraic data types, modules and modular | |||
| implicits, a reworked type inference engine based on _OutsideIn(X)_[^4] | |||
| to support the other features, and, perhaps most importantly, a back-end | |||
| that's not a placeholder (i.e. something that generates either C or LLVM | |||
| and can be compiled to a standalone executable). | |||
| The compiler is still very much a work in progress, and is actively | |||
| being improved in several ways: Rewriting the parser for efficiency | |||
| concerns (see [Lexing and Parsing](#parser)), improving the quality of | |||
| generated code by introducing more intermediate representations, and | |||
| introducing several optimisations on the one intermediate language we | |||
| _do_ have. | |||
| ## The Technical Bits | |||
| In this section, I'm going to describe the implementation of the | |||
| compiler as it exists at the time of writing - warts and all. | |||
| Unfortunately, we have a bit too much code for all of it to fit in this | |||
| blag post, so I'm only going to include the horribly broken bits here, | |||
| and leave the rest out. Of course, the compiler is open source, and is | |||
| available on my [GitHub][2]. | |||
| ### Lexing and Parsing {#parser} | |||
| To call what we have a _lexer_ is a bit of an overstatement: The | |||
| `Parser.Lexer` module, which underpins the actual parser, contains only | |||
| a handful of imports and some definitions for use with [Parsec's][3] | |||
| [`Text.Parsec.Token`][4] module; Everything else is boilerplate, namely, | |||
| declaring, at top-level, the functions generated by `makeTokenParser`. | |||
| Our parser is then built on top of this infrastructure (and the other | |||
| combinators provided by Parsec) in a monadic style. Despite having | |||
| chosen to use strict `Text`s, many of the Parsec combinators return | |||
| `Char`s, and using the Alternative type class' ability to repeat actions | |||
| makes linked lists of these - the dreaded `String` type. Due to this, | |||
| and other inefficiencies, the parser is ridiculously bad at memory | |||
| management. | |||
| However, it does have some cute hacks. For example, the pattern parser | |||
| has to account for being used in the parsing of both `match`{.ml} and | |||
| `fun`{.ml} - in the former, destructuring patterns may appear without | |||
| parenthesis, but in the latter, they _must_ be properly parenthesised: | |||
| since `fun`{.ml} may have multiple patterns, it would be ambiguous if | |||
| `fun Foo x -> ...`{.ml} is destructuring a `Foo` or takes two arguments. | |||
| Instead of duplicating the pattern parser, one for `match`{.ml}es and | |||
| one for function arguments, we instead _parametrised_ the parser over | |||
| needing parenthesis or not by adding a rank-2 polymorphic continuation | |||
| argument. | |||
| ```haskell | |||
| patternP :: (forall a. Parser a -> Parser a) -> Parser Pattern' | |||
| patternP cont = wildcard <|> {- some bits omitted -} try destructure where | |||
| destructure = withPos . cont $ do | |||
| ps <- constrName | |||
| Destructure ps <$> optionMaybe (patternP id) | |||
| ``` | |||
| When we're parsing a pattern `match`{.ml}-style, the continuation given | |||
| is `id`, and when we're parsing an argument, the continuation is | |||
| `parens`. | |||
| For the aforementioned efficiency concerns, however, we've decided to | |||
| scrap the Parsec-based parser and move to an Alex/Happy based solution, | |||
| which is not only going to be more maintainable and more easily hackable | |||
| in the future, but will also be more efficient overall. Of course, for | |||
| a toy compiler such as this one, efficiency doesn't matter that much, | |||
| but using _one and a half gigabytes_ to compile a 20-line file is really | |||
| bad. | |||
| ### Renaming {#renamer} | |||
| To simplify scope handling in both the type checker and optimiser, after | |||
| parsing, each variable is tagged with a globally unique integer that is | |||
| enough to compare variables. This also lets us use more efficient data | |||
| structures later in the compiler, such as `VarSet`, which stores only the | |||
| integer identifier of a variable in a big-endian Patricia tree[^1]. | |||
| Our approach, described in _[Secrets of the Glasgow Haskell Compiler | |||
| inliner][5]_ as "the Sledgehammer", consists of duplicating _every_ | |||
| bound variable to avoid name capture problems. However, while the first | |||
| of the listed disadvantages surely does apply, by doing all of the | |||
| _renaming_ in one go, we mostly avoid the latter. Of course, since then, | |||
| the Haskell ecosystem has evolved significantly, and the plumbing | |||
| required is a lot less intrusive. | |||
| In our compiler, we use MTL-style classes instead of concrete monad | |||
| transformer stacks. We also run every phase after parsing in a single | |||
| `GenT`{.haskell} monad, which provides a fresh supply of integers for | |||
| names. "Plumbing" the fresh name supply, then, only involves adding a | |||
| `MonadGen Int m` constraint to the context of functions that need it. | |||
| Since the string component of parsed names is not thrown away, we also | |||
| have to make up strings themselves. This is where another cute hack | |||
| comes in: We generate, lazily, an infinite stream of names that goes | |||
| `["a" .. "z", "aa" .. "az", "ba" .. "bz", ..]`, then use the | |||
| `MonadGen`{.haskell} counter as an index into that stream. | |||
| ```haskell | |||
| alpha :: [Text] | |||
| alpha = map T.pack $ [1..] >>= flip replicateM ['a'..'z'] | |||
| ``` | |||
| ### Desugaring | |||
| The desugarer is a very simple piece of code which, through use of _Scrap | |||
| Your Boilerplate_-style generic programming, traverses the syntax tree | |||
| and rewrites nodes representing syntax sugar to their more explicit | |||
| versions. | |||
| Currently, the desugarer only expands _sections_: That is, expressions | |||
| of the form `(+ e)` become `fun x -> x + e` (where `e` is a fresh name), | |||
| expressions like `(e +)` become `fun x -> e + x`, and expressions like | |||
| `.foo` becomes `fun x -> x.foo`. | |||
| This is the only component of the compiler that I can reasonably | |||
| include, in its entirety, in this post. | |||
| ```haskell | |||
| desugarProgram = everywhereM (mkM defaults) where | |||
| defaults :: Expr Parsed -> m (Expr Parsed) | |||
| defaults (BothSection op an) = do | |||
| (ap, ar) <- fresh an | |||
| (bp, br) <- fresh an | |||
| pure (Fun ap (Fun bp (BinOp ar op br an) an) an) | |||
| defaults (LeftSection op vl an) = do | |||
| (cap, ref) <- fresh an | |||
| pure (Fun cap (BinOp ref op vl an) an) | |||
| defaults (RightSection op vl an) = do | |||
| (cap, ref) <- fresh an | |||
| pure (Fun cap (BinOp vl op ref an) an) | |||
| defaults (AccessSection key an) = do | |||
| (cap, ref) <- fresh an | |||
| pure (Fun cap (Access ref key an) an) | |||
| defaults x = pure x | |||
| ``` | |||
| ### Type Checking | |||
| By far the most complicated stage of the compiler pipeline, our | |||
| inference algorithm is modelled after Algorithm W (extended with kinds | |||
| and kind inference), with constraint generation and solving being two | |||
| separate steps. | |||
| We first traverse the syntax tree, in order, making up constraints and | |||
| fresh type variables as needed, then invoke a unification algorithm to | |||
| produce a substitution, then apply that over both the generated type (a | |||
| skeleton of the actual result) and the syntax tree (which is explicitly | |||
| annotated with types everywhere). | |||
| The type inference code also generates and inserts explicit type | |||
| applications when instancing polymorphic types, since we internally | |||
| lower Amulet into a System F core language with explicit type | |||
| abstraction and application. We have `TypeApp` nodes in the syntax tree | |||
| that never get parsed or renamed, and are generated by the type checker | |||
| before lowering happens. | |||
| Our constraint solver is quite rudimentary, but it does the job nicely. | |||
| We operate with a State monad with the current substitution. When we | |||
| unify a variable with another type, it is added to the current | |||
| substitution. Everything else is just zipping the types together. When | |||
| we try to unify, say, a function type with a constructor, that's an | |||
| error. If a variable has already been added to the current substitution and | |||
| encounter it again, the new type is unified with the previously recorded | |||
| one. | |||
| ```haskell | |||
| unify :: Type Typed -> Type Typed -> SolveM () | |||
| unify (TyVar a) b = bind a b | |||
| unify a (TyVar b) = bind b a | |||
| unify (TyArr a b) (TyArr a' b') = unify a a' *> unify b b' | |||
| unify (TyApp a b) (TyApp a' b') = unify a a' *> unify b b' | |||
| unify ta@(TyCon a) tb@(TyCon b) | |||
| | a == b = pure () | |||
| | otherwise = throwError (NotEqual ta tb) | |||
| ``` | |||
| This is only an excerpt, because we have very complicated types. | |||
| #### Polymorphic Records | |||
| One of Amulet's selling points (if one could call it that) is its support | |||
| for row-polymorphic records. We have two types of first-class record | |||
| types: _closed_ record types (the type of literals) and _open_ record | |||
| types (the type inferred by record patterns and field getters.). Open | |||
| record types have the shape `{ 'p | x_n : t_n ... x_n : t_n }`{.ml}, | |||
| while closed records lack the type variable `'p`{.ml}. | |||
| Unification of records has 3 cases, but in all 3 cases it is checked that | |||
| fields present in both records have unifiable types. | |||
| - When unifying an open record with a closed one, present in both | |||
| records have unifiable types, and instance the type variable to contain | |||
| the extra fields. | |||
| - When unifying two closed records, they must have exactly the same | |||
| shape and unifiable types for common fields. | |||
| - When unifying two open record types, a new fresh type variable is | |||
| created to use as the "hole" and tack the fields together. | |||
| As an example, `{ x = 1 }` has type `{ x : int }`{.ml}, the function | |||
| `fun x -> x.foo` has type `{ 'p | foo : 'a } -> 'a`{.ml}, and | |||
| `(fun r -> r.x) { y = 2 }` is a type error[^2]. | |||
| #### No Let Generalisation {#letgen} | |||
| Vytiniotis, Peyton Jones and Schrijvers argue[^5] that HM-style | |||
| `let`{.ml} generalisation interacts badly with complex type system | |||
| extensions such as GADTs and type families, and should therefore be | |||
| omitted from such systems. In a deviation from the paper, GHC 7.2 | |||
| reintroduces `let`{.ml} generalisation for local definitions that meet | |||
| some criteria[^3]. | |||
| > Here's the rule. With `-XMonoLocalBinds` (the default), a binding | |||
| > without a type signature is **generalised only if all its free variables | |||
| > are closed.** | |||
| > | |||
| > A binding is **closed** if and only if | |||
| > | |||
| > - It has a type signature, and the type signature has no free variables; or | |||
| > - It has no type signature, and all its free variables are closed, and it | |||
| is unaffected by the monomorphism restriction. And hence it is fully | |||
| generalised. | |||
| We, however, have chosen to follow that paper to a tee. Despite not | |||
| (yet!) having any of those fancy type system features that interact | |||
| poorly with let generalisation, we do not generalise _any_ local | |||
| bindings. | |||
| ### Lowering | |||
| After type checking is done (and, conveniently, type applications have | |||
| been left in the correct places for us by the type checker), Amulet code | |||
| is converted into an explicitly-typed intermediate representation, in | |||
| direct style, which is used for (local) program optimisation. The AST is | |||
| simplified considerably: from 19 constructors to 9. | |||
| Type inference is no longer needed: the representation of core is packed | |||
| with all the information we need to check that programs are | |||
| type-correct. This includes types in every binder (lambda abstractions, | |||
| `let`{.ml}s, pattern bindings in `match`{.ml}), big-lambda abstractions | |||
| around polymorphic values (a $\lambda$ binds a value, while a $\Lambda$ | |||
| binds a type), along with the already mentioned type applications. | |||
| Here, code also gets the error branches for non-exhaustive `match`{.ml} | |||
| expressions, and, as a general rule, gets a lot uglier. | |||
| ```ocaml | |||
| let main _ = (fun r -> r.x) { x = 2 } | |||
| (* Is elaborated into *) | |||
| let main : ∀ 'e. 'e -> int = | |||
| Λe : *. λk : 'e. match k { | |||
| (p : 'e) : 'e -> (λl : { 'g | x : int }. match l { | |||
| (r : { 'g | x : int }) : { 'g | x : int } -> match r { | |||
| { (n : { 'g | x : int }) | x = (m : int) } : { 'g | x : int } -> m | |||
| }; | |||
| (o : { 'g | x : int }) : { 'g | x : int } -> | |||
| error @int "<test>[1:15 .. 1:27]" | |||
| }) ({ {} | x : int = 2 }); | |||
| (q : 'e) : 'e -> error @int "<test>[1:14 .. 1:38]" | |||
| } | |||
| ``` | |||
| ### Optimisation | |||
| As the code we initially get from lowering is ugly and inefficient - | |||
| along with being full of the abstractions functional programs have by | |||
| nature, it is full of redundant matches created by e.g. the fact that | |||
| functions can not do pattern matching directly, and that field access | |||
| gets reduced to pattern matching - the optimiser's job is to make it | |||
| prettier, and more efficient. | |||
| The optimiser works by applying, in order, a series of local | |||
| transformations operating on individual sub-terms to produce an efficient | |||
| program, 25 times. The idea of applying them several times is that, when | |||
| a simplification pass kicks in, more simplification opportunities might | |||
| arise. | |||
| #### `dropBranches`, `foldExpr`, `dropUselessLets` | |||
| These trivial passes remove similarly trivial pieces of code that only | |||
| add noise to the program. `dropBranches` will do its best to remove | |||
| redundant arms from a `match`{.ml} expression, such as those that | |||
| appear after an irrefutable pattern. `foldExpr` reduces uses of | |||
| operators where both sides are known, e.g. `2 + 2` (replaced by the | |||
| literal `5`) or `"foo " ^ "bar"` (replaced by the literal `"foo | |||
| bar"`). `dropUselessLets` removes `let`{.ml}s that bind unused variables | |||
| whose right-hand sides are pure expressions. | |||
| #### `trivialPropag`, `constrPropag` | |||
| The Amulet optimiser does inlining decisions in two (well, three) | |||
| separate phases: One is called _propagation_, in which a `let` decides | |||
| to propagate its bound values into the expression, and the other is the | |||
| more traditional `inlining`, where variables get their values from the | |||
| context. | |||
| Propagation is by far the easiest of the two: The compiler can see both | |||
| the definitions and all of the use sites, and could in theory decide if | |||
| propagating is beneficial or not. Right now, we propagate all literals | |||
| (and records made up solely of other trivial expressions), and do a | |||
| round of propagation that is best described as a rule. | |||
| ```ocaml | |||
| let { v = C e } in ... v ... | |||
| (* becomes *) | |||
| let { v' = e } in ... C v' ... | |||
| ``` | |||
| This _constructor propagation_ allows the `match`{.ml} optimisations to kick | |||
| in more often, and is semantics preserving. | |||
| #### `match`{.ml}-of-known-constructor | |||
| This pass identifies `match`{.ml} expressions where we can statically | |||
| determine the expression being analysed and, therefore, decide which | |||
| branch is going to be taken. | |||
| ```ocaml | |||
| match C x with | |||
| | C e -> ... e ... | |||
| ... | |||
| (* becomes *) | |||
| ... x ... | |||
| ``` | |||
| #### `match`{.ml}-of-bottom | |||
| It is always safe to turn a `match`{.ml} where the term being matched is a | |||
| diverging expression into only that diverging expression, thus reducing | |||
| code size several times. | |||
| ```ocaml | |||
| match (error @int "message") with ... | |||
| (* becomes *) | |||
| error @int "message" | |||
| ``` | |||
| As a special case, when one of the arms is itself a diverging | |||
| expression, we use the type mentioned in that application to `error` to | |||
| fix up the type of the value being scrutinized. | |||
| ```ocaml | |||
| match (error @foo "message") with | |||
| | _ -> error @bar "message 2" | |||
| ... | |||
| (* becomes *) | |||
| error @bar "message" | |||
| ``` | |||
| #### `match`{.ml}-of-`match`{.ml} | |||
| This transformation turns `match`{.ml} expressions where the expression | |||
| being dissected is itself another `match`{.ml} "inside-out": we push the | |||
| branches of the _outer_ `match`{.ml} "into" the _inner_ `match` (what | |||
| used to be the expression being scrutinized). In doing so, sometimes, | |||
| new opportunities for match-of-known-constructor arise, and the code | |||
| ends up simpler. | |||
| ```ocaml | |||
| match (match x with | |||
| | A -> B | |||
| | C -> D) with | |||
| | B -> e | |||
| | D -> f | |||
| (* becomes *) | |||
| match x with | |||
| | A -> match B with | |||
| | B -> e | |||
| | D -> f | |||
| | C -> match D with | |||
| | B -> e | |||
| | D -> f | |||
| ``` | |||
| A clear area of improvement here is extracting the outer branches into | |||
| local `let`{.ml}-bound lambda abstractions to avoid an explosion in code | |||
| size. | |||
| #### `inlineVariable`, `betaReduce` | |||
| In this pass, use of a variable is replaced with the definition of that | |||
| variable, if it meets the following conditions: | |||
| - The variable is a lambda abstraction; and | |||
| - The lambda abstraction's body is not too _expensive_. Computing the | |||
| cost of a term boils down to computing the depth of the tree | |||
| representing that term, with some extra cost added to some specific | |||
| types of expression. | |||
| In doing this, however, we end up with pathological terms of the form | |||
| `(fun x -> e) y`{.ml}. The `betaReduce` pass turns this into `let x = y in | |||
| e`{.ml}. We generate `let`{.ml} bindings instead of substituting the | |||
| variable with the parameter to maintain the same evaluation order and | |||
| observable effects of the original code. This does mean that, often, | |||
| propagation kicks in and gives rise to new simplification opportunities. | |||
| ## Epilogue | |||
| I was planning to write a section with a formalisation of the language's | |||
| semantics and type system, but it turns out I'm no mathematician, no | |||
| matter how hard I pretend. Maybe in the future. | |||
| Our code generator is wholly uninteresting, and, most of all, a | |||
| placeholder: This is why it is not described in detail (that is, at all) | |||
| in this post. I plan to write a follow-up when we actually finish the | |||
| native code generator. | |||
| As previously mentioned, the compiler _is_ open source: the code is | |||
| [here][2]. I recommend using the [Nix package manager][9] to acquire the | |||
| Haskell dependencies, but Cabal should work too. Current work in | |||
| rewriting the parser is happening in the `feature/alex-happy` branch. | |||
| [^1]: This sounds fancy, but in practice, it boils down to using | |||
| `Data.IntSet`{.haskell} instead of `Data.Set`{.haskell}. | |||
| [^2]: As shown [here][6]. Yes, the error messages need improvement. | |||
| [^3]: As explained in [this blog post][8]. | |||
| [^4]: Dimitrios Vytiniotis, Simon Peyton Jones, Tom Schrijvers, | |||
| and Martin Sulzmann. 2011. [OutsideIn(X): Modular Type Inference With | |||
| Local Assumptions][1]. _Note that, although the paper has been | |||
| published in the Journal of Functional Programming, the version linked | |||
| to here is a preprint._ | |||
| [^5]: Dimitrios Vytiniotis, Simon Peyton Jones, Tom Schrijvers. 2010. | |||
| [Let Should not be Generalised][7]. | |||
| [1]: <https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/jfp-outsidein.pdf> | |||
| [2]: <https://github.com/zardyh/amulet/tree/66a4143af32c3e261af51b74f975fc48c0155dc8> | |||
| [3]: <https://hackage.haskell.org/package/parsec-3.1.11> | |||
| [4]: <https://hackage.haskell.org/package/parsec-3.1.11/docs/Text-Parsec-Token.html> | |||
| [5]: <https://www.microsoft.com/en-us/research/wp-content/uploads/2002/07/inline.pdf> | |||
| [6]: </snip/sel.b0e94.txt> | |||
| [7]: <https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/tldi10-vytiniotis.pdf> | |||
| [8]: <https://ghc.haskell.org/trac/ghc/blog/LetGeneralisationInGhc7> | |||
| [9]: <https://nixos.org/nix/> | |||
+ 609
- 0
pages/posts/2018-02-18-amulet-tc2.md
View File
| @ -0,0 +1,609 @@ | |||
| --- | |||
| title: Amulet's New Type Checker | |||
| date: February 18, 2018 | |||
| --- | |||
| In the last post about Amulet I wrote about rewriting the type checking | |||
| code. And, to everybody's surprise (including myself), I actually did | |||
| it. | |||
| Like all good programming languages, Amulet has a strong, static type | |||
| system. What most other languages do not have, however, is (mostly) | |||
| _full type inference_: programs are still type-checked despite (mostly) | |||
| having no type annotations. | |||
| Unfortunately, no practical type system has truly "full type inference": | |||
| features like data-type declarations, integral to actually writing | |||
| software, mandate some type annotations (in this case, constructor | |||
| arguments). However, that doesn't mean we can't try. | |||
| The new type checker, based on a constraint-generating but | |||
| _bidirectional_ approach, can type a lot more programs than the older, | |||
| Algorithm W-derived, quite buggy checker. As an example, consider the | |||
| following definition. For this to check under the old type system, one | |||
| would need to annotate both arguments to `map` _and_ its return type - | |||
| clearly undesirable! | |||
| ```ocaml | |||
| let map f = | |||
| let go cont xs = | |||
| match xs with | |||
| | Nil -> cont Nil | |||
| | Cons (h, t) -> go (compose cont (fun x -> Cons (f h, x))) t | |||
| in go id ;; | |||
| ``` | |||
| Even more egregious is that the η-reduction of `map` would lead to an | |||
| ill-typed program. | |||
| ```ocaml | |||
| let map f xs = | |||
| let go cont xs = (* elided *) | |||
| in go id xs ;; | |||
| (* map : forall 'a 'b. ('a -> 'b) -> list 'a -> list 'b *) | |||
| let map' f = | |||
| let go cont xs = (* elided *) | |||
| in go id ;; | |||
| (* map' : forall 'a 'b 'c. ('a -> 'b) -> list 'a -> list 'c *) | |||
| ``` | |||
| Having declared this unacceptable, I set out to rewrite the type | |||
| checker, after months of procrastination. As is the case, of course, | |||
| with such things, it only took some two hours, and I really shouldn't have | |||
| procrastinated it for so long. | |||
| Perhaps more importantly, the new type checker also supports rank-N | |||
| polymorphism directly, with all appropriate checks in place: expressions | |||
| checked against a polymorphic type are, in reality, checked against a | |||
| _deeply skolemised_ version of that poly-type - this lets us enforce two | |||
| key properties: | |||
| 1. the expression being checked _is_ actually parametric over the type | |||
| arguments, i.e., it can't unify the skolem constants with any type | |||
| constructors, and | |||
| 2. no rank-N arguments escape. | |||
| As an example, consider the following function: | |||
| ```ocaml | |||
| let rankn (f : forall 'a. 'a -> 'a) = f () | |||
| ``` | |||
| Well-typed uses of this function are limited to applying it to the | |||
| identity function, as parametricity tells us; and, indeed, trying to | |||
| apply it to e.g. `fun x -> x + 1`{.ocaml} is a type error. | |||
| ### The Solver | |||
| As before, type checking is done by a traversal of the syntax tree | |||
| which, by use of a `Writer`{.haskell} monad, produces a list of | |||
| constraints to be solved. Note that a _list_ really is needed: a set, or | |||
| similar data structure with unspecified order, will not do. The order in | |||
| which the solver processes constraints is important! | |||
| The support for rank-N types has lead to the solver needing to know | |||
| about a new kind of constraint: _subsumption_ constraints, in addition | |||
| to _unification_ constraints. Subsumption is perhaps too fancy a term, | |||
| used to obscure what's really going on: subtyping. However, whilst | |||
| languages like Java and Scala introduce subtyping by means of | |||
| inheritance, our subtyping boils down to eliminating ∀s. | |||
| ∀s are eliminated from the right-hand-side of subsumption constraints by | |||
| _deep skolemisation_: replacing the quantified variables in the type | |||
| with fresh type constants. The "depth" of skolemisation refers to the | |||
| fact that ∀s to the right of arrows are eliminated along with the ones | |||
| at top-level. | |||
| ```haskell | |||
| subsumes k t1 t2@TyForall{} = do | |||
| t2' <- skolemise t2 | |||
| subsumes k t1 t2' | |||
| subsumes k t1@TyForall{} t2 = do | |||
| (_, _, t1') <- instantiate t1 | |||
| subsumes k t1' t2 | |||
| subsumes k a b = k a b | |||
| ``` | |||
| The function for computing subtyping is parametric over what to do in | |||
| the case of two monomorphic types: when this function is actually used | |||
| by the solving algorithm, it's applied to `unify`. | |||
| The unifier has the job of traversing two types in tandem to find the | |||
| _most general unifier_: a substitution that, when applied to one type, | |||
| will make it syntatically equal to the other. In most of the type | |||
| checker, when two types need to be "equal", they're equal up to | |||
| unification. | |||
| Most of the cases are an entirely boring traversal, so here are the | |||
| interesting ones. | |||
| - Skolem type constants only unify with other skolem type constants: | |||
| ```haskell | |||
| unify TySkol{} TySkol{} = pure () | |||
| unify t@TySkol{} b = throwError $ SkolBinding t b | |||
| unify b t@TySkol{} = throwError $ SkolBinding t b | |||
| ``` | |||
| - Type variables extend the substitution: | |||
| ```haskell | |||
| unify (TyVar a) b = bind a b | |||
| unify a (TyVar b) = bind b a | |||
| ``` | |||
| - Polymorphic types unify up to α-renaming: | |||
| ```haskell | |||
| unify t@(TyForall vs ty) t'@(TyForall vs' ty') | |||
| | length vs /= length vs' = throwError (NotEqual t t') | |||
| | otherwise = do | |||
| fvs <- replicateM (length vs) freshTV | |||
| let subst = Map.fromList . flip zip fvs | |||
| unify (apply (subst vs) ty) (apply (subst vs') ty') | |||
| ``` | |||
| When binding a variable to a concrete type, an _occurs check_ is | |||
| performed to make sure the substitution isn't going to end up containing | |||
| an infinite type. Consider binding `'a := list 'a`: If `'a` is | |||
| substituted for `list 'a` everywhere, the result would be `list (list | |||
| 'a)` - but wait, `'a` appears there, so it'd be substituted again, ad | |||
| infinitum. | |||
| Extra care is also needed when binding a variable to itself, as is the | |||
| case with `'a ~ 'a`. These constraints are trivially discharged, but | |||
| adding them to the substitution would mean an infinite loop! | |||
| ```haskell | |||
| occurs :: Var Typed -> Type Typed -> Bool | |||
| occurs _ (TyVar _) = False | |||
| occurs x e = x `Set.member` ftv e | |||
| ``` | |||
| If the variable has already been bound, the new type is unified with the | |||
| one present in the substitution being accumulated. Otherwise, it is | |||
| added to the substitution. | |||
| ```haskell | |||
| bind :: Var Typed -> Type Typed -> SolveM () | |||
| bind var ty | |||
| | occurs var ty = throwError (Occurs var ty) | |||
| | TyVar var == ty = pure () | |||
| | otherwise = do | |||
| env <- get | |||
| -- Attempt to extend the environment, otherwise | |||
| -- unify with existing type | |||
| case Map.lookup var env of | |||
| Nothing -> put (Map.singleton var (normType ty) `compose` env) | |||
| Just ty' | |||
| | ty' == ty -> pure () | |||
| | otherwise -> unify (normType ty) (normType ty') | |||
| ``` | |||
| Running the solver, then, amounts to folding through the constraints in | |||
| order, applying the substitution created at each step to the remaining | |||
| constraints while also accumulating it to end up at the most general | |||
| unifier. | |||
| ```haskell | |||
| solve :: Int -> Subst Typed | |||
| -> [Constraint Typed] | |||
| -> Either TypeError (Subst Typed) | |||
| solve _ s [] = pure s | |||
| solve i s (ConUnify e a t:xs) = do | |||
| case runSolve i s (unify (normType a) (normType t)) of | |||
| Left err -> Left (ArisingFrom err e) | |||
| Right (i', s') -> solve i' (s' `compose` s) (apply s' xs) | |||
| solve i s (ConSubsume e a b:xs) = | |||
| case runSolve i s (subsumes unify (normType a) (normType b)) of | |||
| Left err -> Left (ArisingFrom err e) | |||
| Right (i', s') -> solve i' (s' `compose` s) (apply s' xs) | |||
| ``` | |||
| ### Inferring and Checking Patterns | |||
| Amulet, being a member of the ML family, does most data processing | |||
| through _pattern matching_, and so, the patterns also need to be type | |||
| checked. | |||
| The pattern grammar is simple: it's made up of 6 constructors, while | |||
| expressions are described by over twenty constructors. | |||
| Here, the bidirectional approach to inference starts to shine. It is | |||
| possible to have different behaviours for when the type of the | |||
| pattern (or, at least, some skeleton describing that type) is known | |||
| and for when it is not, and such a type must be produced from the | |||
| pattern alone. | |||
| In an unification-based system like ours, the inference judgement can be | |||
| recovered from the checking judgement by checking against a fresh type | |||
| variable. | |||
| ```haskell | |||
| inferPattern p = do | |||
| x <- freshTV | |||
| (p', binds) <- checkPattern p x | |||
| pure (p', x, binds) | |||
| ``` | |||
| Inferring patterns produces three things: an annotated pattern, since | |||
| syntax trees after type checking carry their types; the type of values | |||
| that pattern matches; and a list of variables the pattern binds. | |||
| Checking omits returning the type, and yields only the annotated syntax | |||
| tree and the list of bindings. | |||
| As a special case, inferring patterns with type signatures overrides the | |||
| checking behaviour. The stated type is kind-checked (to verify its | |||
| integrity and to produce an annotated tree), then verified to be a | |||
| subtype of the inferred type for that pattern. | |||
| ```haskell | |||
| inferPattern pat@(PType p t ann) = do | |||
| (p', pt, vs) <- inferPattern p | |||
| (t', _) <- resolveKind t | |||
| _ <- subsumes pat t' pt -- t' ≤ pt | |||
| case p' of | |||
| Capture v _ -> pure (PType p' t' (ann, t'), t', [(v, t')]) | |||
| _ -> pure (PType p' t' (ann, t'), t', vs) | |||
| ``` | |||
| Checking patterns is where the fun actually happens. Checking `Wildcard`s | |||
| and `Capture`s is pretty much identical, except the latter actually | |||
| expands the capture list. | |||
| ```haskell | |||
| checkPattern (Wildcard ann) ty = pure (Wildcard (ann, ty), []) | |||
| checkPattern (Capture v ann) ty = | |||
| pure (Capture (TvName v) (ann, ty), [(TvName v, ty)]) | |||
| ``` | |||
| Checking a `Destructure` looks up the type of the constructor in the | |||
| environment, possibly instancing it, and does one of two things, | |||
| depending on whether or not the destructuring did not have an inner | |||
| pattern. | |||
| ```haskell | |||
| checkPattern ex@(Destructure con ps ann) ty = | |||
| case ps of | |||
| ``` | |||
| - If there was no inner pattern, then the looked-up type is unified with | |||
| the "goal" type - the one being checked against. | |||
| ```haskell | |||
| Nothing -> do | |||
| pty <- lookupTy con | |||
| _ <- unify ex pty ty | |||
| pure (Destructure (TvName con) Nothing (ann, pty), []) | |||
| ``` | |||
| - If there _was_ an inner pattern, we proceed by decomposing the type | |||
| looked up from the environment. The inner pattern is checked against the | |||
| _domain_ of the constructor's type, while the "goal" gets unified with | |||
| the _co-domain_. | |||
| ```haskell | |||
| Just p -> do | |||
| (c, d) <- decompose ex _TyArr =<< lookupTy con | |||
| (ps', b) <- checkPattern p c | |||
| _ <- unify ex ty d | |||
| ``` | |||
| Checking tuple patterns is a bit of a mess. This is because of a | |||
| mismatch between how they're written and how they're typed: a 3-tuple | |||
| pattern (and expression!) is written like `(a, b, c)`, but it's _typed_ | |||
| like `a * (b * c)`. There is a local helper that incrementally converts | |||
| between the representations by repeatedly decomposing the goal type. | |||
| ```haskell | |||
| checkPattern pt@(PTuple elems ann) ty = | |||
| let go [x] t = (:[]) <$> checkPattern x t | |||
| go (x:xs) t = do | |||
| (left, right) <- decompose pt _TyTuple t | |||
| (:) <$> checkPattern x left <*> go xs right | |||
| go [] _ = error "malformed tuple in checkPattern" | |||
| ``` | |||
| Even more fun is the `PTuple` constructor is woefully overloaded: One | |||
| with an empty list of children represents matching against `unit`{.ml}. | |||
| One with a single child is equivalent to the contained pattern; Only one | |||
| with more than two contained patterns makes a proper tuple. | |||
| ```haskell | |||
| in case elems of | |||
| [] -> do | |||
| _ <- unify pt ty tyUnit | |||
| pure (PTuple [] (ann, tyUnit), []) | |||
| [x] -> checkPattern x ty | |||
| xs -> do | |||
| (ps, concat -> binds) <- unzip <$> go xs ty | |||
| pure (PTuple ps (ann, ty), binds) | |||
| ``` | |||
| ### Inferring and Checking Expressions | |||
| Expressions are incredibly awful and the bane of my existence. There are | |||
| 18 distinct cases of expression to consider, a number which only seems | |||
| to be going up with modules and the like in the pipeline; this | |||
| translates to 24 distinct cases in the type checker to account for all | |||
| of the possibilities. | |||
| As with patterns, expression checking is bidirectional; and, again, | |||
| there are a lot more checking cases then there are inference cases. So, | |||
| let's start with the latter. | |||
| #### Inferring Expressions | |||
| Inferring variable references makes use of instantiation to generate | |||
| fresh type variables for each top-level universal quantifier in the | |||
| type. These fresh variables will then be either bound to something by | |||
| the solver or universally quantified over in case they escape. | |||
| Since Amulet is desugared into a core language resembling predicative | |||
| System F, variable uses also lead to the generation of corresponding | |||
| type applications - one for each eliminated quantified variable. | |||
| ```haskell | |||
| infer expr@(VarRef k a) = do | |||
| (inst, old, new) <- lookupTy' k | |||
| if Map.null inst | |||
| then pure (VarRef (TvName k) (a, new), new) | |||
| else mkTyApps expr inst old new | |||
| ``` | |||
| Functions, strangely enough, have both checking _and_ inference | |||
| judgements: which is used impacts what constraints will be generated, | |||
| and that may end up making type inference more efficient (by allocating | |||
| less, or correspondingly spending less time in the solver). | |||
| The pattern inference judgement is used to compute the type and bindings | |||
| of the function's formal parameter, and the body is inferred in the | |||
| context extended with those bindings; Then, a function type is | |||
| assembled. | |||
| ```haskell | |||
| infer (Fun p e an) = do | |||
| (p', dom, ms) <- inferPattern p | |||
| (e', cod) <- extendMany ms $ infer e | |||
| pure (Fun p' e' (an, TyArr dom cod), TyArr dom cod) | |||
| ``` | |||
| Literals are pretty self-explanatory: Figuring their types boils down to | |||
| pattern matching. | |||
| ```haskell | |||
| infer (Literal l an) = pure (Literal l (an, ty), ty) where | |||
| ty = case l of | |||
| LiInt{} -> tyInt | |||
| LiStr{} -> tyString | |||
| LiBool{} -> tyBool | |||
| LiUnit{} -> tyUnit | |||
| ``` | |||
| The inference judgement for _expressions_ with type signatures is very similar | |||
| to the one for patterns with type signatures: The type is kind-checked, | |||
| then compared against the inferred type for that expression. Since | |||
| expression syntax trees also need to be annotated, they are `correct`ed | |||
| here. | |||
| ```haskell | |||
| infer expr@(Ascription e ty an) = do | |||
| (ty', _) <- resolveKind ty | |||
| (e', et) <- infer e | |||
| _ <- subsumes expr ty' et | |||
| pure (Ascription (correct ty' e') ty' (an, ty'), ty') | |||
| ``` | |||
| There is also a judgement for turning checking into inference, again by | |||
| making a fresh type variable. | |||
| ```haskell | |||
| infer ex = do | |||
| x <- freshTV | |||
| ex' <- check ex x | |||
| pure (ex', x) | |||
| ``` | |||
| #### Checking Expressions | |||
| Our rule for eliminating ∀s was adapted from the paper [Complete | |||
| and Easy Bidirectional Typechecking for Higher-Rank Polymorphism]. | |||
| Unlike in that paper, however, we do not have explicit _existential | |||
| variables_ in contexts, and so must check expressions against | |||
| deeply-skolemised types to eliminate the universal quantifiers. | |||
| [Complete and Easy Bidirectional Typechecking for Higher-Rank | |||
| Polymorphism]: https://www.cl.cam.ac.uk/~nk480/bidir.pdf | |||
| ```haskell | |||
| check e ty@TyForall{} = do | |||
| e' <- check e =<< skolemise ty | |||
| pure (correct ty e') | |||
| ``` | |||
| If the expression is checked against a deeply skolemised version of the | |||
| type, however, it will be tagged with that, while it needs to be tagged | |||
| with the universally-quantified type. So, it is `correct`ed. | |||
| Amulet has rudimentary support for _typed holes_, as in dependently | |||
| typed languages and, more recently, GHC. Since printing the type of | |||
| holes during type checking would be entirely uninformative due to | |||
| half-solved types, reporting them is deferred to after checking. | |||
| Of course, holes must still have checking behaviour: They take whatever | |||
| type they're checked against. | |||
| ```haskell | |||
| check (Hole v a) t = pure (Hole (TvName v) (a, t)) | |||
| ``` | |||
| Checking functions is as easy as inferring them: The goal type is split | |||
| between domain and codomain; the pattern is checked against the domain, | |||
| while the body is checked against the codomain, with the pattern's | |||
| bindings in scope. | |||
| ```haskell | |||
| check ex@(Fun p b a) ty = do | |||
| (dom, cod) <- decompose ex _TyArr ty | |||
| (p', ms) <- checkPattern p dom | |||
| Fun p' <$> extendMany ms (check b cod) <*> pure (a, ty) | |||
| ``` | |||
| Empty `begin end` blocks are an error. | |||
| ``` | |||
| check ex@(Begin [] _) _ = throwError (EmptyBegin ex) | |||
| ``` | |||
| `begin ... end` blocks with at least one expression are checked by | |||
| inferring the types of every expression but the last, and then checking | |||
| the last expression in the block against the goal type. | |||
| ```haskell | |||
| check (Begin xs a) t = do | |||
| let start = init xs | |||
| end = last xs | |||
| start' <- traverse (fmap fst . infer) start | |||
| end' <- check end t | |||
| pure (Begin (start' ++ [end']) (a, t)) | |||
| ``` | |||
| `let`s are pain. Since all our `let`s are recursive by nature, they must | |||
| be checked, including all the bound variables, in a context where the | |||
| types of every variable bound there are already available; To figure | |||
| this out, however, we first need to infer the type of every variable | |||
| bound there. | |||
| If that strikes you as "painfully recursive", you're right. This is | |||
| where the unification-based nature of our type system saved our butts: | |||
| Each bound variable in the `let` gets a fresh type variable, the context | |||
| is extended and the body checked against the goal. | |||
| The function responsible for inferring and solving the types of | |||
| variables is `inferLetTy`. It keeps an accumulating association list to | |||
| check the types of further bindings as they are figured out, one by one, | |||
| then uses the continuation to generalise (or not) the type. | |||
| ```haskell | |||
| check (Let ns b an) t = do | |||
| ks <- for ns $ \(a, _, _) -> do | |||
| tv <- freshTV | |||
| pure (TvName a, tv) | |||
| extendMany ks $ do | |||
| (ns', ts) <- inferLetTy id ks (reverse ns) | |||
| extendMany ts $ do | |||
| b' <- check b t | |||
| pure (Let ns' b' (an, t)) | |||
| ``` | |||
| We have decided to take [the advice of Vytiniotis, Peyton Jones, and | |||
| Schrijvers], and refrain from generalising lets, except at top-level. | |||
| This is why `inferLetTy` gets given `id` when checking terms. | |||
| [the advice of Vytiniotis, Peyton Jones, and Schrijvers]: https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/tldi10-vytiniotis.pdf | |||
| The judgement for checking `if` expressions is what made me stick to | |||
| bidirectional type checking instead of fixing out variant of Algorithm | |||
| W. The condition is checked against the boolean type, while both | |||
| branches are checked against the goal. | |||
| ```haskell | |||
| check (If c t e an) ty = If <$> check c tyBool | |||
| <*> check t ty | |||
| <*> check e ty | |||
| <*> pure (an, ty) | |||
| ``` | |||
| it is not possible, in general, to recover the type of a function | |||
| at an application site, we infer it; The argument given is checked | |||
| against that function's domain and the codomain is unified with the | |||
| goal type. | |||
| ```haskell | |||
| check ex@(App f x a) ty = do | |||
| (f', (d, c)) <- secondA (decompose ex _TyArr) =<< infer f | |||
| App f' <$> check x d <*> fmap (a,) (unify ex ty c) | |||
| ``` | |||
| To check `match`, the type of what's being matched against is first | |||
| inferred because, unlike application where _some_ recovery is possible, | |||
| we can not recover the type of matchees from the type of branches _at | |||
| all_. | |||
| ```haskell | |||
| check (Match t ps a) ty = do | |||
| (t', tt) <- infer t | |||
| ``` | |||
| Once we have the type of the matchee in hands, patterns can be checked | |||
| against that. The branches are then each checked against the goal type. | |||
| ```haskell | |||
| ps' <- for ps $ \(p, e) -> do | |||
| (p', ms) <- checkPattern p tt | |||
| (,) <$> pure p' <*> extendMany ms (check e ty) | |||
| ``` | |||
| Checking binary operators is like checking function application twice. | |||
| Very boring. | |||
| ```haskell | |||
| check ex@(BinOp l o r a) ty = do | |||
| (o', to) <- infer o | |||
| (el, to') <- decompose ex _TyArr to | |||
| (er, d) <- decompose ex _TyArr to' | |||
| BinOp <$> check l el <*> pure o' | |||
| <*> check r er <*> fmap (a,) (unify ex d ty) | |||
| ``` | |||
| Checking records and record extension is a hack, so I'm not going to | |||
| talk about them until I've cleaned them up reasonably in the codebase. | |||
| Record access, however, is very clean: we make up a type for the | |||
| row-polymorphic bit, and check against a record type built from the goal | |||
| and the key. | |||
| ```haskell | |||
| check (Access rc key a) ty = do | |||
| rho <- freshTV | |||
| Access <$> check rc (TyRows rho [(key, ty)]) | |||
| <*> pure key <*> pure (a, ty) | |||
| ``` | |||
| Checking tuple expressions involves a local helper much like checking | |||
| tuple patterns. The goal type is recursively decomposed and made to line | |||
| with the expression being checked. | |||
| ```haskell | |||
| check ex@(Tuple es an) ty = Tuple <$> go es ty <*> pure (an, ty) where | |||
| go [] _ = error "not a tuple" | |||
| go [x] t = (:[]) <$> check x t | |||
| go (x:xs) t = do | |||
| (left, right) <- decompose ex _TyTuple t | |||
| (:) <$> check x left <*> go xs right | |||
| ``` | |||
| And, to finish, we have a judgement for turning inference into checking. | |||
| ```haskell | |||
| check e ty = do | |||
| (e', t) <- infer e | |||
| _ <- subsumes e ty t | |||
| pure e' | |||
| ``` | |||
| ### Conclusion | |||
| I like the new type checker: it has many things you'd expect from a | |||
| typed lambda calculus, such as η-contraction preserving typability, and | |||
| substitution of `let`{.ocaml}-bound variables being generally | |||
| admissable. | |||
| Our type system is fairly complex, what with rank-N types and higher | |||
| kinded polymorphism, so inferring programs under it is a bit of a | |||
| challenge. However, I am fairly sure the only place that demands type | |||
| annotations are higher-ranked _parameters_: uses of higher-rank | |||
| functions are checked without the need for annotations. | |||
| Check out [Amulet] the next time you're looking for a typed functional | |||
| programming language that still can't compile to actual executables. | |||
| [Amulet]: https://github.com/zardyh/amulet | |||
+ 286
- 0
pages/posts/2018-03-14-amulet-safety.md
View File
| @ -0,0 +1,286 @@ | |||
| --- | |||
| title: Amulet and Language Safety | |||
| date: March 14, 2018 | |||
| --- | |||
| Ever since its inception, Amulet has strived to be a language that | |||
| _guarantees_ safety, to some extent, with its strong, static, inferred | |||
| type system. Through polymorphism we gain the concept of | |||
| _parametricity_, as explained in Philip Wadler's [Theorems for Free]: a | |||
| function's behaviour does not depend on the instantiations you perform. | |||
| However, the power-to-weight ratio of these features quickly plummets, | |||
| as every complicated type system extension makes inference rather | |||
| undecidable, which in turn mandates more and more type annotations. Of | |||
| the complex extensions I have read about, three struck me as | |||
| particularly elegant, and I have chosen to implement them all in Amulet: | |||
| - Generalised Algebraic Data Types, which this post is about; | |||
| - Row Polymorphism, which allows being precise about which structure | |||
| fields a function uses; and | |||
| - Rank-N types, which enables the implementation of many concepts | |||
| including monadic regions. | |||
| Both GADTs and rank-N types are in the "high weight" category: inference | |||
| in the presence of both is undecidable. Adding support for the latter | |||
| (which laid the foundations for the former) is what drove me to re-write | |||
| the type checker, a crusade detailed in [my last post]. | |||
| Of course, in the grand scheme of things, some languages provide way | |||
| more guarantees than Amulet: For instance, Rust, with its lifetime | |||
| system, can prove that code is memory-safe at compile time; | |||
| Dependently-typed languages such as Agda and Idris can express a lot of | |||
| invariants in their type system, but inference is completely destroyed. | |||
| Picking which features you'd like to support is a game of | |||
| tradeoffs---all of them have benefits, but some have exceedingly high | |||
| costs. | |||
| Amulet was originally based on a very traditional, HM-like type system | |||
| with support for row polymorphism. The addition of rank-N polymorphism | |||
| and GADTs instigated the move to a bidirectional system, which in turn | |||
| provided us with the ability to experiment with a lot more type system | |||
| extensions (for instance, linear types)---in pursuit of more guarantees | |||
| like parametricity. | |||
| GADTs | |||
| ===== | |||
| In a sense, generalised ADTs are a "miniature" version of the inductive | |||
| families one would find in dependently-typed programming (and, indeed, | |||
| Amulet can type-check _some_ uses of length-indexed vectors, although | |||
| the lack of type-level computation is a showstopper). They allow | |||
| non-uniformity in the return types of constructors, by packaging | |||
| "coercions" along with the values; pattern matching, then, allows these | |||
| coercions to influence the solving of particular branches. | |||
| Since this is an introduction to indexed types, I am legally obligated | |||
| to present the following three examples: the type of equality witnesses | |||
| between two other types; higher-order abstract syntax, the type of | |||
| well-formed terms in some language; and _vectors_, the type of linked | |||
| lists with statically-known lengths. | |||
| #### Equality | |||
| As is tradition in intuitionistic type theory, we define equality by | |||
| postulating (that is, introducing a _constructor_ witnessing) | |||
| reflexivity: anything is equal to itself. Symmetry and transitivity can | |||
| be defined as ordinary pattern-matching functions. However, this | |||
| demonstrates the first (and main) shortcoming of our implementation: | |||
| Functions which perform pattern matching on generalised constructors | |||
| _must_ have explicitly stated types.[^1] | |||
| ```ocaml | |||
| type eq 'a 'b = | |||
| | Refl : eq 'a 'a ;; | |||
| let sym (Refl : eq 'a 'b) : eq 'b 'a = Refl ;; | |||
| let trans (Refl : eq 'a 'b) (Refl : eq 'b 'c) : eq 'a 'c = Refl ;; | |||
| ``` | |||
| Equality, when implemented like this, is conventionally used to | |||
| implement substitution: If there exists a proof that `a` and `b` are | |||
| equal, any `a` may be treated as a `b`. | |||
| ```ocaml | |||
| let subst (Refl : eq 'a 'b) (x : 'a) : 'b = x ;; | |||
| ``` | |||
| Despite `a` and `b` being distinct, _rigid_ type variables, matching on | |||
| `Refl` allows the constraint solver to treat them as equal. | |||
| #### Vectors | |||
| ```ocaml | |||
| type z ;; (* the natural zero *) | |||
| type s 'k ;; (* the successor of a number *) | |||
| type vect 'n 'a = (* vectors of length n *) | |||
| | Nil : vect z 'a | |||
| | Cons : 'a * vect 'k 'a -> vect (s 'k) 'a | |||
| ``` | |||
| Parametricity can tell us many useful things about functions. For | |||
| instance, all closed, non-looping inhabitants of the type `forall 'a. 'a | |||
| -> 'a` are operationally the identity function. However, expanding the | |||
| type grammar tends to _weaken_ parametricity before making it stronger. | |||
| Consider the type `forall 'a. list 'a -> list 'a`{.ocaml}---it has | |||
| several possible implementations: One could return the list unchanged, | |||
| return the empty list, duplicate every element in the list, drop some | |||
| elements around the middle, among _many_ other possible behaviours. | |||
| Indexed types are beyond the point of weakening parametricity, and start | |||
| to make it strong again. Consider a function of type `forall 'a 'n. ('a | |||
| -> 'a -> ordering) -> vect 'n 'a -> vect 'n 'a`{.ocaml}---by making the | |||
| length of the vector explicit in the type, and requiring it to be kept | |||
| the same, we have ruled out any implementations that drop or duplicate | |||
| elements. A win, for sure, but at what cost? An implementation of | |||
| insertion sort for traditional lists looks like this, when implemented | |||
| in Amulet: | |||
| ```ocaml | |||
| let insert_sort cmp l = | |||
| let insert e tl = | |||
| match tl with | |||
| | Nil -> Cons (e, Nil) | |||
| | Cons (h, t) -> match cmp e h with | |||
| | Lt -> Cons (e, Cons (h, t)) | |||
| | Gt -> Cons (h, insert e t) | |||
| | Eq -> Cons (e, Cons (h, t)) | |||
| and go l = match l with | |||
| | Nil -> Nil | |||
| | Cons (x, xs) -> insert x (go xs) | |||
| in go l ;; | |||
| ``` | |||
| The implementation for vectors, on the other hand, is full of _noise_: | |||
| type signatures which we would rather not write, but are forced to by | |||
| the nature of type systems. | |||
| ```ocaml | |||
| let insert_sort (cmp : 'a -> 'a -> ordering) (v : vect 'n 'a) : vect 'n 'a = | |||
| let insert (e : 'a) (tl : vect 'k 'a) : vect (s 'k) 'a = | |||
| match tl with | |||
| | Nil -> Cons (e, Nil) | |||
| | Cons (h, t) -> match cmp e h with | |||
| | Lt -> Cons (e, Cons (h, t)) | |||
| | Gt -> Cons (h, insert e t) | |||
| | Eq -> Cons (e, Cons (h, t)) | |||
| and go (v : vect 'k 'a) : vect 'k 'a = match v with | |||
| | Nil -> Nil | |||
| | Cons (x, xs) -> insert x (go xs) | |||
| in go v ;; | |||
| ``` | |||
| These are not quite theorems for free, but they are theorems for quite | |||
| cheap. | |||
| #### Well-Typed Terms | |||
| ```ocaml | |||
| type term 'a = | |||
| | Lit : int -> term int | |||
| | Fun : ('a -> 'b) -> term ('a -> 'b) | |||
| | App : term ('a -> 'b) * term 'a -> term 'b | |||
| ``` | |||
| In much the same way as the vector example, which forced us to be | |||
| correct with our functions, GADTs can also be applied in making us be | |||
| correct with our _data_. The type `term 'a` represents well typed terms: | |||
| the interpretation of such a value need not be concerned with runtime | |||
| errors at all, by leveraging the Amulet type system to make sure its | |||
| inputs are correct. | |||
| ``` | |||
| let eval (x : term 'a) : 'a = | |||
| match x with | |||
| | Lit l -> l | |||
| | Fun f -> f | |||
| | App (f, x) -> (eval f) (eval x) | |||
| ``` | |||
| While equalities let us bend the type system to our will, vectors and | |||
| terms let _the type system_ help us, in making incorrect implementations | |||
| compile errors. | |||
| Rank-N Types | |||
| ============ | |||
| Rank-N types are quite useful, I'm sure. To be quite honest, they were | |||
| mostly implemented in preparation for GADTs, as the features have some | |||
| overlap. | |||
| A use case one might imagine if Amulet had notation for monads would be | |||
| [an implementation of the ST monad][^2], which prevents mutable state | |||
| from escaping by use of rank-N types. `St.run action` is a well-typed | |||
| program, since `action` has type `forall 's. st 's int`, but `St.run | |||
| action'` is not, since that has type `forall 's. st 's (ref 's int)`. | |||
| ```ocaml | |||
| let action = | |||
| St.bind (alloc_ref 123) (fun var -> | |||
| St.bind (update_ref var (fun x -> x * 2)) (fun () -> | |||
| read_ref var)) | |||
| and action' = | |||
| St.bind (alloc_ref 123) (fun var -> | |||
| St.bind (update_ref var (fun x -> x * 2)) (fun () -> | |||
| St.pure var)) | |||
| ``` | |||
| Conclusion | |||
| ========== | |||
| Types are very powerful things. A powerful type system helps guide the | |||
| programmer by allowing the compiler to infer more and more of the | |||
| _program_---type class dictionaries in Haskell, and as a more extreme | |||
| example, proof search in Agda and Idris. | |||
| However, since the industry has long been dominated by painfully | |||
| first-order, very verbose type systems like those of Java and C#, it's | |||
| no surprise that many programmers have fled to dynamically typed | |||
| languages like ~~Go~~ Python---a type system needs to be fairly complex | |||
| before it gets to being expressive, and it needs to be _very_ complex to | |||
| get to the point of being useful. | |||
| Complexity and difficulty, while often present together, are not | |||
| nescessarily interdependent: Take, for instance, Standard ML. The | |||
| first-order parametric types might seem restrictive when used to a | |||
| system with like Haskell's (or, to some extent, Amulet's[^3]), but they | |||
| actually allow a lot of flexibility, and do not need many annotations at | |||
| all! They are a sweet spot in the design space. | |||
| If I knew more about statistics, I'd have some charts here correlating | |||
| programmer effort with implementor effort, and also programmer effort | |||
| with the extent of properties one can state as types. Of course, these | |||
| are all fuzzy metrics, and no amount of statistics would make those | |||
| charts accurate, so have my feelings in prose instead: | |||
| - Implementing a dynamic type system is _literally_ no effort. No effort | |||
| needs to be spent writing an inference engine, or a constraint solver, | |||
| or a renamer, or any other of the very complex moving parts of a type | |||
| checker. | |||
| However, the freedom they allow the implementor they take away from | |||
| the programmer, by forcing them to keep track of the types of | |||
| everything mentally. Even those that swear by dynamic types can not | |||
| refute the claim that data has shape, and having a compiler that can | |||
| make sure your shapes line up so you can focus on programming is a | |||
| definite advantage. | |||
| - On the opposite end of the spectrum, implementing a dependent type | |||
| system is a _lot_ of effort. Things quickly diverge into undecidability | |||
| before you even get to writing a solver---and higher order unification, | |||
| which has a tendency to pop up, is undecidable too. | |||
| While the implementor is subject to an endless stream of suffering, | |||
| the programmer is in some ways free and some ways constrained. They | |||
| can now express lots of invariants in the type system, from | |||
| correctness of `sort` to correctness of [an entire compiler] or an | |||
| [operating system kernel], but they must also state very precise types | |||
| for everything. | |||
| - In the middle lies a land of convenient programming without an | |||
| endlessly suffering compiler author, a land first explored by the ML | |||
| family with its polymorphic, inferred type system. | |||
| This is clearly the sweet spot. Amulet leans slightly to the | |||
| dependently type end of the spectrum, but can still infer the types | |||
| for many simple and complex programs without any annotations-the | |||
| programs that do not use generalised algebraic data types or rank-N | |||
| polymorphism. | |||
| [Theorems for Free]: https://people.mpi-sws.org/~dreyer/tor/papers/wadler.pdf | |||
| [my last post]: /posts/2018-02-18.html | |||
| [an implementation of the ST monad]: https://txt.abby.how/st-monad.ml.html | |||
| [an entire compiler]: http://compcert.inria.fr/ | |||
| [operating system kernel]: https://sel4.systems/ | |||
| [^1]: In reality, the details are fuzzier. To be precise, pattern | |||
| matching on GADTs only introduces an implication constraint when the | |||
| type checker is applying a checking judgement. In practice, this means | |||
| that at least the return type must be explicitly annotated. | |||
| [^2]: Be warned that the example does not compile unless you remove the | |||
| modules, since our renamer is currently a bit daft. | |||
| [^3]: This is _my_ blog, and I'm allowed to brag about my projects, damn | |||
| it. | |||
+ 247
- 0
pages/posts/2018-03-27-amulet-gadts.md
View File
| @ -0,0 +1,247 @@ | |||
| --- | |||
| title: GADTs and Amulet | |||
| date: March 27, 2018 | |||
| maths: true | |||
| --- | |||
| Dependent types are a very useful feature - the gold standard of | |||
| enforcing invariants at compile time. However, they are still very much | |||
| not practical, especially considering inference for unrestricted | |||
| dependent types is equivalent to higher-order unification, which was | |||
| proven to be undecidable. | |||
| Fortunately, many of the benefits that dependent types bring aren't | |||
| because of dependent products themselves, but instead because of | |||
| associated features commonly present in those programming languages. One | |||
| of these, which also happens to be especially easy to mimic, are | |||
| _inductive families_, a generalisation of inductive data types: instead | |||
| of defining a single type inductively, one defines an entire _family_ of | |||
| related types. | |||
| Many use cases for inductive families are actually instances of a rather | |||
| less general concept, that of generalised algebraic data types, or | |||
| GADTs: Contrary to the indexed data types of full dependently typed | |||
| languages, these can and are implemented in several languages with | |||
| extensive inference, such as Haskell, OCaml and, now, Amulet. | |||
| Before I can talk about their implementation, I am legally obligated to | |||
| present the example of _length indexed vectors_, linked structures whose | |||
| size is known at compile time---instead of carrying around an integer | |||
| representing the number of elements, it is represented in the type-level | |||
| by a Peano[^1] natural number, as an _index_ to the vector type. By | |||
| universally quantifying over the index, we can guarantee by | |||
| parametricity[^2] that functions operating on these don't do inappropriate | |||
| things to the sizes of vectors. | |||
| ```ocaml | |||
| type z ;; | |||
| type s 'k ;; | |||
| type vect 'n 'a = | |||
| | Nil : vect z 'a | |||
| | Cons : 'a * vect 'k 'a -> vect (s 'k) 'a | |||
| ``` | |||
| Since the argument `'n` to `vect` (its length) varies with the constructor one | |||
| chooses, we call it an _index_; On the other hand, `'a`, being uniform over all | |||
| constructors, is called a _parameter_ (because the type is _parametric_ over | |||
| the choice of `'a`). These definitions bake the measure of length into | |||
| the type of vectors: an empty vector has length 0, and adding an element | |||
| to the front of some other vector increases the length by 1. | |||
| Matching on a vector reveals its index: in the `Nil` case, it's possible | |||
| to (locally) conclude that it had length `z`. Meanwhile, the `Cons` case | |||
| lets us infer that the length was the successor of some other natural | |||
| number, `s 'k`, and that the tail itself has length `'k`. | |||
| If one were to write a function to `map` a function over a `vect`or, | |||
| they would be bound by the type system to write a correct implementation | |||
| - well, either that or going out of their way to make a bogus one. It | |||
| would be possible to enforce total correctness of a function such as | |||
| this one, by adding linear types and making the vector parameter linear. | |||
| ```ocaml | |||
| let map (f : 'a -> 'b) (xs : vect 'n 'a) : vect 'n 'b = | |||
| match xs with | |||
| | Nil -> Nil | |||
| | Cons (x, xs) -> Cons (f x, map f xs) ;; | |||
| ``` | |||
| If we were to, say, duplicate every element in the list, an error would | |||
| be reported. Unlike some others, this one is not very clear, and it | |||
| definitely could be improved. | |||
| ``` | |||
| Occurs check: The type variable jx | |||
| occurs in the type s 'jx | |||
| · Arising from use of the expression | |||
| Cons (f x, Cons (f x, map f xs)) | |||
| │ | |||
| 33 │ | Cons (x, xs) -> Cons (f x, Cons (f x, map f xs)) ;; | |||
| │ ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ | |||
| ``` | |||
| This highlights the essence of GADTs: pattern matching on them reveals | |||
| equalities about types that the solver can later exploit. This is what | |||
| allows the programmer to write functions that vary their return types | |||
| based on their inputs - a very limited form of type-term dependency, | |||
| which brings us ever closer to the Calculus of Constructions corner of | |||
| Barendregt's lambda cube[^3]. | |||
| The addition of generalised algebraic data types has been in planning | |||
| for over two years---it was in the original design document. In a | |||
| mission that not even my collaborator noticed, all of the recently-added | |||
| type system and IR features were directed towards enabling the GADT | |||
| work: bidirectional type checking, rank-N polymorphism and coercions. | |||
| All of these features had cover stories: higher-ranked polymorphism was | |||
| motivated by monadic regions; bidirectional type checking was motivated | |||
| by the aforementioned polymorphism; and coercions were motivated by | |||
| newtype optimisation. But, in reality, it was a conspiracy to make GADTs | |||
| possible: having support for these features simplified implementing our | |||
| most recent form of fancy types, and while adding all of these in one go | |||
| would be possible, doing it incrementally was a lot saner. | |||
| While neither higher-ranked types nor GADTs technically demand a | |||
| bidirectional type system, implementing them with such a specification | |||
| is considerably easier, removing the need for workarounds such as boxy | |||
| types and a distinction between rigid/wobbly type variables. Our | |||
| algorithm for GADT inference rather resembles Richard Eisenberg's | |||
| [Bake]{.textsc}[^4], in that it only uses local equalities in _checking_ | |||
| mode. | |||
| Adding GADTs also lead directly to a rewrite of the solver, which now | |||
| has to work with _implication constraints_, of the form `(Q₁, ..., Qₙ) | |||
| => Q`, which should be read as "Assuming `Q₁` through `Qₙ`, conclude | |||
| `Q`." Pattern matching on generalised constructors, in checking mode, | |||
| captures every constraint generated by checking the right-hand side of a | |||
| clause and captures that as an implication constraint, with all the | |||
| constructor-bound equalities as assumptions. As an example, this lets us | |||
| write a type-safe cast function: | |||
| ```ocaml | |||
| type eq 'a 'b = Refl : eq 'a 'a | |||
| (* an inhabitant of eq 'a 'b is a proof that 'a and 'b are equal *) | |||
| let subst (Refl : eq 'a 'b) (x : 'a) : 'b = x ;; | |||
| ``` | |||
| Unfortunately, to keep inference decidable, many functions that depend | |||
| on generalised pattern matching need explicit type annotations, to guide | |||
| the type checker. | |||
| When _checking_ the body of the function, namely the variable reference | |||
| `x`, the solver is working under an assumption `'a ~ 'b` (i.e., `'a` and | |||
| `'b` stand for the same type), which lets us unify the stated type of | |||
| `x`, namely `'a`, with the return type of the function, `'b`. | |||
| If we remove the local assumption, say, by not matching on | |||
| `Refl`{.haskell}, the solver will not be allowed to unify the two type | |||
| variables `'a` and `'b`, and an error message will be reported[^6]: | |||
| ``` | |||
| examples/gadt/equality.ml[11:43 ..11:43]: error | |||
| Can not unify rigid type variable b with the rigid type variable a | |||
| · Note: the variable b was rigidified because of a type ascription | |||
| against the type forall 'a 'b. t 'a 'b -> 'a -> 'b | |||
| and is represented by the constant bq | |||
| · Note: the rigid type variable a, in turn, | |||
| was rigidified because of a type ascription | |||
| against the type forall 'a 'b. t 'a 'b -> 'a -> 'b | |||
| · Arising from use of the expression | |||
| x | |||
| │ | |||
| 11 │ let subst (_ : t 'a 'b) (x : 'a) : 'b = x ;; | |||
| │ ~ | |||
| ``` | |||
| Our intermediate language was also extended, from a straightforward | |||
| System F-like lambda calculus with type abstractions and applications, | |||
| to a System F<sub>C</sub>-like system with _coercions_, _casts_, and | |||
| _coercion abstraction_. Coercions are the evidence, produced by the | |||
| solver, that an expression is usable as a given type---GADT patterns | |||
| bind coercions like these, which are the "reification" of an implication | |||
| constraint. This lets us make type-checking on the intermediate language | |||
| fast and decidable[^5], as a useful sanity check. | |||
| The two new judgements for GADT inference correspond directly to new | |||
| cases in the `infer` and `check` functions, the latter of which I | |||
| present here for completeness. The simplicity of this change serves as | |||
| concrete evidence of the claim that bidirectional systems extend readily | |||
| to new, complex features, producing maintainable and readable code. | |||
| ```haskell | |||
| check (Match t ps a) ty = do | |||
| (t, tt) <- infer t | |||
| ps <- for ps $ \(p, e) -> do | |||
| (p', ms, cs) <- checkPattern p tt | |||
| let tvs = Set.map unTvName (boundTvs p' ms) | |||
| (p',) <$> implies (Arm p e) tt cs | |||
| (local (typeVars %~ Set.union tvs) | |||
| (extendMany ms (check e ty))) | |||
| pure (Match t ps (a, ty)) | |||
| ``` | |||
| This corresponds to the checking judgement for matches, presented below. | |||
| Note that in my (rather informal) theoretical presentation of Amulet | |||
| typing judgements, we present implication constraints as a lexical scope | |||
| of equalities conjoined with the scope of variables; Inference | |||
| judgements (with double right arrows, $\Rightarrow$) correspond to uses of | |||
| `infer`, pattern checking judgements ($\Leftarrow_\text{pat}$) | |||
| correspond to `checkPattern`, which also doubles as $\mathtt{binds}$ and | |||
| $\mathtt{cons}$, and the main checking judgement $\Leftarrow$ is the | |||
| function `check`. | |||
| $$ | |||
| \frac{\Gamma; \mathscr{Q} \vdash e \Rightarrow \tau | |||
| \quad \Gamma \vdash p_i \Leftarrow_\text{pat} \tau | |||
| \quad \Gamma, \mathtt{binds}(p_i); \mathscr{Q}, \mathtt{cons}(p_i) | |||
| \vdash e_i \Leftarrow \sigma} | |||
| {\Gamma; \mathscr{Q} \vdash \mathtt{match}\ e\ \mathtt{with}\ \{p_i \to | |||
| e_i\} \Leftarrow \sigma} | |||
| $$ | |||
| Our implementation of the type checker is a bit more complex, because it | |||
| also does (some) elaboration and bookkeeping: tagging terms with types, | |||
| blaming type errors correctly, etc. | |||
| --- | |||
| This new, complicated feature was a lot harder to implement than | |||
| originally expected, but in the end it worked out. GADTs let us make the | |||
| type system _stronger_, while maintaining the decidable inference that | |||
| the non-fancy subset of the language enjoys. | |||
| The example presented here was the most boring one possible, mostly | |||
| because [two weeks ago] I wrote about their impact on the language's | |||
| ability to make things safer. | |||
| [^1]: Peano naturals are one particular formulation of the natural | |||
| numbers, which postulates that zero (denoted `z` above) is a natural | |||
| number, and any natural number's successor (denoted `s 'k` above) is | |||
| itself natural. | |||
| [^2]: This is one application of Philip Wadler's [Theorems for Free] | |||
| technique: given a (polymorphic) type of some function, we can derive | |||
| much of its behaviour. | |||
| [^3]: Amulet is currently somewhere on the edge between λ2 - the second | |||
| order lambda calculus, System F, and λP2, a system that allows | |||
| quantification over types and terms using the dependent product form, | |||
| which subsumes both the ∀ binder and the → arrow. Our lack of type | |||
| functions currently leaves us very far from the CoC. | |||
| [^4]: See [his thesis]. Our algorithm, of course, has the huge | |||
| simplification of not having to deal with full dependent types. | |||
| [^5]: Even if we don't do it yet---work is still ongoing to make the | |||
| type checker and solver sane. | |||
| [^6]: And quite a good one, if I do say so! The compiler | |||
| syntax highlights and pretty-prints both terms and types relevant to the | |||
| error, as you can see [here]. | |||
| [Theorems for Free]: http://homepages.inf.ed.ac.uk/wadler/topics/parametricity.html | |||
| [his thesis]: https://repository.brynmawr.edu/cgi/viewcontent.cgi?article=1074&context=compsci_pubs | |||
| [two weeks ago]: /posts/2018-03-14.html | |||
| [here]: https://i.abby.how/68c4d.png | |||
+ 304
- 0
pages/posts/2018-08-11-amulet-updates.md
View File
| @ -0,0 +1,304 @@ | |||
| --- | |||
| title: Amulet updates | |||
| date: August 11, 2018 | |||
| maths: true | |||
| --- | |||
| Jesus, it's been a while. Though my last post was almost 6 months ago | |||
| (give or take a few), I've been busy working on | |||
| [Amulet](https://github.com/tmpim/amulet), which continues to grow, | |||
| almost an eldritch abomination you try desperately, but fail, to kill. | |||
| Since my last post, Amulet has changed a ton, in noticeable and | |||
| not-so-noticeable ways. Here are the major changes to the compiler since | |||
| then. | |||
| Parser improvements | |||
| =================== | |||
| No language is good to use if it's inconvenient. So, in an effort to | |||
| make writing code more convenient, we've removed the need for `;;` after | |||
| top-level declarations, and added a _bunch_ of indentation sensitivity, | |||
| thus making several keywords optional: `begin`{.ocaml} and `end`{.ocaml} | |||
| are implicit in the body of a `fun`{.ocaml}, `match`{.ocaml}, or | |||
| `let`{.ocaml}, which has made those keywords almost entirely obsolete. | |||
| The body of a `let`{.ocaml} also need not be preceded by `in`{.ocaml} if | |||
| meaning is clear from indentation. | |||
| To demonstrate, where you would have | |||
| ```ocaml | |||
| let foo = | |||
| let bar = fun x -> begin | |||
| a; | |||
| b; | |||
| c | |||
| end in begin | |||
| bar (); | |||
| bar 1; | |||
| end ;; | |||
| ``` | |||
| One can now write | |||
| ```ocaml | |||
| let foo = | |||
| let bar = fun x -> | |||
| a | |||
| b | |||
| c | |||
| bar () | |||
| bar 1 | |||
| ``` | |||
| Moreover, we've added shorthand syntax for building and destructuring | |||
| records: `{ x, y, z }`{.ocaml} is equivalent to `{ x = x, y = y, z = z | |||
| }`{.ocaml} in both pattern and expression position. | |||
| Changes to record typing | |||
| ======================== | |||
| Whereas `{ x with a = b }` would extend the record `x` to contain a new | |||
| field `a` (with value `b`), it's now _monomorphic update_ of the record | |||
| `x`. That is: `x` must _already_ contain a field called `a`, with the | |||
| same type as `b`. | |||
| This lets you write a function for updating a field in a record, such as | |||
| the one below, which would previously be impossible. Supporting | |||
| polymorphic update is not a priority, but it'd be nice to have. The way | |||
| PureScript, another language with row-polymorphic records, implements | |||
| polymorphic update does not fit in with our constraint based type | |||
| system. A new type of constraint would have to be introduced | |||
| specifically for this, which while not impossible, is certainly | |||
| annoying. | |||
| ```ocaml | |||
| let foo : forall 'row. { 'row | x : int } -> { 'row | x : int } = | |||
| fun r -> { r with x = r.x + 1 } | |||
| ``` | |||
| The impossibility of supporting polymorphic update with regular | |||
| subsumption constraints $a \le b$ stems from the fact that, when faced | |||
| with such a constraint, the compiler must produce a coercion function | |||
| that turns _any_ $a$ into a $b$ _given the types alone_. This is | |||
| possible for, say, field narrowing---just pick out the fields you want | |||
| out of a bigger record---but not for update, since the compiler has no | |||
| way of turning, for instance, an `int`{.ocaml} into a `string`{.ocaml}. | |||
| Stronger support for Rank-N Types | |||
| ================================= | |||
| Changes to how we handle subsumption have made it possible to store | |||
| polymorphic values in not only tuples, but also general records. For | |||
| instance: | |||
| ```ocaml | |||
| let foo = { | |||
| apply : forall 'a 'b. ('a -> 'b) -> 'a -> 'b = | |||
| fun x -> x | |||
| } (* : { apply : forall 'a 'b. ('a -> 'b) -> 'a -> 'b } *) | |||
| ``` | |||
| `foo`{.ocaml} is a record containing a single polymorphic application | |||
| function. It can be used like so: | |||
| ```ocaml | |||
| let () = | |||
| let { apply } = foo | |||
| apply (+ 1) 1 | |||
| apply (fun x -> x) () | |||
| ``` | |||
| Pattern-matching Let | |||
| ==================== | |||
| A feature I've desired for a while now, `let` expressions (and | |||
| declarations!) can have a pattern as their left-hand sides, as | |||
| demonstrated above. These can be used for any ol' type, including for | |||
| cases where pattern matching would be refutable. I haven't gotten around | |||
| to actually implementing this yet, but in the future, pattern matching | |||
| in `let`s will be restricted to (arbitrary) product types only. | |||
| ```ocaml | |||
| type option 'a = Some of 'a | None | |||
| type foo = Foo of { x : int } | |||
| let _ = | |||
| let Some x = ... (* forbidden *) | |||
| let Foo { x } = ... (* allowed *) | |||
| ``` | |||
| Even more "in-the-future", if we ever get around to adding attributes | |||
| like OCaml's, the check for this could be bypassed by annotating the | |||
| declaration with (say) a `[@partial]`{.ocaml} attribute. | |||
| Unfortunately, since Amulet _is_ a strict language, these are a bit | |||
| limited: They can not be recursive in _any_ way, neither directly nor | |||
| indirectly. | |||
| ```ocaml | |||
| (* type error *) | |||
| let (a, b) = (b, a) | |||
| (* similarly *) | |||
| let (a, b) = x | |||
| and x = (a, b) | |||
| ``` | |||
| Cycle detection and warnings | |||
| ============================ | |||
| A verification pass is run over the AST if type-checking succeeds, to | |||
| forbid illegal uses of recursion (strict language) and, as an additional | |||
| convenience, warn when local variables go unused. | |||
| For instance, this is [forbidden](/static/verify_error.png): | |||
| ```ocaml | |||
| let f = (fun x -> x) g | |||
| and g = (fun x -> x) f | |||
| ``` | |||
| And this gives a [warning](/static/verify_warn.png): | |||
| ```ocaml | |||
| let _ = | |||
| let { a, b } = { a = 1, b = 2 } | |||
| () | |||
| ``` | |||
| Plans for this include termination (and/or productivity) (as a | |||
| warning) and exhaustiveness checks (as an error). | |||
| No more `main` | |||
| ============ | |||
| Since pattern-matching `let`{.ocaml}s are allowed at top-level, there's no more | |||
| need for `main`. Instead of | |||
| ```ocaml | |||
| let main () = | |||
| ... | |||
| ``` | |||
| Just match on `()`{.ocaml} at top-level: | |||
| ```ocaml | |||
| let () = | |||
| ... | |||
| ``` | |||
| This gets rid of the (not so) subtle unsoundness introduced by the code | |||
| generator having to figure out how to invoke `main`, and the type | |||
| checker not checking that `main` has type `unit -> 'a`{.ocaml}, and also | |||
| allows us to remove much of the silly special-casing around variables | |||
| called `main`. | |||
| ```ocaml | |||
| let main x = x + 1 | |||
| (* attempt to perform arithmetic on a nil value *) | |||
| ``` | |||
| Implicit Parameters | |||
| =================== | |||
| A bit like Scala's, these allow marking a function's parameter as | |||
| implicit and having the type checker find out what argument you meant | |||
| automatically. Their design is based on a bit of reading other compiler | |||
| code, and also the paper on modular implicits for OCaml. However, we do | |||
| not have a ML-style module system at all (much to my dismay, but it's | |||
| being worked on), much less first class modules. | |||
| Implicit parameters allow ad-hoc overloading based on dictionary passing | |||
| (like type classes, but with less inference). | |||
| ```ocaml | |||
| type show 'a = Show of 'a -> string | |||
| let show ?(Show f) = f | |||
| let implicit show_string = | |||
| Show (fun x -> x) | |||
| let "foo" = show "foo" | |||
| ``` | |||
| Here, unification makes it known that `show` is looking for an implicit | |||
| argument of type `show string`{.ocaml}, and the only possibility is | |||
| `show_string`{.ocaml}, which is what gets used. | |||
| Implicit laziness | |||
| ================= | |||
| There is a built-in type `lazy : type -> type`{.ocaml}, a function | |||
| `force : forall 'a. lazy 'a -> 'a` for turning a thunk back into a | |||
| value, and a keyword `lazy` that makes a thunk out of any expression. | |||
| `lazy 'a`{.ocaml} and `'a` are mutual subtypes of eachother, and the | |||
| compiler inserts thunks/`force`{.ocaml}s where appropriate to make code | |||
| type-check. | |||
| ```ocaml | |||
| let x && y = if x then force y else false | |||
| let () = | |||
| false && launch_the_missiles () | |||
| (* no missiles were launched in the execution of this program *) | |||
| ``` | |||
| General refactoring | |||
| =================== | |||
| - Literal patterns are allowed for all types, and they're tested of | |||
| using `(==)`. | |||
| - Amulet only has one type constructor in its AST for all its kinds of | |||
| functions: `forall 'a. 'a -> int`{.ocaml}, `int -> string`{.ocaml} and `show string => | |||
| unit`{.ocaml} are all represented the same internally and disambiguated | |||
| by dependency/visibility flags. | |||
| - Polymorphic recursion is checked using "outline types", computed | |||
| before fully-fledged inference kicks in based solely on the shape of | |||
| values. This lets us handle the function below without an annotation on | |||
| its return type by computing that `{ count = 1 }` _must_ have type `{ | |||
| count : int }` beforehand. | |||
| Combined with the annotation on `x`, this gives us a "full" type | |||
| signature, which lets us use checking for `size`, allowing polymorphic | |||
| recursion to happen. | |||
| ~~~{.ocaml} | |||
| type nested 'a = Nested of nested ('a * 'a) * nested ('a * 'a) | One of 'a | |||
| let size (x : nested 'a) = | |||
| match x with | |||
| | One _ -> { count = 1 } | |||
| | Nested (a, _) -> { count = 2 * (size a).count } | |||
| ~~~ | |||
| - The newtype elimination pass was rewritten once and, unfortunately, | |||
| disabled, since it was broken with some touchy code. | |||
| - Operator declarations like `let 2 + 2 = 5 in 2 + 2` are admissible. | |||
| - Sanity of optimisations is checked at runtime by running a type | |||
| checker over the intermediate language programs after all optimisations | |||
| - Local opens are allowed, with two syntaxes: Either | |||
| `M.( x + y)`{.ocaml} (or `M.{ a, b }`{.ocaml}) or `let open M in x + | |||
| y`{.ocaml}. | |||
| - Amulet is inconsistent in some more ways, such as `type : type` | |||
| holding. | |||
| - There are no more kinds. | |||
| Conclusion | |||
| ========== | |||
| This post was a bit short, and also a bit hurried. Some of the features | |||
| here deserve better explanations, but I felt like giving them an | |||
| _outline_ (haha) would be better than leaving the blag to rot (yet | |||
| again). | |||
| Watch out for a blog post regarding (at _least_) implicit parameters, | |||
| which will definitely involve the changes to subtyping involving | |||
| records/tuples. | |||
+ 329
- 0
pages/posts/2019-01-28-mldelta.lhs
View File
| @ -0,0 +1,329 @@ | |||
| --- | |||
| title: Compositional Typing for ML | |||
| date: January 28, 2019 | |||
| maths: true | |||
| --- | |||
| \long\def\ignore#1{} | |||
| Compositional type-checking is a neat technique that I first saw in a | |||
| paper by Olaf Chitil[^1]. He introduces a system of principal _typings_, | |||
| as opposed to a system of principal _types_, as a way to address the bad | |||
| type errors that many functional programming languages with type systems | |||
| based on Hindley-Milner suffer from. | |||
| Today I want to present a small type checker for a core ML (with, | |||
| notably, no data types or modules) based roughly on the ideas from that | |||
| paper. This post is _almost_ literate Haskell, but it's not a complete | |||
| program: it only implements the type checker. If you actually want to | |||
| play with the language, grab the unabridged code | |||
| [here](https://github.com/zardyh/mld). | |||
| \ignore{ | |||
| \begin{code} | |||
| {-# LANGUAGE GeneralizedNewtypeDeriving, DerivingStrategies #-} | |||
| \end{code} | |||
| } | |||
| --- | |||
| \begin{code} | |||
| module Typings where | |||
| import qualified Data.Map.Merge.Strict as Map | |||
| import qualified Data.Map.Strict as Map | |||
| import qualified Data.Set as Set | |||
| import Data.Foldable | |||
| import Data.List | |||
| import Data.Char | |||
| import Control.Monad.Except | |||
| \end{code} | |||
| We'll begin, like always, by defining data structures for the language. | |||
| Now, this is a bit against my style, but this system (which I | |||
| shall call ML<sub>$\Delta$</sub> - but only because it sounds cool) is not | |||
| presented as a pure type system - there are separate grammars for terms | |||
| and types. Assume that `Var`{.haskell} is a suitable member of all the | |||
| appropriate type classes. | |||
| \begin{code} | |||
| data Exp | |||
| = Lam Var Exp | |||
| | App Exp Exp | |||
| | Use Var | |||
| | Let (Var, Exp) Exp | |||
| | Num Integer | |||
| deriving (Eq, Show, Ord) | |||
| data Type | |||
| = TyVar Var | |||
| | TyFun Type Type | |||
| | TyCon Var | |||
| deriving (Eq, Show, Ord) | |||
| \end{code} | |||
| ML<sub>$\Delta$</sub> is _painfully_ simple: It's a lambda calculus | |||
| extended with `Let`{.haskell} since there needs to be a demonstration of | |||
| recursion and polymorphism, and numbers so there can be a base type. It | |||
| has no unusual features - in fact, it doesn't have many features at all: | |||
| no rank-N types, GADTs, type classes, row-polymorphic records, tuples or | |||
| even algebraic data types. | |||
| I believe that a fully-featured programming language along the lines of | |||
| Haskell could be shaped out of a type system like this, however I am not | |||
| smart enough and could not find any prior literature on the topic. | |||
| Sadly, it seems that compositional typings aren't a very active area of | |||
| research at all. | |||
| The novelty starts to show up when we define data to represent the | |||
| different kinds of scopes that crop up. There are monomorphic | |||
| $\Delta$-contexts, which assign _types_ to names, and also polymorphic | |||
| $\Gamma$-contexts, that assign _typings_ to names instead. While we're | |||
| defining `newtype`{.haskell}s over `Map`{.haskell}s, let's also get | |||
| substitutions out of the way. | |||
| \begin{code} | |||
| newtype Delta = Delta (Map.Map Var Type) | |||
| deriving (Eq, Ord, Semigroup, Monoid) | |||
| newtype Subst = Subst (Map.Map Var Type) | |||
| deriving (Eq, Show, Ord, Monoid) | |||
| newtype Gamma = Gamma (Map.Map Var Typing) | |||
| deriving (Eq, Show, Ord, Semigroup, Monoid) | |||
| \end{code} | |||
| The star of the show, of course, are the typings themselves. A typing is | |||
| a pair of a (monomorphic) type $\tau$ and a $\Delta$-context, and in a | |||
| way it packages both the type of an expression and the variables it'll | |||
| use from the scope. | |||
| \begin{code} | |||
| data Typing = Typing Delta Type | |||
| deriving (Eq, Show, Ord) | |||
| \end{code} | |||
| With this, we're ready to look at how inference proceeds for | |||
| ML<sub>$\Delta$</sub>. I make no effort at relating the rules | |||
| implemented in code to anything except a vague idea of the rules in the | |||
| paper: Those are complicated, especially since they deal with a language | |||
| much more complicated than this humble calculus. In an effort not to | |||
| embarrass myself, I'll also not present anything "formal". | |||
| --- | |||
| \begin{code} | |||
| infer :: Exp -- The expression we're computing a typing for | |||
| -> Gamma -- The Γ context | |||
| -> [Var] -- A supply of fresh variables | |||
| -> Subst -- The ambient substitution | |||
| -> Either TypeError ( Typing -- The typing | |||
| , [Var] -- New variables | |||
| , Subst -- New substitution | |||
| ) | |||
| \end{code} | |||
| There are two cases when dealing with variables. Either a typing is | |||
| present in the environment $\Gamma$, in which case we just use that | |||
| with some retouching to make sure type variables aren't repeated - this | |||
| takes the place of instantiating type schemes in Hindley-Milner. | |||
| However, a variable can also _not_ be in the environment $\Gamma$, in | |||
| which case we invent a fresh type variable $\alpha$[^2] for it and insist on | |||
| the monomorphic typing $\{ v :: \alpha \} \vdash \alpha$. | |||
| \begin{code} | |||
| infer (Use v) (Gamma env) (new:xs) sub = | |||
| case Map.lookup v env of | |||
| Just ty -> -- Use the typing that was looked up | |||
| pure ((\(a, b) -> (a, b, sub)) (refresh ty xs)) | |||
| Nothing -> -- Make a new one! | |||
| let new_delta = Delta (Map.singleton v new_ty) | |||
| new_ty = TyVar new | |||
| in pure (Typing new_delta new_ty, xs, sub) | |||
| \end{code} | |||
| Interestingly, this allows for (principal!) typings to be given even to | |||
| code containing free variables. The typing for the expression `x`, for | |||
| instance, is reported to be $\{ x :: \alpha \} \vdash \alpha$. Since | |||
| this isn't meant to be a compiler, there's no handling for variables | |||
| being out of scope, so the full inferred typings are printed on the | |||
| REPL- err, RETL? A read-eval-type-loop! | |||
| ``` | |||
| > x | |||
| { x :: a } ⊢ a | |||
| ``` | |||
| Moreover, this system does not have type schemes: Typings subsume those | |||
| as well. Typings explicitly carry information regarding which type | |||
| variables are polymorphic and which are constrained by something in the | |||
| environment, avoiding a HM-like generalisation step. | |||
| \begin{code} | |||
| where | |||
| refresh :: Typing -> [Var] -> (Typing, [Var]) | |||
| refresh (Typing (Delta delta) tau) xs = | |||
| let tau_fv = Set.toList (ftv tau `Set.difference` foldMap ftv delta) | |||
| (used, xs') = splitAt (length tau_fv) xs | |||
| sub = Subst (Map.fromList (zip tau_fv (map TyVar used))) | |||
| in (Typing (applyDelta sub delta) (apply sub tau), xs') | |||
| \end{code} | |||
| `refresh`{.haskell} is responsible for ML<sub>$\Delta$</sub>'s analogue of | |||
| instantiation: New, fresh type variables are invented for each type | |||
| variable free in the type $\tau$ that is not also free in the context | |||
| $\Delta$. Whether or not this is better than $\forall$ quantifiers is up | |||
| for debate, but it is jolly neat. | |||
| The case for application might be the most interesting. We infer two | |||
| typings $\Delta \vdash \tau$ and $\Delta' \vdash \sigma$ for the | |||
| function and the argument respectively, then unify $\tau$ with $\sigma | |||
| \to \alpha$ with $\alpha$ fresh. | |||
| \begin{code} | |||
| infer (App f a) env (alpha:xs) sub = do | |||
| (Typing delta_f type_f, xs, sub) <- infer f env xs sub | |||
| (Typing delta_a type_a, xs, sub) <- infer a env xs sub | |||
| mgu <- unify (TyFun type_a (TyVar alpha)) type_f | |||
| \end{code} | |||
| This is enough to make sure that the expressions involved are | |||
| compatible, but it does not ensure that the _contexts_ attached are also | |||
| compatible. So, the substitution is applied to both contexts and they | |||
| are merged - variables present in one but not in the other are kept, and | |||
| variables present in both have their types unified. | |||
| \begin{code} | |||
| let delta_f' = applyDelta mgu delta_f | |||
| delta_a' = applyDelta mgu delta_a | |||
| delta_fa <- mergeDelta delta_f' delta_a' | |||
| pure (Typing delta_fa (apply mgu (TyVar alpha)), xs, sub <> mgu) | |||
| \end{code} | |||
| If a variable `x` has, say, type `Bool` in the function's context but `Int` | |||
| in the argument's context - that's a type error, one which that can be | |||
| very precisely reported as an inconsistency in the types `x` is used at | |||
| when trying to type some function application. This is _much_ better than | |||
| the HM approach, which would just claim the latter usage is wrong. | |||
| There are three spans of interest, not one. | |||
| Inference for $\lambda$ abstractions is simple: We invent a fresh | |||
| monomorphic typing for the bound variable, add it to the context when | |||
| inferring a type for the body, then remove that one specifically from | |||
| the typing of the body when creating one for the overall abstraction. | |||
| \begin{code} | |||
| infer (Lam v b) (Gamma env) (alpha:xs) sub = do | |||
| let ty = TyVar alpha | |||
| mono_typing = Typing (Delta (Map.singleton v ty)) ty | |||
| new_env = Gamma (Map.insert v mono_typing env) | |||
| (Typing (Delta body_delta) body_ty, xs, sub) <- infer b new_env xs sub | |||
| let delta' = Delta (Map.delete v body_delta) | |||
| pure (Typing delta' (apply sub (TyFun ty body_ty)), xs, sub) | |||
| \end{code} | |||
| Care is taken to apply the ambient substitution to the type of the | |||
| abstraction so that details learned about the bound variable inside the | |||
| body will be reflected in the type. This could also be extracted from | |||
| the typing of the body, I suppose, but _eh_. | |||
| `let`{.haskell}s are very easy, especially since generalisation is | |||
| implicit in the structure of typings. We simply compute a typing from | |||
| the body, _reduce_ it with respect to the let-bound variable, add it to | |||
| the environment and infer a typing for the body. | |||
| \begin{code} | |||
| infer (Let (var, exp) body) gamma@(Gamma env) xs sub = do | |||
| (exp_t, xs, sub) <- infer exp gamma xs sub | |||
| let exp_s = reduceTyping var exp_t | |||
| gamma' = Gamma (Map.insert var exp_s env) | |||
| infer body gamma' xs sub | |||
| \end{code} | |||
| Reduction w.r.t. a variable `x` is a very simple operation that makes | |||
| typings as polymorphic as possible, by deleting entries whose free type | |||
| variables are disjoint with the overall type along with the entry for | |||
| `x`. | |||
| \begin{code} | |||
| reduceTyping :: Var -> Typing -> Typing | |||
| reduceTyping x (Typing (Delta delta) tau) = | |||
| let tau_fv = ftv tau | |||
| delta' = Map.filter keep (Map.delete x delta) | |||
| keep sigma = not $ Set.null (ftv sigma `Set.intersection` tau_fv) | |||
| in Typing (Delta delta') tau | |||
| \end{code} | |||
| --- | |||
| Parsing, error reporting and user interaction do not have interesting | |||
| implementations, so I have chosen not to include them here. | |||
| Compositional typing is a very promising approach for languages with | |||
| simple polymorphic type systems, in my opinion, because it presents a | |||
| very cheap way of providing very accurate error messages much better | |||
| than those of Haskell, OCaml and even Elm, a language for which good | |||
| error messages are an explicit goal. | |||
| As an example of this, consider the expression `fun x -> if x (add x 0) | |||
| 1`{.ocaml} (or, in Haskell, `\x -> if x then (x + (0 :: Int)) else (1 :: | |||
| Int)`{.haskell} - the type annotations are to emulate | |||
| ML<sub>$\Delta$</sub>'s insistence on monomorphic numbers). | |||
| Types Bool and Int aren't compatible | |||
| When checking that all uses of 'x' agree | |||
| When that checking 'if x' (of type e -> e -> e) | |||
| can be applied to 'add x 0' (of type Int) | |||
| Typing conflicts: | |||
| · x : Bool vs. Int | |||
| The error message generated here is much better than the one GHC | |||
| reports, if you ask me. It points out not that x has some "actual" type | |||
| distinct from its "expected" type, as HM would conclude from its | |||
| left-to-right bias, but rather that two uses of `x` aren't compatible. | |||
| <interactive>:4:18: error: | |||
| • Couldn't match expected type ‘Int’ with actual type ‘Bool’ | |||
| • In the expression: (x + 0 :: Int) | |||
| In the expression: if x then (x + 0 :: Int) else 0 | |||
| In the expression: \ x -> if x then (x + 0 :: Int) else 0 | |||
| Of course, the prototype doesn't care for positions, so the error | |||
| message is still not as good as it could be. | |||
| Perhaps it should be further investigated whether this approach scales | |||
| to at least type classes (since a form of ad-hoc polymorphism is | |||
| absolutely needed) and polymorphic records, so that it can be used in a | |||
| real language. I have my doubts as to if a system like this could | |||
| reasonably be extended to support rank-N types, since it does not have | |||
| $\forall$ quantifiers. | |||
| **UPDATE**: I found out that extending a compositional typing system to | |||
| support type classes is not only possible, it was also [Gergő Érdi's MSc. | |||
| thesis](https://gergo.erdi.hu/projects/tandoori/)! | |||
| **UPDATE**: Again! This is new. Anyway, I've cleaned up the code and | |||
| [thrown it up on GitHub](https://github.com/zardyh/mld). | |||
| Again, a full program implementing ML<sub>$\Delta$</sub> is available | |||
| [here](https://github.com/zardyh/mld). | |||
| Thank you for reading! | |||
| [^1]: Olaf Chitil. 2001. Compositional explanation of types and | |||
| algorithmic debugging of type errors. In Proceedings of the sixth ACM | |||
| SIGPLAN international conference on Functional programming (ICFP '01). | |||
| ACM, New York, NY, USA, 193-204. | |||
| [DOI](http://dx.doi.org/10.1145/507635.507659). | |||
| [^2]: Since I couldn't be arsed to set up monad transformers and all, | |||
| we're doing this the lazy way (ba dum tss): an infinite list of | |||
| variables, and hand-rolled reader/state monads. | |||
+ 191
- 0
pages/posts/2019-09-22-amulet-records.md
View File
| @ -0,0 +1,191 @@ | |||
| --- | |||
| title: "A Quickie: Manipulating Records in Amulet" | |||
| date: September 22, 2019 | |||
| maths: true | |||
| --- | |||
| Amulet, unlike some [other languages], has records figured out. Much like | |||
| in ML (and PureScript), they are their own, first-class entities in the | |||
| language as opposed to being syntax sugar for defining a product | |||
| constructor and projection functions. | |||
| ### Records are good | |||
| Being entities in the language, it's logical to characterize them by | |||
| their introduction and elimination judgements[^1]. | |||
| Records are introduced with record literals: | |||
| $$ | |||
| \frac{ | |||
| \Gamma \vdash \overline{e \downarrow \tau} | |||
| }{ | |||
| \Gamma \vdash \{ \overline{\mathtt{x} = e} \} \downarrow \{ \overline{\mathtt{x} : \tau} \} | |||
| } | |||
| $$ | |||
| And eliminated by projecting a single field: | |||
| $$ | |||
| \frac{ | |||
| \Gamma \vdash r \downarrow \{ \alpha | \mathtt{x} : \tau \} | |||
| }{ | |||
| \Gamma \vdash r.\mathtt{x} \uparrow \tau | |||
| } | |||
| $$ | |||
| Records also support monomorphic update: | |||
| $$ | |||
| \frac{ | |||
| \Gamma \vdash r \downarrow \{ \alpha | \mathtt{x} : \tau \} | |||
| \quad \Gamma \vdash e \downarrow \tau | |||
| }{ | |||
| \Gamma \vdash \{ r\ \mathtt{with\ x} = e \} \downarrow \{ \alpha | \mathtt{x} : \tau \} | |||
| } | |||
| $$ | |||
| ### Records are.. kinda bad? | |||
| Unfortunately, the rather minimalistic vocabulary for talking about | |||
| records makes them slightly worthless. There's no way to extend a | |||
| record, or to remove a key; Changing the type of a key is also | |||
| forbidden, with the only workaround being enumerating all of the keys | |||
| you _don't_ want to change. | |||
| And, rather amusingly, given the trash-talking I pulled in the first | |||
| paragraph, updating nested records is still a nightmare. | |||
| ```amulet | |||
| > let my_record = { x = 1, y = { z = 3 } } | |||
| my_record : { x : int, y : { z : int } } | |||
| > { my_record with y = { my_record.y with z = 4 } } | |||
| _ = { x = 1, y = { z = 4 } } | |||
| ``` | |||
| Yikes. Can we do better? | |||
| ### An aside: Functional Dependencies | |||
| Amulet recently learned how to cope with [functional dependencies]. | |||
| Functional dependencies extend multi-param type classes by allowing the | |||
| programmer to restrict the relationships between parameters. To | |||
| summarize it rather terribly: | |||
| ```amulet | |||
| (* an arbitrary relationship between types *) | |||
| class r 'a 'b | |||
| (* a function between types *) | |||
| class f 'a 'b | 'a -> 'b | |||
| (* a one-to-one mapping *) | |||
| class o 'a 'b | 'a -> 'b, 'b -> 'a | |||
| ``` | |||
| ### Never mind, records are good | |||
| As of [today], Amulet knows the magic `row_cons` type class, inspired by | |||
| [PureScript's class of the same name]. | |||
| ```amulet | |||
| class | |||
| row_cons 'record ('key : string) 'type 'new | |||
| | 'record 'key 'type -> 'new (* 1 *) | |||
| , 'new 'key -> 'record 'type (* 2 *) | |||
| begin | |||
| val extend_row : forall 'key -> 'type -> 'record -> 'new | |||
| val restrict_row : forall 'key -> 'new -> 'type * 'record | |||
| end | |||
| ``` | |||
| This class has built-in solving rules corresponding to the two | |||
| functional dependencies: | |||
| 1. If the original `record`, the `key` to be inserted, and its | |||
| `type` are all known, then the `new` record can be solved for; | |||
| 2. If both the `key` that was inserted, and the `new` record, it is | |||
| possible to solve for the old `record` and the `type` of the `key`. | |||
| Note that rule 2 almost lets `row_cons` be solved for in reverse. Indeed, this is expressed by the type of `restrict_row`, which discovers both the `type` and the original `record`. | |||
| Using the `row_cons` class and its magical methods... | |||
| 1. Records can be extended: | |||
| ```amulet | |||
| > Amc.extend_row @"foo" true { x = 1 } | |||
| _ : { foo : bool, x : int } = | |||
| { foo = true, x = 1 } | |||
| ``` | |||
| 2. Records can be restricted: | |||
| ```amulet | |||
| > Amc.restrict_row @"x" { x = 1 } | |||
| _ : int * { } = (1, { x = 1 }) | |||
| ``` | |||
| And, given [a suitable framework of optics], records can be updated | |||
| nicely: | |||
| ```amulet | |||
| > { x = { y = 2 } } |> (r @"x" <<< r @"y") ^~ succ | |||
| _ : { x : { y : int } } = | |||
| { x = { y = 3 } } | |||
| ``` | |||
| ### God, those are some ugly types | |||
| It's worth pointing out that making an optic that works for all fields, | |||
| parametrised by a type-level string, is not easy or pretty, but it is | |||
| work that only needs to be done once. | |||
| ```ocaml | |||
| type optic 'p 'a 's <- 'p 'a 'a -> 'p 's 's | |||
| class | |||
| Amc.row_cons 'r 'k 't 'n | |||
| => has_lens 'r 'k 't 'n | |||
| | 'k 'n -> 'r 't | |||
| begin | |||
| val rlens : strong 'p => proxy 'k -> optic 'p 't 'n | |||
| end | |||
| instance | |||
| Amc.known_string 'key | |||
| * Amc.row_cons 'record 'key 'type 'new | |||
| => has_lens 'record 'key 'type 'new | |||
| begin | |||
| let rlens _ = | |||
| let view r = | |||
| let (x, _) = Amc.restrict_row @'key r | |||
| x | |||
| let set x r = | |||
| let (_, r') = Amc.restrict_row @'key r | |||
| Amc.extend_row @'key x r' | |||
| lens view set | |||
| end | |||
| let r | |||
| : forall 'key -> forall 'record 'type 'new 'p. | |||
| Amc.known_string 'key | |||
| * has_lens 'record 'key 'type 'new | |||
| * strong 'p | |||
| => optic 'p 'type 'new = | |||
| fun x -> rlens @'record (Proxy : proxy 'key) x | |||
| ``` | |||
| --- | |||
| Sorry for the short post, but that's it for today. | |||
| --- | |||
| [^1]: Record fields $\mathtt{x}$ are typeset in monospaced font to make | |||
| it apparent that they are unfortunately not first-class in the language, | |||
| but rather part of the syntax. Since Amulet's type system is inherently | |||
| bidirectional, the judgement $\Gamma \vdash e \uparrow \tau$ represents | |||
| type inference while $\Gamma \vdash e \downarrow \tau$ stands for type | |||
| checking. | |||
| [functional dependencies]: https://web.cecs.pdx.edu/~mpj/pubs/fundeps.html | |||
| [other languages]: https://haskell.org | |||
| [today]: https://github.com/tmpim/amulet/pull/168 | |||
| [PureScript's class of the same name]: https://pursuit.purescript.org/builtins/docs/Prim.Row#t:Cons | |||
| [a suitable framework of optics]: /static/profunctors.ml.html | |||
+ 136
- 0
pages/posts/2019-09-25-amc-prove.md
View File
| @ -0,0 +1,136 @@ | |||
| --- | |||
| title: "Announcement: amc-prove" | |||
| date: September 25, 2019 | |||
| maths: true | |||
| --- | |||
| `amc-prove` is a smallish tool to automatically prove (some) sentences | |||
| of constructive quantifier-free[^1] first-order logic using the Amulet | |||
| compiler's capability to suggest replacements for typed holes. | |||
| In addition to printing whether or not it could determine the truthiness | |||
| of the sentence, `amc-prove` will also report the smallest proof term it | |||
| could compute of that type. | |||
| ### What works right now | |||
| * Function types `P -> Q`{.amcprove}, corresponding to $P \to Q$ in the logic. | |||
| * Product types `P * Q`{.amcprove}, corresponding to $P \land Q$ in the logic. | |||
| * Sum types `P + Q`{.amcprove}, corresponding to $P \lor Q$ in the logic | |||
| * `tt`{.amcprove} and `ff`{.amcprove} correspond to $\top$ and $\bot$ respectively | |||
| * The propositional bi-implication type `P <-> Q`{.amcprove} stands for $P \iff Q$ | |||
| and is interpreted as $P \to Q \land Q \to P$ | |||
| ### What is fiddly right now | |||
| Amulet will not attempt to pattern match on a sum type nested inside a | |||
| product type. Concretely, this means having to replace $(P \lor Q) \land | |||
| R \to S$ by $(P \lor Q) \to R \to S$ (currying). | |||
| `amc-prove`'s support for negation and quantifiers is incredibly fiddly. | |||
| There is a canonical empty type, `ff`{.amcprove}, but the negation | |||
| connective `not P`{.amcprove} expands to `P -> forall 'a. | |||
| 'a`{.amcprove}, since empty types aren't properly supported. As a | |||
| concrete example, take the double-negation of the law of excluded middle | |||
| $\neg\neg(P \lor \neg{}P)$, which holds constructively. | |||
| If you enter the direct translation of that sentence as a type, | |||
| `amc-prove` will report that it couldn't find a solution. However, by | |||
| using `P -> ff`{.amc-prove} instead of `not P`{.amc-prove}, a solution is | |||
| found. | |||
| ```amc-prove | |||
| ? not (not (P + not P)) | |||
| probably not. | |||
| ? ((P + (P -> forall 'a. 'a)) -> forall 'a. 'a) -> forall 'a. 'a | |||
| probably not. | |||
| ? ((P + (P -> ff)) -> ff) -> ff | |||
| yes. | |||
| fun f -> f (R (fun b -> f (L b))) | |||
| ``` | |||
| ### How to get it | |||
| `amc-prove` is bundled with the rest of the Amulet compiler [on Github]. | |||
| You'll need [Stack] to build. I recommend building with `stack build | |||
| --fast` since the compiler is rather large and `amc-prove` does not | |||
| benefit much from GHC's optimisations. | |||
| ``` | |||
| % git clone https://github.com/tmpim/amc-prove.git | |||
| % cd amc-prove | |||
| % stack build --fast | |||
| % stack run amc-prove | |||
| Welcome to amc-prove. | |||
| ? | |||
| ``` | |||
| ### Usage sample | |||
| Here's a small demonstration of everything that works. | |||
| ```amc-prove | |||
| ? P -> P | |||
| yes. | |||
| fun b -> b | |||
| ? P -> Q -> P | |||
| yes. | |||
| fun a b -> a | |||
| ? Q -> P -> P | |||
| yes. | |||
| fun a b -> b | |||
| ? (P -> Q) * P -> Q | |||
| yes. | |||
| fun (h, x) -> h x | |||
| ? P * Q -> P | |||
| yes. | |||
| fun (z, a) -> z | |||
| ? P * Q -> Q | |||
| yes. | |||
| fun (z, a) -> a | |||
| ? P -> Q -> P * Q | |||
| yes. | |||
| fun b c -> (b, c) | |||
| ? P -> P + Q | |||
| yes. | |||
| fun y -> L y | |||
| ? Q -> P + Q | |||
| yes. | |||
| fun y -> R y | |||
| ? (P -> R) -> (Q -> R) -> P + Q -> R | |||
| yes. | |||
| fun g f -> function | |||
| | (L y) -> g y | |||
| | (R c) -> f c | |||
| ? not (P * not P) | |||
| yes. | |||
| Not (fun (a, (Not h)) -> h a) | |||
| (* Note: Only one implication of DeMorgan's second law holds | |||
| constructively *) | |||
| ? not (P + Q) <-> (not P) * (not Q) | |||
| yes. | |||
| (* Note: I have a marvellous term to prove this proposition, | |||
| but unfortunately it is too large to fit in this margin. *) | |||
| ? (not P) + (not Q) -> not (P * Q) | |||
| yes. | |||
| function | |||
| | (L (Not f)) -> | |||
| Not (fun (a, b) -> f a) | |||
| | (R (Not g)) -> | |||
| Not (fun (y, z) -> g z) | |||
| ``` | |||
| [^1]: Technically, amc-prove "supports" the entire Amulet type system, | |||
| which includes things like type-classes and rank-N types (it's equal in | |||
| expressive power to System F). However, the hole-filling logic is meant | |||
| to aid the programmer while she codes, not exhaustively search for a | |||
| solution, so it was written to fail early and fail fast instead of | |||
| spending unbounded time searching for a solution that might not be | |||
| there. | |||
| You can find the proof term I redacted from DeMorgan's first law [here]. | |||
| [on Github]: https://github.com/tmpim/amulet | |||
| [Stack]: https://haskellstack.org | |||
| [here]: /static/demorgan-1.ml.html | |||
+ 202
- 0
pages/posts/2019-09-29-amc-prove-interactive.md
View File
| @ -0,0 +1,202 @@ | |||
| --- | |||
| title: Interactive amc-prove | |||
| date: September 29, 2019 | |||
| --- | |||
| Following my [last post announcing amc-prove](/posts/2019-09-25.html), I | |||
| decided I'd make it more accessible to people who wouldn't like to spend | |||
| almost 10 minutes compiling Haskell code just to play with a fiddly | |||
| prover. | |||
| So I made a web interface for the thing: Play with it below. | |||
| Text immediately following <span style='color:red'>> </span> is editable. | |||
| <noscript> | |||
| Sorry, this post isn't for you. | |||
| </noscript> | |||
| <div id='prover-container'> | |||
| <div id='prover'> | |||
| <pre id='prover-output'> | |||
| <span style='color: red' id=prover-prompt>> </span><span id='prover-input' contenteditable='true'>(not P) + (not Q) -> not (P * Q)</span> | |||
| </pre> | |||
| </div> | |||
| </div> | |||
| <style> | |||
| div#prover-container { | |||
| width: 100%; | |||
| height: 600px; | |||
| border: 1px solid #c0c0c0; | |||
| background: #d6d6d6; | |||
| box-shadow: 1px 1px #c0c0c0; | |||
| border-radius: 0.3em; | |||
| } | |||
| div#prover { | |||
| width: 100%; | |||
| height: 100%; | |||
| overflow-y: scroll; | |||
| } | |||
| pre#prover-output, pre#prover-output > * { | |||
| white-space: pre-wrap; | |||
| } | |||
| span#prover-input { | |||
| border: 1px solid #c0c0c0; | |||
| font-family: monospace; | |||
| } | |||
| </style> | |||
| <script async> | |||
| let input = document.getElementById('prover-input'); | |||
| let output = document.getElementById('prover-output'); | |||
| let prompt = document.getElementById('prover-prompt'); | |||
| let ERROR_REGEX = /^\<input\>\[(\d+):(\d+) \.\.(\d+):(\d+)\]: error$/; | |||
| let NEGATIVE_REGEX = /^probably not\.$/; | |||
| let prove = async (sentence) => { | |||
| let response; | |||
| try { | |||
| response = await fetch('/prove', { | |||
| method: 'POST', | |||
| headers: { | |||
| Host: '/prove' | |||
| }, | |||
| body: sentence | |||
| }); | |||
| } catch (e) { | |||
| return { error: true, error_msg: ['Server responded with an error'] } | |||
| } | |||
| const prover_response = (await response.text()).split('\n').map(x => x.trimEnd()).filter(x => x !== ''); | |||
| const result_line = prover_response[0]; | |||
| console.log(result_line); | |||
| console.log(result_line.match(ERROR_REGEX)); | |||
| if (response.status !== 200) { | |||
| return { error: true, error_msg: ['Server responded with an error'] } | |||
| } else if (result_line.match(ERROR_REGEX) !== null) { | |||
| return { error: true, error_msg: prover_response.slice(1) } | |||
| } else if (result_line.match(NEGATIVE_REGEX) !== null) { | |||
| return { error: false, proven: false } | |||
| } else { | |||
| return { error: false, proven: true, proof: prover_response.slice(1) }; | |||
| } | |||
| }; | |||
| const LEX_RULES = [ | |||
| [/^(fun(ction)?|match|not)/, 'kw'], | |||
| [/^[a-z][a-z0-9]*/, 'va'], | |||
| [/^[A-Z][A-Za-z0-9]*/, 'dt'], | |||
| [/^[\(\)\[\]<->\+\*\-,|]/, 'va'] | |||
| ]; | |||
| let tokenise = (code) => { | |||
| let tokens = [] | |||
| let exit = false; | |||
| while (code !== '' && !exit) { | |||
| let matched_this_loop = false; | |||
| LEX_RULES.map(([regex, clss]) => { | |||
| let had_spc = code.match(/^\s*/)[0] | |||
| let match = code.trimStart().match(regex); | |||
| if (match !== null) { | |||
| let matched = match[0]; | |||
| code = code.trimStart().slice(matched.length); | |||
| tokens.push({ t: had_spc + matched, c : clss }); | |||
| matched_this_loop = true; | |||
| }; | |||
| }); | |||
| if (!matched_this_loop) { | |||
| exit = true; | |||
| tokens.push({ t : code, c : 'va' }); | |||
| } | |||
| } | |||
| return tokens; | |||
| } | |||
| let syntax_highlight = (code) => { | |||
| let container = document.createElement('span'); | |||
| code.map(line => { | |||
| let elems = tokenise(line).map(token => { | |||
| let span = document.createElement('span'); | |||
| span.innerText = token.t; | |||
| span.classList.add(token.c); | |||
| container.appendChild(span); | |||
| }); | |||
| container.appendChild(document.createElement('br')); | |||
| }); | |||
| return container; | |||
| } | |||
| let history = []; | |||
| let history_index = 0; | |||
| input.onkeydown = async (e) => { | |||
| let key = e.key || e.which; | |||
| if (key == 'Enter' && !e.shiftKey) { | |||
| e.preventDefault(); | |||
| let text = input.innerText; | |||
| history_index = -1; | |||
| if (text !== history[history.length - 1]) { | |||
| history.push(text); | |||
| } | |||
| let result = await prove(text); | |||
| let old_input = syntax_highlight(['> ' + text]); | |||
| let out_block = document.createElement('span'); | |||
| if (result.error) { | |||
| out_block.style = 'color: red'; | |||
| out_block.innerText = 'error:\n'; | |||
| result.error_msg.slice(0, 1).map(e => { | |||
| let span = document.createElement('span'); | |||
| span.style = 'color: red'; | |||
| span.innerText = ' ' + e + '\n'; | |||
| out_block.appendChild(span); | |||
| }); | |||
| } else if (result.proven) { | |||
| out_block.classList.add('kw'); | |||
| out_block.innerText = 'yes:\n' | |||
| out_block.appendChild(syntax_highlight(result.proof)); | |||
| } else { | |||
| out_block.classList.add('kw'); | |||
| out_block.innerText = 'not proven\n'; | |||
| } | |||
| input.innerText = ''; | |||
| output.insertBefore(old_input, prompt); | |||
| output.insertBefore(out_block, prompt); | |||
| input.scrollIntoView(); | |||
| } else if (key === 'Up' || key === 'ArrowUp') { | |||
| e.preventDefault(); | |||
| console.log(history, history_index) | |||
| if(history_index > 0) { | |||
| history_index--; | |||
| } else if(history_index < 0 && history.length > 0) { | |||
| history_index = history.length - 1 | |||
| } else { | |||
| return; | |||
| } | |||
| input.innerText = history[history_index]; | |||
| input.focus(); | |||
| } else if (key == 'Down' || key === 'ArrowDown') { | |||
| e.preventDefault(); | |||
| if(history_index >= 0) { | |||
| history_index = history_index < history.length - 1 ? history_index + 1 : -1; | |||
| } else { | |||
| return; | |||
| } | |||
| input.innerText = history[history_index] || ''; | |||
| } | |||
| } | |||
| </script> | |||
+ 369
- 0
pages/posts/2019-10-04-amulet-kinds.md
View File
| @ -0,0 +1,369 @@ | |||
| --- | |||
| title: Typed Type-Level Computation in Amulet | |||
| date: October 04, 2019 | |||
| maths: true | |||
| --- | |||
| Amulet, as a programming language, has a focus on strong static typing. This has led us to adopt | |||
| many features inspired by dependently-typed languages, the most prominent of which being typed holes | |||
| and GADTs, the latter being an imitation of indexed families. | |||
| However, Amulet was up until recently sorely lacking in a way to express computational content in | |||
| types: It was possible to index datatypes by other, regular datatypes ("datatype promotion", in the | |||
| Haskell lingo) since the type and kind levels are one and the same, but writing functions on those | |||
| indices was entirely impossible. | |||
| As of this week, the language supports two complementary mechanisms for typed type-level programming: | |||
| _type classes with functional dependencies_, a form of logic programming, and _type functions_, which | |||
| permit functional programming on the type level. | |||
| I'll introduce them in that order; This post is meant to serve as an introduction to type-level | |||
| programming using either technique in general, but it'll also present some concepts formally and with | |||
| some technical depth. | |||
| ### Type Classes are Relations: Programming with Fundeps | |||
| In set theory[^1] a _relation_ $R$ over a family of sets $A, B, C, \dots$ is a subset of the | |||
| cartesian product $A \times B \times C \times \dots$. If $(a, b, c, \dots) \in R_{A,B,C,\dots}$ we | |||
| say that $a$, $b$ and $c$ are _related_ by $R$. | |||
| In this context, a _functional dependency_ is a term $X \leadsto Y$ | |||
| where $X$ and $Y$ are both sets of natural numbers. A relation is said | |||
| to satisfy a functional dependency $X \leadsto Y$ when, for any tuple in | |||
| the relation, the values at $X$ uniquely determine the values at $Y$. | |||
| For instance, the relations $R_{A,B}$ satisfying $\{0\} \leadsto \{1\}$ are partial functions $A \to | |||
| B$, and if it were additionally to satisfy $\{1\} \leadsto \{0\}$ it would be a partial one-to-one | |||
| mapping. | |||
| One might wonder what all of this abstract nonsense[^2] has to do with type classes. The thing is, a | |||
| type class `class foo : A -> B -> constraint`{.amulet} is a relation $\text{Foo}_{A,B}$! With this in | |||
| mind, it becomes easy to understand what it might mean for a type class to satisfy a functional | |||
| relation, and indeed the expressive power that they bring. | |||
| To make it concrete: | |||
| ```amulet | |||
| class r 'a 'b (* an arbitrary relation between a and b *) | |||
| class f 'a 'b | 'a -> 'b (* a function from a to b *) | |||
| class i 'a 'b | 'a -> 'b, 'b -> 'a (* a one-to-one mapping between a and b *) | |||
| ``` | |||
| #### The Classic Example: Collections | |||
| In Mark P. Jones' paper introducing functional dependencies, he presents as an example the class | |||
| `collects : type -> type -> constraint`{.amulet}, where `'e`{.amulet} is the type of elements in the | |||
| collection type `'ce`{.amulet}. This class can be used for all the standard, polymorphic collections | |||
| (of kind `type -> type`{.amulet}), but it also admits instances for monomorphic collections, like a | |||
| `bitset`. | |||
| ```amulet | |||
| class collects 'e 'ce begin | |||
| val empty : 'ce | |||
| val insert : 'e -> 'ce -> 'ce | |||
| val member : 'e -> 'ce -> bool | |||
| end | |||
| ``` | |||
| Omitting the standard implementation details, this class admits instances like: | |||
| ```amulet | |||
| class eq 'a => collects 'a (list 'a) | |||
| class eq 'a => collects 'a ('a -> bool) | |||
| instance collects char string (* amulet strings are not list char *) | |||
| ``` | |||
| However, Jones points out this class, as written, has a variety of problems. For starters, `empty`{.amulet} has | |||
| an ambiguous type, `forall 'e 'ce. collects 'e 'ce => 'ce`{.amulet}. This type is ambiguous because the type | |||
| varialbe `e`{.amulet} is $\forall$-bound, and appears in the constraint `collects 'e 'ce`{.amulet}, but doesn't | |||
| appear to the right of the `=>`{.amulet}; Thus, we can't solve it using unification, and the program | |||
| would have undefined semantics. | |||
| Moreover, this class leads to poor inferred types. Consider the two functions `f`{.amulet} and `g`, below. | |||
| These have the types `(collects 'a 'c * collects 'b 'c) => 'a -> 'b -> 'c -> 'c`{.amulet} and | |||
| `(collects bool 'c * collects int 'c) => 'c -> 'c`{.amulet} respectively. | |||
| ```amulet | |||
| let f x y coll = insert x (insert y coll) | |||
| let g coll = f true 1 coll | |||
| ``` | |||
| The problem with the type of `f`{.amulet} is that it is too general, if we wish to model homogeneous | |||
| collections only; This leads to the type of `g`, which really ought to be a type error, but isn't; The | |||
| programming error in its definition won't be reported here, but at the use site, which might be in a | |||
| different module entirely. This problem of poor type inference and bad error locality motivates us to | |||
| refine the class `collects`, adding a functional dependency: | |||
| ```amulet | |||
| (* Read: 'ce determines 'e *) | |||
| class collects 'e 'ce | 'ce -> 'e begin | |||
| val empty : 'ce | |||
| val insert : 'e -> 'ce -> 'ce | |||
| val member : 'e -> 'ce -> bool | |||
| end | |||
| ``` | |||
| This class admits all the same instances as before, but now the functional dependency lets Amulet | |||
| infer an improved type for `f`{.amulet} and report the type error at `g`{.amulet}. | |||
| ```amulet | |||
| val f : collects 'a 'b => 'a -> 'a -> 'b -> 'b | |||
| ``` | |||
| ``` | |||
| │ | |||
| 2 │ let g coll = f true 1 coll | |||
| │ ^ | |||
| Couldn't match actual type int | |||
| with the type expected by the context, bool | |||
| ``` | |||
| One can see from the type of `f`{.amulet} that Amulet can simplify the conjunction of constraints | |||
| `collects 'a 'c * collects 'b 'c`{.amulet} into `collects 'a 'c`{.amulet} and substitute `'b`{.amulet} | |||
| for `'a`{.amulet} in the rest of the type. This is because the second parameter of `collects`{.amulet} | |||
| is enough to determine the first parameter; Since `'c`{.amulet} is obviously equal to itself, | |||
| `'a`{.amulet} must be equal to `'b`. | |||
| We can observe improvement within the language using a pair of data types, `(:-) : constraint -> | |||
| constraint -> type`{.amulet} and `dict : constraint -> type`{.amulet}, which serve as witnesses of | |||
| implication between constraints and a single constraint respectively. | |||
| ```amulet | |||
| type dict 'c = Dict : 'c => dict 'c | |||
| type 'p :- 'q = Sub of ('p => unit -> dict 'q) | |||
| let improve : forall 'a 'b 'c. (collects 'a 'c * collects 'b 'c) :- ('a ~ 'b) = | |||
| Sub (fun _ -> Dict) | |||
| ``` | |||
| Because this program type-checks, we can be sure that `collects 'a 'c * collects 'b 'c`{.amulet} | |||
| implies `'a`{.amulet} is equal to `'b`{.amulet}. Neat! | |||
| ### Computing with Fundeps: Natural Numbers and Vectors | |||
| If you saw this coming, pat yourself on the back. | |||
| I'm required by law to talk about vectors in every post about types. No, really; It's true. | |||
| I'm sure everyone's seen this by now, but vectors are cons-lists indexed by their type as a Peano | |||
| natural. | |||
| ```amulet | |||
| type nat = Z | S of nat | |||
| type vect 'n 'a = | |||
| | Nil : vect Z 'a | |||
| | Cons : 'a * vect 'n 'a -> vect (S 'n) 'a | |||
| ``` | |||
| Our running objective for this post will be to write a function to append two vectors, such that the | |||
| length of the result is the sum of the lengths of the arguments.[^3] But, how do we even write the | |||
| type of such a function? | |||
| Here we can use a type class with functional dependencies witnessing the fact that $a + b = c$, for | |||
| some $a$, $b$, $c$ all in $\mathbb{N}$. Obviously, knowing $a$ and $b$ is enough to know $c$, and the | |||
| functional dependency expresses that. Due to the way we're going to be implementing `add`, the other | |||
| two functional dependencies aren't admissible. | |||
| ```amulet | |||
| class add 'a 'b 'c | 'a 'b -> 'c begin end | |||
| ``` | |||
| Adding zero to something just results in that something, and if $a + b = c$ then $(1 + a) + b = 1 + c$. | |||
| ```amulet | |||
| instance add Z 'a 'a begin end | |||
| instance add 'a 'b 'c => add (S 'a) 'b (S 'c) begin end | |||
| ``` | |||
| With this in hands, we can write a function to append vectors. | |||
| ```amulet | |||
| let append : forall 'n 'k 'm 'a. add 'n 'k 'm | |||
| => vect 'n 'a -> vect 'k 'a -> vect 'm 'a = | |||
| fun xs ys -> | |||
| match xs with | |||
| | Nil -> ys | |||
| | Cons (x, xs) -> Cons (x, append xs ys) | |||
| ``` | |||
| Success! | |||
| ... or maybe not. Amulet's complaining about our definition of `append` even though it's correct; What | |||
| gives? | |||
| The problem is that while functional dependencies let us conclude equalities from pairs of instances, | |||
| it doesn't do us any good if there's a single instance. So we need a way to reflect the equalities in | |||
| a way that can be pattern-matched on. If your GADT senses are going off, that's a good thing. | |||
| #### Computing with Evidence | |||
| This is terribly boring to do and what motivated me to add type functions to Amulet in the first | |||
| place, but the solution here is to have a GADT that mirrors the structure of the class instances, and | |||
| make the instances compute that. Then, in our append function, we can match on this evidence to reveal | |||
| equalities to the type checker. | |||
| ```amulet | |||
| type add_ev 'k 'n 'm = | |||
| | AddZ : add_ev Z 'a 'a | |||
| | AddS : add_ev 'a 'b 'c -> add_ev (S 'a) 'b (S 'c) | |||
| class add 'a 'b 'c | 'a 'b -> 'c begin | |||
| val ev : add_ev 'a 'b 'c | |||
| end | |||
| instance add Z 'a 'a begin | |||
| let ev = AddZ | |||
| end | |||
| instance add 'a 'b 'c => add (S 'a) 'b (S 'c) begin | |||
| let ev = AddS ev | |||
| end | |||
| ``` | |||
| Now we can write vector `append` using the `add_ev` type. | |||
| ```amulet | |||
| let append' (ev : add_ev 'n 'm 'k) | |||
| (xs : vect 'n 'a) | |||
| (ys : vect 'm 'a) | |||
| : vect 'k 'a = | |||
| match ev, xs with | |||
| | AddZ, Nil -> ys | |||
| | AddS p, Cons (x, xs) -> Cons (x, append' p xs ys) | |||
| and append xs ys = append' ev xs ys | |||
| ``` | |||
| This type-checks and we're done. | |||
| ### Functions on Types: Programming with Closed Type Functions | |||
| Look, duplicating the structure of a type class at the value level just so the compiler can figure out | |||
| equalities is stupid. Can't we make it do that work instead? Enter _closed type functions_. | |||
| ```amulet | |||
| type function (+) 'n 'm begin | |||
| Z + 'n = 'n | |||
| (S 'k) + 'n = S ('k + 'n) | |||
| end | |||
| ``` | |||
| This declaration introduces the type constructor `(+)`{.amulet} (usually written infix) and two rules | |||
| for reducing types involving saturated applications of `(+)`{.amulet}. Type functions, unlike type | |||
| classes which are defined like Prolog clauses, are defined in a pattern-matching style reminiscent of | |||
| Haskell. | |||
| Each type function has a set of (potentially overlapping) _equations_, and the compiler will reduce an | |||
| application using an equation as soon as it's sure that equation is the only possible equation based | |||
| on the currently-known arguments. | |||
| Using the type function `(+)`{.amulet} we can use our original implementation of `append` and have it | |||
| type-check: | |||
| ```amulet | |||
| let append (xs : vect 'n 'a) (ys : vect 'k 'a) : vect ('n + 'k) 'a = | |||
| match xs with | |||
| | Nil -> ys | |||
| | Cons (x, xs) -> Cons (x, append xs ys) | |||
| let ys = append (Cons (1, Nil)) (Cons (2, Cons (3, Nil))) | |||
| ``` | |||
| Now, a bit of a strange thing is that Amulet reduces type family applications as lazily as possible, | |||
| so that `ys` above has type `vect (S Z + S (S Z)) int`{.amulet}. In practice, this isn't an issue, as | |||
| a simple ascription shows that this type is equal to the more orthodox `vect (S (S (S Z))) | |||
| int`{.amulet}. | |||
| ```amulet | |||
| let zs : vect (S (S (S Z))) int = ys | |||
| ``` | |||
| Internally, type functions do pretty much the same thing as the functional dependency + evidence | |||
| approach we used internally. Each equation gives rise to an equality _axiom_, represented as a | |||
| constructor because our intermediate language pretty much lets constructors return whatever they damn | |||
| want. | |||
| ```amulet | |||
| type + '(n : nat) '(m : nat) = | |||
| | awp : forall 'n 'm 'r. 'n ~ Z -> 'm ~ 'n -> ('n + 'm) ~ 'n | |||
| | awq : forall 'n 'k 'm 'l. 'n ~ (S 'k) -> 'm ~ 'l | |||
| -> ('n + 'm) ~ (S ('k + 'l)) | |||
| ``` | |||
| These symbols have ugly autogenerated names because they're internal to the compiler and should never | |||
| appear to users, but you can see that `awp` and `awq` correspond to each clause of the `(+)`{.amulet} | |||
| type function, with a bit more freedom in renaming type variables. | |||
| ### Custom Type Errors: Typing Better | |||
| Sometimes - I mean, pretty often - you have better domain knowledge than Amulet. For instance, you | |||
| might know that it's impossible to `show` a function. The `type_error` type family lets you tell the | |||
| type checker this: | |||
| ```amulet | |||
| instance | |||
| (type_error (String "Can't show functional type:" :<>: ShowType ('a -> 'b)) | |||
| => show ('a -> 'b) | |||
| begin | |||
| let show _ = "" | |||
| end | |||
| ``` | |||
| Now trying to use `show` on a function value will give you a nice error message: | |||
| ```amulet | |||
| let _ = show (fun x -> x + 1) | |||
| ``` | |||
| ``` | |||
| │ | |||
| 1 │ let _ = show (fun x -> x + 1) | |||
| │ ^^^^^^^^^^^^^^^^^^^^^ | |||
| Can't show functional type: int -> int | |||
| ``` | |||
| ### Type Families can Overlap | |||
| Type families can tell when two types are equal or not: | |||
| ```amulet | |||
| type function equal 'a 'b begin | |||
| discrim 'a 'a = True | |||
| discrim 'a 'b = False | |||
| end | |||
| ``` | |||
| But overlapping equations need to agree: | |||
| ```amulet | |||
| type function overlap_not_ok 'a begin | |||
| overlap_not_ok int = string | |||
| overlap_not_ok int = int | |||
| end | |||
| ``` | |||
| ``` | |||
| Overlapping equations for overlap_not_ok int | |||
| • Note: first defined here, | |||
| │ | |||
| 2 │ overlap_not_ok int = string | |||
| │ ^^^^^^^^^^^^^^^^^^^^^^^^^^^ | |||
| but also defined here | |||
| │ | |||
| 3 │ overlap_not_ok int = int | |||
| │ ^^^^^^^^^^^^^^^^^^^^^^^^ | |||
| ``` | |||
| ### Conclusion | |||
| Type families and type classes with functional dependencies are both ways to introduce computation in | |||
| the type system. They both have their strengths and weaknesses: Fundeps allow improvement to inferred | |||
| types, but type families interact better with GADTs (since they generate more equalities). Both are | |||
| important in language with a focus on type safety, in my opinion. | |||
| [^1]: This is not actually the definition of a relation with full generality; Set theorists are | |||
| concerned with arbitrary families of sets indexed by some $i \in I$, where $I$ is a set of indices; | |||
| Here, we've set $I = \mathbb{N}$ and restrict ourselves to the case where relations are tuples. | |||
| [^2]: At least it's not category theory. | |||
| [^3]: In the shower today I actually realised that the `append` function on vectors is a witness to | |||
| the algebraic identity $a^n * a^m = a^{n + m}$. Think about it: the `vect 'n`{.amulet} functor is | |||
| representable by `fin 'n`{.amulet}, i.e. it is isomorphic to functions `fin 'n -> 'a`{.amulet}. By | |||
| definition, `fin 'n`{.amulet} is the type with `'n`{.amulet} elements, and arrow types `'a -> | |||
| 'b`{.amulet} have $\text{size}(b)^{\text{size}(a)}$ elements, which leads us to conclude `vect 'n | |||
| 'a` has size $\text{size}(a)^n$ elements. | |||
+ 126
- 0
pages/posts/2019-10-19-amulet-quicklook.md
View File
| @ -0,0 +1,126 @@ | |||
| --- | |||
| title: "A Quickie: A Use Case for Impredicative Polymorphism" | |||
| path: impredicative-polymorphism | |||
| date: October 19, 2019 | |||
| --- | |||
| Amulet now (as of the 18th of October) has support for impredicative | |||
| polymorphism based on [Quick Look impredicativity], an algorithm first | |||
| proposed for GHC that treats inference of applications as a two-step | |||
| process to enable inferring impredicative types. | |||
| As a refresher, impredicative types (in Amulet) are types in which a | |||
| `forall`{.amuçet} appears under a type constructor (that is not | |||
| `(->)`{.amulet} or `(*)`{.amulet}, since those have special variance in | |||
| the compiler). | |||
| Quick Look impredicativity works by doing type checking of applications | |||
| in two phases: the _quick look_, which is called so because it's faster | |||
| than regular type inference, and the regular type-checking of | |||
| arguments. | |||
| Given a `n`-ary application | |||
| <code>f x<sub>1</sub> ... x<sub>n</sub></code>: | |||
| <ol type="I"> | |||
| <li> | |||
| The _quick look_ proceeds by inferring the type of the function to | |||
| expose the first `n` quantifiers, based on the form of the arguments. | |||
| For a regular term argument `e`, we expect a `'t ->`{.amulet} quantifier; For | |||
| visible type arguments, we expect either `forall 'a.`{.amulet} or | |||
| `forall 'a ->`{.amulet}. | |||
| After we have each of the quantifiers, we quickly infer a type for each | |||
| of the _simple_ arguments in | |||
| <code>x<sub>1</sub> ... x<sub>n</sub></code>. | |||
| Here, simple means either a | |||
| variable, literal, application or an expression annotated with a type | |||
| `x : t`{.amulet}. With this type in hands, we unify it with the type | |||
| expected by the quantifier, to collect a partial substituion (in which | |||
| unification failures are ignored), used to discover impredicative | |||
| instantiation. | |||
| For example, say `f : 'a -> list 'a -> list 'a`{.amulet} (the cons | |||
| function)[^1], and we want to infer the application `f (fun x -> x) (Nil | |||
| @(forall 'xx. 'xx -> 'xx))`{.amulet}. Here, the quick look will inspect | |||
| each argument in turn, coming up with a `list 'a ~ list (forall 'xx. 'xx | |||
| -> 'xx)`{.amulet} equality by looking at the second argument. Since the | |||
| first argument is not simple, it tells us nothing. Thus, the second | |||
| phase starts with the substitution `'a := forall 'xx. 'xx -> | |||
| 'xx`{.amulet}. | |||
| </li> | |||
| <li> | |||
| The second phase is traditional type-checking of each argument in turn, | |||
| against its respective quantifier. Here we use Amulet's type-checking | |||
| function `check` instead of applying type-inference then constraining | |||
| with subsumption since that results in more precise resuls. | |||
| However, instead of taking the quantifiers directly from the function's | |||
| inferred type, we first apply the substitution generated by the | |||
| quick-look. Thus, keeping with the example, we check the function `(fun | |||
| x -> x)`{.amulet} against the type `forall 'xx. 'xx -> 'xx`{.amulet}, | |||
| instead of checking it against the type variable `'a`{.amulet}. | |||
| This is important because checking against a type variable degrades to | |||
| inference + subsumption, which we wanted to avoid in the first place! | |||
| Thus, if we had no quick look, the function `(fun x -> x)`{.amulet} | |||
| would be given monomorphic type `'t1 -> 't2`{.amulet} (where | |||
| `'t1'`{.amulet}, `'t2`{.amulet} are fresh unification variables), and | |||
| we'd try to unify `list ('t1 -> 't2) ~ list (forall 'xx. 'xx -> | |||
| 'xx)`{.amulet} - No dice! | |||
| </li> | |||
| </ol> | |||
| ### Why does this matter? | |||
| Most papers discussing impredicative polymorphism focus on the boring, | |||
| useless example of stuffing a list with identity functions. Indeed, this | |||
| is what I demonstrated above. | |||
| However, a much more useful example is putting _lenses_ in lists (or | |||
| `optional`{.amulet}, `either`{.amulet}, or what have you). Recall the | |||
| van Laarhoven encoding of lenses: | |||
| ```amulet | |||
| type lens 's 't 'a 'b <- forall 'f. functor 'f => ('a -> 'f 'b) -> 's -> 'f 't | |||
| ``` | |||
| If you're not a fan of that, consider also the profunctor encoding of | |||
| lenses: | |||
| ```amulet | |||
| type lens 's 't 'a 'b <- forall 'p. strong 'p => 'p 'a 'b -> 'p 's 't | |||
| ``` | |||
| These types are _both_ polymorphic, which means we can't normally have a | |||
| `list (lens _ _ _ _)`{.amulet}. This is an issue! The Haskell `lens` | |||
| library works around this by providing a `LensLike`{.haskell} type, | |||
| which is not polymorphic and takes the functor `f` by means of an | |||
| additional parameter. However, consider the difference in denotation | |||
| between | |||
| ```haskell | |||
| foo :: [Lens a a Int Int] -> a -> (Int, a) | |||
| bar :: Functor f => [LensLike f a a Int Int] -> a -> (Int, a) | |||
| ``` | |||
| The first function takes a list of lenses; It can then use these lenses | |||
| in any way it pleases. The second, however, takes a list of lens-like | |||
| values _that all use the same functor_. Thus, you can't `view` using the | |||
| head of the list and `over` using the second element! (Recall that | |||
| `view` uses the `Const`{.haskell} functor and `over`{.amulet} the | |||
| `Identity`{.amulet} functor). Indeed, the second function can't use the | |||
| lenses at all, since it must work for an arbitrary functor and not | |||
| `Const`{.haskell}/`Identity`{.haskell}. | |||
| Of course, [Amulet lets you put lenses in lists]: See `lens_list` and | |||
| `xs` at the bottom of the file. | |||
| [^1]: Assume that the `'a`{.amulet} variable is bound by a `forall | |||
| 'a.`{.amulet} quantifier. Since we don't use visible type application in | |||
| the following example, I just skipped mentioning it. | |||
| [Quick Look impredicativity]: https://github.com/serras/ghc-proposals/blob/quick-look/proposals/0000-quick-look-impredicativity.md | |||
| [Amulet lets you put lenses in lists]: /static/profunctor-impredicative.ml.html | |||
+ 1355
- 0
pages/posts/2020-01-31-lazy-eval.lhs
File diff suppressed because it is too large
View File
+ 380
- 0
pages/posts/2020-07-12-continuations.md
View File
| @ -0,0 +1,380 @@ | |||
| --- | |||
| title: The Semantics of Evaluation & Continuations | |||
| date: July 12th, 2020 | |||
| maths: true | |||
| --- | |||
| Continuations are a criminally underappreciated language feature. Very few languages (off the top of my head: most Scheme dialects, some Standard ML implementations, and Ruby) support the---already very expressive---undelimited continuations---the kind introduced by `call/cc`{.scheme}---and even fewer implement the more expressive delimited continuations. Continuations (and tail recursion) can, in a first-class, functional way, express _all_ local and non-local control features, and are an integral part of efficient implementations of algebraic effects systems, both as language features and (most importantly) as libraries. | |||
| <div style="display: flex"> | |||
| <div> | |||
| Continuations, however, are notoriously hard to understand. In an informal way, we can say that a continuation is a first-class representation of the "future" of a computation. By this I do not mean a future in the sense of an asynchronous computation, but in a temporal sense. While descriptions like this are "correct" in some sense, they're also not useful. What does it mean to store the "future" of a computation in a value? | |||
| Operationally, we can model continuations as just a segment of control stack. This model is perhaps better suited for comprehension by programmers familiar with the implementation details of imperative programming languages, which is decidedly not my target audience. Regardless, this is how continuations (especially the delimited kind) are generally presented. | |||
| With no offense to the authors of these articles, some of which I greatly respect as programming language designers and implementers, I do not think that this approach is very productive in a functional programming context. This reductionist, imperative view would almost be like explaining the _concept_ of a proper tail call by using a trampoline, rather than presenting trampolines as one particular implementation strategy for the tail-call-ly challenged. | |||
| </div> | |||
| <figure style="min-width:20%; padding-left: 12pt"> | |||
| <img class="tikzpicture" src="/diagrams/cc/delimcc.svg" /> | |||
| _Fig 1. A facsimile of a diagram you'd find attached to an explanation of delimited continuations. Newer frames on top._ | |||
| </figure> | |||
| </div> | |||
| In a more functional context, then, I'd like to present the concept of continuation as a _reification_ of an _evaluation context_. I stress that this presentation is not novel, though it is, perhaps, uncommon outside of the academic literature on continuations. Reification, here, is the normal English word. It's a posh way of saying "to make into a thing". For example, an `(eval)`{.scheme} procedure is a _reification_ of the language implementation---it's an interpreter made into a thing, a thing that looks, walks and quacks like a procedure. | |||
| The idea of evaluation contexts, however, seems to have remained stuck in the ivory towers that the mainstream so often accuse us of inhabiting. | |||
| Evaluation Contexts | |||
| ------------------- | |||
| What _is_ an evaluation context? Unhelpfully, the answer depends on the language we're talking about. Since the language family you're most likely to encounter continuations in is Scheme, we'll use a Scheme-_like_ language (not corresponding to any of the R<sup>K</sup>RS standards). Our language has the standard set of things you'd find in a minimalist functional language used for an academic text: lambda expressions, written `(lambda arg exp)`{.scheme} that close over variables in lexical scope; applications, also n-ary, written `(func arg )`{.scheme}, `if`{.scheme}-expressions written `(if condition then else)`{.scheme}, with the `else` expression being optional and defaulting to the false value `#f`{.scheme}, integers, integer operations, and, of course, variables. | |||
| As an abbreviation one can write `(lambda (a . args) body)` to mean `(lambda a (lambda args body))` (recursively), and similarily for applications (associating to the left), but the language itself only has unary application and currying. This is in deviation from actual Scheme implementations which have complex parameter passing schemes, including variadic arguments (collecting any overflow in a list), keyword and optional arguments, etc. While all of these features are important for day-to-day programming, they do nothing but cloud the presentation here with needless verbosity. | |||
| ```scheme | |||
| e ::= (lambda arg expr) ; function definitions | |||
| | (if expr expr expr) ; if expression | |||
| | (expr expr) ; function applications | |||
| | var ; variables | |||
| | #t | #f ; scheme programmers spell booleans funny | |||
| | 1 | 2 | 3 | 4 ... ; integers | |||
| ``` | |||
| The set of values in this miniScheme language inclues lambda expressions, the booleans `#t`{.scheme} and `#f`{.scheme}, and the integers; Every other expression can potentially take a step. Here, taking a step means applying a _reduction rule_ in the language's semantics, or finding a _congruence_ rule that allows some sub-expression to suffer a reduction rule. | |||
| An example of reduction rule is β-reduction, which happens when the function being applied is a λ-abstraction and all of its arguments have been reduced to values. The rule, which says that an application of a lambda to a value can be reduced to its body in one step, is generally written in the notation of sequent calculus as below. | |||
| <details> | |||
| <summary>Fancy reduction rule type-set in TeX</summary> | |||
| <noscript>Sorry, I use KaTeX for my mathematics. Read on!</noscript> | |||
| $$\frac{}{(\lambda x.e) v \longrightarrow e\{v/x\}}$$ | |||
| </details> | |||
| However, let's use the Lisp notation above and write reduction rules as if they were code. The notation I'm using here is meant to evoke [Redex], a tool for defining programming semantics implemented as a Racket language. Redex is really neat and I highly recommend it for anyone interested in studying programming language semantics formally. | |||
| [Redex]: https://docs.racket-lang.org/redex/ | |||
| <!-- reduction rules --> | |||
| <div style="display: flex; flex-direction: column; justify-content: space-around"> | |||
| <h4 style="text-align: center">Reduction rules</h4> | |||
| <div class="mathpar"> | |||
| <div> | |||
| ```scheme | |||
| (--> ((lambda x e) v) | |||
| (subst x v e)) | |||
| ``` | |||
| </div> | |||
| <div> | |||
| ```scheme | |||
| (--> (if #t e_1 e_2) | |||
| (e_1)) | |||
| ``` | |||
| </div> | |||
| <div> | |||
| ```scheme | |||
| (--> (if #f e_1 e_2) | |||
| (e_2)) | |||
| ``` | |||
| </div> | |||
| </div> | |||
| </div> | |||
| These rules, standard though they may be, have a serious problem. Which, you might ask? They only apply when the expressions of interest are already fully evaluated. No rule matches for when the condition of an `if`{.scheme} expression is a function application, or another conditional; The application rule, also, only applies when the argument has already been evaluated (it's _call-by-value_, or _strict_). What can we do? Well, a simple and obvious solution is to specify _congruence_ rules that let us reduce in places of interest. | |||
| <!-- congruence rules --> | |||
| <div style="display: flex; flex-direction: column; justify-content: space-around"> | |||
| <h4 style="text-align: center">Congruence rules</h4> | |||
| <div class="mathpar"> | |||
| <div> | |||
| ```scheme | |||
| [ (--> e_1 v) | |||
| -------------------------- | |||
| (--> (e_1 e_2) (v e_2))] | |||
| ``` | |||
| Evaluating in function position | |||
| </div> | |||
| <div> | |||
| ```scheme | |||
| [ (--> e_2 v) | |||
| -------------------------- | |||
| (--> (e_1 e_2) (e_1 v))] | |||
| ``` | |||
| Evaluating in argument position | |||
| </div> | |||
| <div> | |||
| ```scheme | |||
| [ (--> e_1 v) | |||
| ----------------------- | |||
| (--> (if e_1 e_2 e_3) | |||
| (if v e_2 e_3))] | |||
| ``` | |||
| Evaluating in scrutinee position | |||
| </div> | |||
| </div> | |||
| </div> | |||
| Hopefully the problem should be clear. If it isn't, consider adding binary operators for the field operations: Each of the 4 (addition, subtraction, multiplication, division) needs 2 congruence rules, one for reducing either argument, even though they each have a single reduction rule. In general, an N-ary operator will have N congruence rules, one for each of its N operands, but only one reduction rule! | |||
| The solution to this problem comes in the form of _evaluation contexts_. We can define a grammar of "expressions with holes", generally written as <noscript>E[·]</noscript><span class='script'>$\operatorname{E}[\cdot]$</span>, where the <noscript>·</noscript><span class='script'>$\cdot$</span> stands for an arbitrary expression. In code, we'll denote the hole with `<>`, perhaps in evocation of the macros `cut` and `cute` from SRFI 26[^1]. | |||
| Our grammar of evaluation contexts, which we'll call `E` in accordance with tradition, looks like this: | |||
| ```scheme | |||
| E ::= <> ; any expression can be evaluated | |||
| | (E e) ; evaluate the function | |||
| | (v E) ; evaluate the argument | |||
| | (if E e e) ; evaluate the condition | |||
| ``` | |||
| Now we can write all our congruence rules by appealing to a much simpler, and most importantly, singular, _context rule_, that says reduction is legal anywhere in an evaluation context. | |||
| <div style="text-align: center;"> | |||
| <div style="display: inline-block; text-align: left;"> | |||
| ```scheme | |||
| [(--> e v) | |||
| ---------------------------------- | |||
| (--> (in-hole E e) (in-hole E v)] | |||
| ``` | |||
| </div> | |||
| _Redex uses the notation `(in-hole E e)` to mean an evaluation context `E` with `e` "plugging" the hole `<>`._ | |||
| </div> | |||
| What do evaluation contexts actually have to do with programming language implementation, however? Well, if you squint a bit, and maybe introduce some parameters, evaluation contexts look a lot like what you'd find attached to an operation in... | |||
| Continuation-passing Style | |||
| -------------------------- | |||
| I'm not good at structuring blog posts, please bear with me. | |||
| Continuation-passing style, also known as <span title="Child protective service- sike!" style="text-decoration: underline dotted">CPS</span>, is a popular intermediate representation for functional language compilers. The goal of CPS is to make evaluation order explicit, and to implement complex control operations like loops, early returns, exceptions, coroutines and more in terms of only lambda abstraction. To achieve this, the language is stratified into two kinds of expressions, "complex" and "atomic". | |||
| Atomic expressions, or atoms, are not radioactive or explosive: In fact, they're quite the opposite! The Atoms of CPS are the values of our direct-style language. Forms like `#t`{.scheme}, `#f`{.scheme}, numbers and lambda expressions will not undergo any more evaluation, and thus may appear anywhere. Complex expressions are those that _do_ cause evaluation, such as conditionals and procedure application. | |||
| To make sure that evaluation order is explicit, every complex expression has a _continuation_ attached, which here boils down to a function which receives the return value of the expression. Procedures, instead of returning to a caller, will instead tail-call their continuation. | |||
| The grammar of our mini Scheme after it has gone CPS transformation is as follows: | |||
| <div style="text-align: center;"> | |||
| <div style="display: inline-block; text-align: left;"> | |||
| ```scheme | |||
| atom ::= (lambda (arg kont) expr) ; continuation argument | |||
| | var ; these remain as they were. | |||
| | #t | #f | |||
| | 1 | 2 | 3 | 4 | |||
| expr ::= (atom atom atom) ; function, argument, continuation | |||
| | (if atom expr expr) ; conditional, then_c, else_c | |||
| | atom ; atoms are also valid expressions | |||
| ``` | |||
| </div> | |||
| </div> | |||
| Note that function application now has _three_ components, but all of them are atoms. Valid expressions include things like `(f x halt)`, which means "apply `f` to `x` such that it returns to `halt`", but do _not_ include `(f (g x y) (h y z))`, which have an ambiguous reduction order. Instead, we must write a λ-abstraction to give a name to the result of each intermediate computation. | |||
| For example, the (surface) language application `(e_1 e_2)`, where both are complex expressions, has to be rewritten as either of the following expressions, which correspond respectively to evaluating the function first or the argument first. `(e_1 (lambda r1 (e_2 (lambda r2 (r1 r2))))`{.scheme} | |||
| <div class="mathpar"> | |||
| <div> | |||
| ```scheme | |||
| (e_1 (lambda r_1 | |||
| (e_2 (lambda r_2 | |||
| (r_1 r_2 k))))) | |||
| ``` | |||
| Evaluating the function first | |||
| </div> | |||
| <div> | |||
| ```scheme | |||
| (e_1 (lambda r_1 | |||
| (e_2 (lambda r_2 | |||
| (r_1 r_2 k))))) | |||
| ``` | |||
| Evaluating the argument first | |||
| </div> | |||
| </div> | |||
| If you have, at any point while reading the previous 2 or so paragraphs, squinted, then you already know where I'm going with this. If not, do it now. | |||
| The continuation of an expression corresponds to its evaluation context. The `v`s in our discussion of semantics are the `atom`s of CPS, and most importantly, contexts `E` get closed over with a lambda expression `(lambda x E[x])`{.scheme}, replacing the hole `<>` with a bound variable `x`. Evaluating an expression `(f x)`{.scheme} in a context `E`, say `(<> v)` corresponds to `(f x (lambda x (x v)))`{.scheme}. | |||
| If a language implementation uses the same representation for both user procedures and lambda expressions---which is **very** inefficient, let me stress---then we get first-class _control_ for "free". First-class in the sense that control operations, like `return`, can be stored in variables, or lists, passed as arguments to procedures, etc. The fundamental first-class control operator for undelimited continuations is called `call-with-current-continuation`{.scheme}, generally abbreviated to `call/cc`{.scheme}. | |||
| <div style="text-align: center;"> | |||
| <div style="display: inline-block; text-align: left;"> | |||
| ```scheme | |||
| (define call/cc (lambda (f cc) (f cc cc))) | |||
| ``` | |||
| </div> | |||
| </div> | |||
| Using `call/cc`{.scheme} and a mutable cell holding a list we can implement cooperative threading. The `(yield)` operator has the effect of capturing the current continuation and adding it to (the end) of the list, dequeueing a potentially _different_ saved continuation from the list and jumping there instead. | |||
| <div style="text-align: center;"> | |||
| <div style="display: inline-block; text-align: left;"> | |||
| ```scheme | |||
| (define threads '()) | |||
| ; Jump to the next thread (read: continuation) or exit the program | |||
| ; if there are no more threads to schedule | |||
| (define exit | |||
| (let ((exit exit)) | |||
| (lambda () | |||
| (if (null? threads) ; are we out of threads to switch to? | |||
| (exit) ; if so, exit the program | |||
| (let ((thr (car threads))) ; select the first thread | |||
| (set! threads (cdr threads)) ; dequeue it | |||
| (thr)))))))) ; jump there | |||
| ; Add a function to the list of threads. After finishing its work, | |||
| ; the function needs to (exit) so another thread can take over. | |||
| (define (fork f) | |||
| (set! threads (append threads | |||
| (list (lambda () (f) (exit)))))) | |||
| ; Capture the current continuation, enqueue it, and switch to | |||
| ; a different thread of execution. | |||
| (define (yield) | |||
| (call/cc (lambda (cc) | |||
| (set! threads (append threads (list cc))) | |||
| (exit)))) | |||
| ``` | |||
| </div> | |||
| </div> | |||
| That's a cooperative threading implementation in 25 lines of Scheme! If whichever implementation you are using has a performant `call/cc`{.scheme}, this will correspond ropughly to the normal stack switching that a cooperative threading implementation has to do. | |||
| That last paragraph is a bit of a weasel, though. What's a "performant call/cc" look like? Well, `call/cc`{.scheme} continuations have _abortive_ behaviour[^2], which means they have the effect of _replacing_ the current thread of control when invoked, instead of prepending a segment of stack---which is known as "functional continuations". That is, it's basically a spiffed up `longjmp`{.c}, which in addition to saving the state of the registers, copies the call stack along with it. | |||
| However, `call/cc`{.scheme} is a bit overkill for applications such as threads, and even then, it's not the most powerful control abstraction. For one `call/cc`{.scheme} _always_ copies the entire continuation, with no way to *ahem* delimit it. Because of this, abstractions built on `call-with-current-continuation`{.scheme} [do not compose]. | |||
| [do not compose]: http://okmij.org/ftp/continuations/against-callcc.html | |||
| We can fix all of these problems, ironically enough, by adding _more_ power. We instead introduce a _pair_ operators, `prompt` and `control`, which... | |||
| Delimit your Continuations | |||
| -------------------------- | |||
| This shtick again? | |||
| Delimited continuations are one of those rare ideas that happen once in a lifetime and revolutionise a field---maybe I'm exaggerating a bit. They, unfortunately, have not seen very widespread adoption. But they do have all the characteristics of one of those revolutionary ideas: they're simple to explain, simple to implement, and very powerful. | |||
| The idea is obvious from the name, so much that it feels insulting to repeat it: instead of capturing the continuation, have a marker that _delimits_ what's going to be captured. What does this look like in our reduction semantics? | |||
| The syntax of evaluation contexts does not change, only the operations. We gain operations `(prompt e)`{.scheme} and `(control k e)`{.scheme}, with the idea being that when `(control k e)` is invoked inside of a `(prompt)` form, the evaluation context from the `control` to the nearest outermost `prompt` is reified as a function and bound to `k`. | |||
| <div class="mathpar"> | |||
| <div> | |||
| ```scheme | |||
| [------------------- | |||
| (--> (prompt v) v)] | |||
| ``` | |||
| Delimiting a value does nothing | |||
| </div> | |||
| <div> | |||
| ```scheme | |||
| [---------------------------------------------------------- | |||
| (--> (prompt (in-hole E (control k body))) | |||
| (prompt ((lambda k body) (lambda x (in-hole E x)))))] | |||
| ``` | |||
| Capture the continuation, bind it to the variable `k`, and keep going. | |||
| </div> | |||
| </div> | |||
| By not adding `(prompt E)` to the grammar of evaluation contexts, we ensure that `E` is devoid of any prompts by construction. This captures the intended semantics of "innermost enclosing prompt"---if `E` were modified to include prompts, the second rule would instead capture to the _outermost_ enclosing prompt, and we're back to undelimited call/cc. | |||
| Note that `prompt` and `control` are not the only pair of delimited control operators! There's also `shift` and `reset` (and `prompt0`/`control0`). `reset` is basically the same thing as `prompt`, but `shift` is different from `control` in that the captured continuation has the prompt—uh, the delimiter—reinstated, so that it cannot "escape". | |||
| <div style="text-align: center;"> | |||
| <div style="display: inline-block; text-align: left;"> | |||
| ```scheme | |||
| [----------------------------------------------------------------- | |||
| (--> (reset (in-hole E (shift k body))) | |||
| (reset ((lambda k body) (lambda x (reset (in-hole E x))))))] | |||
| ``` | |||
| Reinstate the prompt when the captured continuation is applied. | |||
| </div> | |||
| </div> | |||
| Yet another pair, which I personally prefer, is what you'd find in Guile's `(ice-9 control)`, namely `(call-with-prompt tag thunk handler)` and `(abort-to-prompt tag value)`. These are significantly more complex than bare `shift` and `reset` since they implement _multi-prompt_ delimited continuations. They're more like exception handlers than anything, with the addded power that your "exception handler" could restart the code after you `throw`{.java}. | |||
| <div style="text-align: center;"> | |||
| <div style="display: inline-block; text-align: left;"> | |||
| ```scheme | |||
| (define-syntax reset | |||
| (syntax-rules () | |||
| ((reset . body) | |||
| (call-with-prompt (default-prompt-tag) | |||
| (lambda () . body) | |||
| (lambda (cont f) (f cont)))))) | |||
| (define-syntax shift | |||
| (syntax-rules () | |||
| ((shift k . body) | |||
| (abort-to-prompt (default-prompt-tag) | |||
| (lambda (cont) | |||
| ((lambda (var) (reset . body)) | |||
| (lambda vals (reset (apply cont vals)))))) | |||
| ``` | |||
| `call-with-prompt` and `abort-to-prompt` subsume `shift` and `reset`. | |||
| Taken from [the Guile Scheme implementation](https://fossies.org/linux/guile/module/ice-9/control.scm). | |||
| </div> | |||
| </div> | |||
| The operators `call-with-prompt` and `abort-to-prompt` are very convenient for the implementation of many control structures, like generators: | |||
| ```scheme | |||
| (define-syntax for/generator | |||
| (syntax-rules () | |||
| ((_ name gen . body) | |||
| (begin | |||
| (define (work cont) | |||
| (call-with-prompt | |||
| 'generator-tag | |||
| cont | |||
| (lambda (cont name) (begin . body) | |||
| (work cont)))) | |||
| (work gen))))) | |||
| (define (yield x) (abort-to-prompt 'generator-tag x)) | |||
| (for/generator x (lambda () | |||
| (yield 1) | |||
| (yield 2) | |||
| (yield 3)) | |||
| (display x) (display #\newline)) | |||
| ``` | |||
| Exception handlers and threading in terms of `shift` and `reset` are left as an exercise to the reader. | |||
| But... why? | |||
| ----------- | |||
| Control abstractions appeal to our---or at least mine---sense of beauty. Being able to implement control flow operations as part of the language is often touted as one of the superpowers that Haskell gets from its laziness and purity, and while that certainly is true, control operators let us model many, _many_ more control flow abstractions, namely those involving non-local exits and entries. | |||
| Of course, all of these can be implemented in the language directly—JavaScript, for example, has `async`/`await`, stackless generators, _and_ exceptions. However, this is not an advantage. These significantly complicate the implementation of the language (as opposed to having a single pair of operators that's not much more complicated to implement than regular exception handlers) while also significantly _diminishing_ its expressive power! For example, using our definition of generators above, the Scheme code on the right does what you expect, but the JavaScript code on the left only yields `20`. | |||
| <div class="mathpar"> | |||
| <div> | |||
| ```scheme | |||
| ((lambda () | |||
| ((lambda () | |||
| (yield 10))) | |||
| (yield 20))) | |||
| ``` | |||
| </div> | |||
| <div> | |||
| ```javascript | |||
| (function*() { | |||
| (function*() { | |||
| yield 10; | |||
| }) | |||
| yield 20; | |||
| })(); | |||
| ``` | |||
| </div> | |||
| </div> | |||
| Delimited continuations can also be used to power the implementation of algebraic effects systems, such as those present in the language Koka, which much lower overhead (both in terms of code size and speed) than the type-driven local CPS transformation that Koka presently uses. | |||
| Language implementations which provide delimited control operators can also be extended with effect system support post-hoc, in a library, with an example being the [Eff] library for Haskell and the associated [GHC proposal] to add delimited control operators (`prompt` and `control`). | |||
| [Eff]: https://github.com/hasura/eff | |||
| [GHC proposal]: https://github.com/ghc-proposals/ghc-proposals/pull/313/ | |||
| [^1]: In reality it's because I'm lazy and type setting so that it works properly both with KaTeX and with scripting disabled takes far too many keystrokes. Typing some code is easier. | |||
| [^2]: People have pointed out to me that "abortive continuation" is a bit oxymoronic, but I guess it's been brought to you by the same folks who brought you "clopen set". | |||
+ 162
- 0
pages/posts/2020-09-09-typing-proof.md
View File
| @ -0,0 +1,162 @@ | |||
| --- | |||
| title: "This Sentence is False, or: On Natural Language, Typing and Proof" | |||
| date: September 9th, 2020 | |||
| --- | |||
| The Liar's paradox is often the first paradox someone dealing with logic, even in an informal setting, encounters. It is _intuitively_ paradoxical: how can a sentence be both true, and false? This contradicts (ahem) the law of non-contradiction, that states that "no proposition is both true and false", or, symbolically, $\neg (A \land \neg A)$. Appealing to symbols like that gives us warm fuzzy feelings, because, _of course, the algebra doesn't lie!_ | |||
| There's a problem with that the appeal to symbols, though. And it's nothing to do with non-contradiction: It's to do with well-formedness. How do you accurately translate the "this sentence is false" sentence into a logical formula? We can try by giving it a name, say $L$ (for liar), and state that $L$ must represent some logical formula. Note that the equality symbol $=$ here is _not_ a member of the logic we're using to express $L$, it's a symbol of this discourse. It's _meta_logical. | |||
| $$ L = \dots $$ | |||
| But what should fill in the dots? $L$ is the sentence we're symbolising, so "this sentence" must mean $L$. Saying "X is false" can be notated in a couple of equivalent ways, such as $\neg X$ or $X \to \bot$. We'll go with the latter: it's a surprise tool that will help us later. Now we know how to fill in the dots: It's $L \to \bot$. | |||
| <details> | |||
| <summary>Truth tables demonstrating the equivalence between $\neg A$ and $A \to \bot$, if you are classically inclined.</summary> | |||
| <div class="mathpar"> | |||
| <table> | |||
| <tr> | |||
| <th> $A$ </th> | |||
| <th> $\neg A$ </th> | |||
| </tr> | |||
| <tr><td>$\top$</td><td>$\bot$</td></tr> | |||
| <tr><td>$\bot$</td><td>$\top$</td></tr> | |||
| </table> | |||
| <table> | |||
| <tr> | |||
| <th> $A$ </th> | |||
| <th> $A\to\bot$ </th> | |||
| </tr> | |||
| <tr><td>$\top$</td><td>$\bot$</td></tr> | |||
| <tr><td>$\bot$</td><td>$\top$</td></tr> | |||
| </table> | |||
| </div> | |||
| </details> | |||
| But wait. If $L = L \to \bot$, then $L = (L \to \bot) \to \bot$, and also $L = ((L \to \bot) \to \bot) \to \bot$, and so... forever. There is no finite, well-formed formula of first-order logic that represents the sentence "This sentence is false", thus, assigning a truth value to it is meaningless: Saying "This sentence is false" is true is just as valid as saying that it's false, both of those are as valid as saying "$\neg$ is true". | |||
| Wait some more, though: we're not done. It's known, by the [Curry-Howard isomorphism], that logical systems correspond to type systems. Therefore, if we can find a type-system that assigns a meaning to our sentence $L$, then there _must_ exist a logical system that can express $L$, and so, we can decide its truth! | |||
| Even better, we don't need to analyse the truth of $L$ logically, we can do it type-theoretically: if we can build an inhabitant of $L$, then it is true; If we can build an inhabitant of $\neg L$, then it's false; And otherwise, I'm just not smart enough to do it. | |||
| So what is the smallest type system that lets us assign a meaning to $L$? | |||
| # A system of equirecursive types: $\lambda_{\text{oh no}}$[^1] | |||
| [^1]: The reason for the name will become obvious soon enough. | |||
| We do not need a complex type system to express $L$: a simple extension over the basic simply-typed lambda calculus $\lambda_{\to}$ will suffice. No fancy higher-ranked or dependent types here, sorry! | |||
| As a refresher, the simply-typed lambda calculus has _only_: | |||
| * A set of base types $\mathbb{B}$, | |||
| * Function types $\tau \to \sigma$, | |||
| * For each base type $b \in \mathbb{B}$, a set of base terms $\mathbb{T}_b$, | |||
| * Variables $v$, | |||
| * Lambda abstractions $\lambda v. e$, and | |||
| * Application $e\ e'$. | |||
| <details> | |||
| <summary>Type assignment rules for the basic $\lambda_{\to}$ calculus.</summary> | |||
| <div class="math-paragraph"> | |||
| <div> | |||
| $$\frac{x : \tau \in \Gamma}{\Gamma \vdash x : \tau}$$ | |||
| </div> | |||
| <div> | |||
| $$\frac{b \in \mathbb{B} \quad x \in \mathbb{T}_{b}}{\Gamma \vdash x : b}$$ | |||
| </div> | |||
| <div> | |||
| $$\frac{\Gamma, x : \sigma \vdash e : \tau}{\Gamma \vdash \lambda x. e : \sigma \to \tau}$$ | |||
| </div> | |||
| <div> | |||
| $$\frac{\Gamma, e : \sigma \to \tau \quad \Gamma \vdash e' : \sigma}{\Gamma \vdash e\ e' : \tau}$$ | |||
| </div> | |||
| </div> | |||
| </details> | |||
| First of all, we'll need a type to represent the logical proposition $\bot$. This type is empty: It has no type formers. Its elimination rule corresponds to the principle of explosion, and we write it $\mathtt{absurd}$. The inference rule: | |||
| <div class="math-paragraph"> | |||
| $$\frac{\Gamma \vdash e : \bot}{\mathtt{absurd}\ e : A}$$ | |||
| </div> | |||
| We're almost there. What we need now is a type former that serves as a solution for equations of the form $v = ... v ...$. That's right: we're just _inventing_ a solution to this class of equations---maths! | |||
| These are the _equirecursive_ types, $\mu a. \tau$. The important part here is _equi_: these types are entirely indistinguishable from their unrollings. Formally, we extend the set of type formers with type variables $a$ and $\mu$-types $\mu a. \tau$, where $\mu a$ acts as a binder for $a$. | |||
| Since we invented $\mu$ types as a solution for equations of the form $a = \tau$, we have that $\mu a. \tau = \tau[\mu a.\tau/a]$, where $\tau[\sigma{}/a]$ means "substitute $\sigma{}$ everywhere $a$ occurs in $\tau$". The typing rules express this identity, saying that anywhere a term might have one as a type, the other works too: | |||
| <div class="math-paragraph"> | |||
| <div> | |||
| $$\frac{\Gamma \vdash e : \tau[\mu a.\tau / a]}{\Gamma \vdash e : \mu a. \tau}$$ | |||
| </div> | |||
| <div> | |||
| $$\frac{\Gamma \vdash e : \mu a.\tau}{\Gamma \vdash e : \tau[\mu a. \tau / a]}$$ | |||
| </div> | |||
| </div> | |||
| Adding these rules, along with the one for eliminating $\bot$, to the $\lambda_{\to}$ calculus nets us the system $\lambda_{\text{oh no}}$. With it, one can finally formulate a representation for our $L$-sentence: it's $\mu a. a \to \bot$. | |||
| There exists a closed term of this type, namely $\lambda k. k\ k$, which means: The "this sentence is false"-sentence is true. We can check this fact ourselves, or, more likely, use a type checker that supports equirecursive types. For example, OCaml with the `-rectypes` compiler option does. | |||
| We'll first define the empty type `void` and the type corresponding to $L$: | |||
| <div class="math-paragraph"> | |||
| ~~~~{.ocaml} | |||
| type void ;; | |||
| type l = ('a -> void) as 'a ;; | |||
| ~~~~ | |||
| </div> | |||
| Now we can define our proof of $L$, called `yesl`, and check that it has the expected type: | |||
| <div class="math-paragraph"> | |||
| ~~~~{.ocaml} | |||
| let yesl: l = fun k -> k k ;; | |||
| ~~~~ | |||
| </div> | |||
| However. This same function is also a proof that... $\neg L$. Check it out: | |||
| <div class="math-paragraph"> | |||
| ~~~~{.ocaml} | |||
| let notl (x : l) : void = x x ;; | |||
| ~~~~ | |||
| </div> | |||
| # I am Bertrand Russell | |||
| Bertrand Russell (anecdotally) once proved, starting from $1 = 0$, that he was the Pope. I am also the Pope, as it turns out, since I have on hand a proof that $L$ and $\neg L$, in violation of non-contradiction; By transitivity, I am Bertrand Russell. <span style="float: right; display: inline-block;"> $\blacksquare$ </span> | |||
| Alright, maybe I'm not Russell (drat). But I am, however, a trickster. I tricked you! You thought that this post was going to be about a self-referential sentence, but it was actually about typed programming language design (not very shocking, I know). It's a demonstration of how recursive types (in any form) are logically inconsistent, and of how equirecursive types _are wrong_. | |||
| The logical inconsistency, we all deal with, on a daily basis. It comes with Turing completeness, and it annoys me to no end every single time I accidentally do `let x = ... x ...`{.haskell}. I _really_ wish I had a practical, total functional programming language to use for my day-to-day programming, and this non-termination _everywhere_ is a great big blotch on Haskell's claim of purity. | |||
| The kind of recursive types you get in Haskell is _fine_. They're not _great_ if you like the propositions-as-types interpretation, since it's trivial to derive a contradiction from them, but they're good enough for programming that implementing a positivity checker to ensure your definitions are strictly inductive isn't generally worth the effort. | |||
| Unless your language claims to have "zero runtime errors", in which case, if you implement isorecursive types instead of inductive types, you are _wrong_. See: Elm. God damn it. | |||
| <details> | |||
| <summary>So much for "no runtime errors"... I guess spinning forever on the client side is acceptable.</summary> | |||
| <div class="flex-list"> | |||
| ```elm | |||
| -- Elm | |||
| type Void = Void Void | |||
| type Omega = Omega (Omega -> Void) | |||
| yesl : Omega | |||
| yesl = Omega (\(Omega x) -> x (Omega x)) | |||
| notl : Omega -> Void | |||
| notl (Omega x) = x (Omega x) | |||
| ``` | |||
| </div> | |||
| </details> | |||
| Equirecursive types, however, are a totally different beast. They are _basically_ useless. Sure, you might not have to write a couple of constructors, here and there... at the cost of _dramatically_ increasing the set of incorrect programs that your type system accepts. Suddenly, typos will compile fine, and your program will just explode at runtime (more likely: fail to terminate). Isn't this what type systems are meant to prevent? | |||
| Thankfully, very few languages implement equirecursive types. OCaml is the only one I know of, and it's gated behind a compiler flag. However, that's a footgun that should _not_ be there. | |||
| [Curry-Howard isomorphism]: https://en.wikipedia.org/wiki/Curry%E2%80%93Howard_correspondence | |||
+ 264
- 0
pages/posts/2020-10-30-reflecting-equality.md
View File
| @ -0,0 +1,264 @@ | |||
| --- | |||
| title: Reflections on Equality | |||
| date: November 1st, 2020 | |||
| --- | |||
| When shopping for a dependent type theory, many factors should be taken into consideration: how inductive data is represented (inductive schemas vs W-types), how inductive data _computes_ (eliminators vs case trees), how types of types are represented (universes à la Tarski vs à la Russell). However, the most important is their treatment of equality. | |||
| Conor McBride, a prominent figure in type theory research, noted in [a reddit comment] that you should never trust a type theorist who has not changed their mind about equality (I'm paraphrasing). Recently, I've embarked on a journey to improve my credibility (or, at least, get out of the "instantly discarded opinion" pool): I've changed my mind about equality. | |||
| # What's the fuss about? | |||
| Equality is very prevalent when using dependently typed languages, whether as frameworks for writing mathematical proofs or for writing verified computer programs. Most properties of mathematical operators are expressed as equalities which they should respect. For example, a semigroup is a set $S$ with an _associative_ $\times$ operator. The property of associativity just means the operator respects the equality $a \times (b \times c) \equiv (a \times b) \times c$! | |||
| However, the equality relation which can be expressed with proofs is not the only equality which a dependently-typed system needs to consider. There's also the _judgemental_ equality, that is, which terms are always identified independently of their semantics. For example, $a + b$ and $b + a$ are _propositionally_ equal, which can be shown by writing an inductive proof of this fact, but they're _judgmentally_ different, because they have different term structure. | |||
| There are two 'main' traditions of Martin-Löf dependent type theory: the intensional type theories are as in the paragraph above, but the extensional type theories make me a liar. Extensional type theory is obtained by adding a rule of _equality reflection_, which collapses the distinction between propositional and judgemental equality: whenever there exists a proof of an equality between terms $x$ and $y$, they're considered judgmentally equal. | |||
| Adding equality reflection makes a type system more expressive with respect to equality: for example, in extensional type theories, one can derive the rule of _function extensionality_, which says two functions are equal when they are equal pointwise. However, equality reflection also makes a type system _less_ expressive with respect to equality: there is only one way for two things to be equal! | |||
| Moreover, equality reflection complicates _type checking_ to an unacceptable degree. Rather than being able to check the validity of a proof by comparing a term against a known type, an entire typing derivation is necessary as input to the type checker. To see why, consider the following derivation: | |||
| <figure> | |||
| <div> | |||
| $$ | |||
| \cfrac{ | |||
| \cfrac{ | |||
| \cfrac{}{\mathop{\mathop{\vdash}} (+) \mathop{:} \mathbb{N} \to \mathbb{N} \to \mathbb{N}} | |||
| \quad | |||
| \cfrac{ | |||
| \text{no} \mathop{:} \bot\ \mathop{\mathop{\vdash}} \mathtt{"foo"} \mathop{:} \text{Str} | |||
| \quad | |||
| \cfrac{ | |||
| \cfrac{ | |||
| \text{no} \mathop{:} \bot\ \mathop{\mathop{\vdash}} \text{no} \mathop{:} \bot | |||
| }{ | |||
| \text{no} \mathop{:} \bot\ \mathop{\mathop{\vdash}} \mathrm{absurd}(\text{no}) \mathop{:} \text{Str} \equiv \mathbb{N} | |||
| } | |||
| }{ \text{no} \mathop{:} \bot\ \mathop{\mathop{\vdash}} \text{Str} = \mathbb{N} } | |||
| }{ \text{no} \mathop{:} \bot\ \mathop{\mathop{\vdash}} \mathtt{"foo"} \mathop{:} \mathbb{N} } | |||
| \quad | |||
| \cfrac{}{\mathop{\mathop{\vdash}} 2 \mathop{:} \mathbb{N}} | |||
| }{ \text{no} \mathop{:} \bot \mathop{\mathop{\vdash}} (2 + \mathtt{"foo"}) \mathop{:} \mathbb{N} } | |||
| }{ \mathop{\mathop{\vdash}} \lambda \text{no} \to (2 + \mathtt{"foo"}) : \bot \to \mathbb{N} } | |||
| $$ | |||
| </div> | |||
| <figcaption>If the context contains an element of the empty type, every term needs to be accepted</figcaption> | |||
| </figure> | |||
| Here, the context contains an element of the empty type, written $\bot$. It's _comparatively_ easy for the type checker to see that in this case, the context we're working under is absurd, and any equality should be accepted. However, there are many such empty types: $\mathrm{Fin}(0)$, for example. Consider the type family $\mathrm{SAT}$, indexed by a Boolean clause, such that $\mathrm{SAT}(c)$ reduces to $\top$ when $c$ is satisfiable and $\bot$ otherwise. How would you type-check the program $\lambda x \to 2 + \mathtt{"foo"}$ at type $\mathrm{SAT}(c) \to \mathbb{N}$, where $c$ is some adversarially-chosen, arbitrarily complex expression? How would you type check it at type $\mathrm{Halts}(m) \to \mathbb{N}$? | |||
| In contrast, Intensional Type Theory, or ITT for short, treats equality as if it were any other type. In ITT, equality is inductively generated by the constructor $\mathrm{refl}_x$ for any element $x$ of a type $A$, which leads to an induction principle saying that, if | |||
| - $A$ is a type, and | |||
| - $C$ is a proposition indexed by $x, y : A$ and $p : x \equiv_{A} y$, and | |||
| - $p_{\mathrm{refl}}$ is a proof of $C(x, x, \mathrm{refl_{x}})$, then | |||
| we can deduce, for all $x, y : A$ and $p : x \equiv_{A} y$, that $C(x, y, p)$ holds. | |||
| Given this operator, generally called axiom J (since "J" is the letter after **I**dentity, another word for "equality"), we can derive many of the properties of equality: transitivity (given $x \equiv y$ and $y \equiv z$, get $x \equiv z$) and symmetry (given $x \equiv y$, get $y \equiv x$) make $\equiv$ an _equivalence relation_, and substitutivity (assuming $P(x)$ and $x \equiv y$, get $P(y)$) justifies calling it "equality". | |||
| However, axiom J is both weaker _and_ stronger than equality reflection: for one, it doesn't let us prove that functions are equal when they are pointwise equal, which leads to several complications. However, it also doesn't let us prove that all equalities are equal to $\mathrm{refl}$, which lets us strengthen equality by postulating, for example, | |||
| ## The univalence axiom of Voevodsky | |||
| The "tagline" for the univalence axiom, which lies at the center of Homotopy Type Theory (HoTT), is that "equality is equivalent to equivalence". More specifically, given a function $f : A \to B$, together with a proof that $f$ has left and right inverses, univalence gives us an equality $\mathrm{ua}(f)$ such that transporting "along" this path is the same as applying $f$. | |||
| For example, we could define the "usual" unary naturals $\mathbb{N}$ (which are easy to use for proving but terrible computationally) and _binary_ naturals $\mathbb{N}_2$ (which have more efficient computational behaviour at the cost of more complicated structure), demonstrate an equivalence $\mathrm{peano2Binary} : \mathbb{N} \cong \mathbb{N}_2$, then *transport* proofs about $\mathbb{N}$ to proofs about $\mathbb{N}_2$! | |||
| A [recent paper] by Tabareau et al explores the consequences of strengthening a type theory with univalence together with _parametricity_, unlocking efficient and _automated_ (given the equivalence) transport between algebraic structures of types. | |||
| <details> | |||
| <summary> A note on terminology </summary> | |||
| The HoTT interpretation of "types as topological spaces" leads us to interpret the type of equalities as the type of _paths_ in a space. From this, we get some terminology: instead of saying "cast $x$ with the equality $e$", we can equivalently say "transport $x$ along the path $p$". | |||
| Using the "path" terminology in a context with unicity of equality proofs is a bit misleading, but the terminology does not break down (a set-truncated system is just one where all paths are loops). Because of this, I'll use "path" and "equality" interchangeably. Sorry if this causes any confusion. | |||
| </details> | |||
| The undecidability of type checking ETT and the comparative weakness of ITT has led _many_ researchers to consider the following question: | |||
| > Can we have: | |||
| > | |||
| > * Decidable type checking | |||
| > * A "more extensional" equality | |||
| > * Good computational behaviour | |||
| > | |||
| > All at the same time? | |||
| Turns out, the answer is yes! | |||
| # Observational Equality | |||
| One early positive answer is that of Observational Type Theory, presented in [a 2007 paper] by Altenkirch, McBride, and Swierstra. The basic idea is that, instead of defining the type $a \equiv_{A} b$ as an inductive family of types, we define it so that equality _computes_ on the structure of $A$, $a$ and $b$ to _reduce_ to tractable forms. Observational type theory (OTT, from now on) has two _universes_ (types whose elements are types), $\mathrm{Prop}$ and $\mathrm{Set}$, such that $\mathrm{Prop} : \mathrm{Set}$ and $\mathrm{Set} : \mathrm{Set}$[^1] | |||
| The elements of $\mathrm{Prop}$ are taken to be _propositions_, not in the sense of propositions-as-types, but in the sense of HoTT. Propositions are the types $T$ for which, given $x, y : T$, one has $x \equiv y$: they're types with at most one element. Some propositions are $\top$, the trivially true proposition, and $\bot$, the empty proposition. | |||
| Given $A : u$, and some $B : v$ with one variable $x : A$ free (where $u$ and $v$ are possibly distinct universes), we can form the type $\prod_{x : A} B$ of _dependent products_ from $A$ to $B$. If $v$ is in $\mathrm{Prop}$, then the dependent product also lives in $\mathrm{Prop}$. Otherwise, it lives in $\mathrm{Set}$. Moreover, we can also form the type $\sum_{x : A} B$ of _dependent sums_ of $A$ and $B$, which always lives in $\mathrm{Set}$. | |||
| Given a type $A$ and two elements $a, b : A$, we can form the _proposition_ $a \equiv_{A} b$. Note the emphasis on the word proposition here! Since equivalence is a proposition, we have uniqueness of equality proofs by definition: there's at most one way for things to be equal, conflicting with univalence. So we get _some_ extensionality, namely of functions, but not for arbitrary types. Given types <span class=together>$A$ and $B$,</span> a proof $p : A \equiv B$ and $x : A$, we have the term $\mathrm{coe}(A, B, P, x) : B$, which represents the *coe*rcion of $x$ along the path $p$. | |||
| Here is where my presentation of observational equality starts to differentiate from the paper's: McBride et al use _heterogeneous_ equality, i.e. a 4-place relation $(x : A) \equiv (y : B)$, where $A$ and $B$ are potentially distinct types. But! Their system only allows you to _use_ an equality when $A \equiv B$. The main motivation for heterogeneous equality is to "bunch up" as many equalities as possible to be eliminated all in one go, since coercion in their system does not compute. However, if coercion computes normally, then we don't need to do this "bunching": one can just use coercion normally. | |||
| The key idea of OTT is to identify as "equal" objects which support the same _observations_: for functions, observation is _application_; for pairs, it's projection, etc. This is achieved by making the definition of equality acts as a "pattern matching function" on the structure of terms and types. For example, there is a rule which says an equality between functions is a function that returns equalities: | |||
| <figure> | |||
| <div> | |||
| $$ | |||
| \cfrac{}{f \equiv_{(x : A) \to B(x)} g \longrightarrow (x : A) \to (f\ x) \equiv_{B(x)} (g\ x)} | |||
| $$ | |||
| </div> | |||
| <figcaption>Equality of functions is extensional by definition</figcaption> | |||
| </figure> | |||
| So, not only do we have a term `funext` of type `((x : A) → f x == g x) → f == g` but one with a stronger type, namely `((x : A) → f x == g x) == (f == g)`, and that term is.. `refl`! | |||
| OTT is appropriate, in my opinion, for doing set-level mathematics: where types have no "interesting" equality structure. However, it breaks down at higher _h_-levels, where there is interesting structure to be found in the equalities between elements of types. This is because OTT, by placing the $\equiv$ type in its universe of propositions, validates the principle of uniqueness of identity proofs, which says any two proofs of the same equality are themselves equal. UIP conflicts with the univalence axiom of Homotopy Type Theory, by (to use the HoTT terminology) saying that all types are sets. | |||
| <span class="theorem paragraph-marker">**Theorem**</span>. Suppose there exists one universe, $\mathscr{U}$, which contains the type of Booleans. Assuming univalence, the type $a \equiv_{\mathscr{U}} b$ is not a proposition. | |||
| <span class="paragraph-marker">**Proof**</span>. The function $\mathrm{not} : 2 \to 2$, which maps $\mathtt{tt}$ to $\mathtt{ff}$ and vice-versa, is an equivalence, being its own left and right inverses. Thus, by univalence, we have a path $\mathrm{ua}(\mathrm{not}) : 2 \equiv_{\mathscr{U}} 2$. | |||
| To see that this path is different from $\mathrm{refl}_2$, consider its behaviour with respect to transport: $\mathrm{transp}(\mathrm{refl}_2, \mathtt{tt}) \equiv tt$ but $\mathrm{transp}(\mathrm{ua}(\mathrm{not}), \mathtt{tt}) \equiv \mathtt{ff}$. Since $\mathtt{tt}$ is different from $\mathtt{ff}$, it follows that $\mathrm{ua}(\mathrm{not})$ is different from $\mathrm{refl}_2$. <span class=qed>$\blacksquare$</span> | |||
| So, if having univalence is desirable, OTT is off the table. However, the previous example of transporting proofs between equivalent types of natural numbers might not have convinced you that HoTT is indeed an interesting field of study, and univalence might seem mostly like a novelty, a shiny thing to pursue for its own sake (it certainly did to me, at first). So why _is_ HoTT interesting? | |||
| # HoTT | |||
| Between 2012 and 2013, a special year of research took place in the Institute for Advanced Studies to develop a type theory that can be used as a foundation for mathematics "at large". Their result: the book *Homotopy Type Theory: Univalent Foundations for Mathematics*. The IAS Special Year on Univalent Foundations would have been interesting even if it hadn't started a new branch of type theory, just from the participants: Thierry Coquand, Thorsten Altenkirch, Andrej Bauer, Per Martin-Löf and, of course, the late Vladimir Voevodsky. | |||
| HoTT's main contribution to the field, in my (lay) opinion, is the interpretation of _types as spaces_: by interpreting types as homotopy theoretical spaces, a semantics for types with more interesting "equality structure", so to speak, arises. In the "classical" intensional type theory of Agda and friends, and indeed the theory of OTT commented on above, equality is a _proposition_. Agda (without the `--without-K` option) accepts the following proof: | |||
| ```agda | |||
| uip : (A : Set) (x y : A) (p q : x ≡ y) → p ≡ q | |||
| uip A x .x refl refl = refl | |||
| ``` | |||
| Apart from ruling out univalence, UIP rules out another very interesting class of types which can be found in HoTT: the _higher inductive_ types, which contain constructors for _equalities_ as well as for values. | |||
| The simplest higher inductive type is the interval, which has two "endpoints" (`i0` and `i1`) and a path between them: | |||
| ```agda | |||
| data I : Type where | |||
| i0 i1 : I | |||
| seg : i0 ≡ i1 | |||
| ``` | |||
| The names $i_0$, $i_1$ and $\mathrm{seg}$ were chosen to remind the reader of a line *seg*ment between a pair of points. Therefore, we may represent the type $\mathbb{I}$ as a diagram, with discrete points representing $i_0$ and $i_1$, and a line, labelled $\mathrm{seg}$, connecting them. | |||
| <figure> | |||
| <img style="height: 90px" src="/diagrams/eq/interval.svg" /> | |||
| <figcaption>A diagrammatic representation of the type `I`</figcaption> | |||
| </figure> | |||
| The real power of the `I` type comes from its induction principle, which says that, given a proposition $P : \mathbb{I} \to \mathrm{Type}$, if: | |||
| * There exists a pair of proofs $pi_0 : P(i_0)$ and $pi_1 : P(i_1)$, and | |||
| * $pi_0$ and $pi_1$ are equal "with respect to" the path $\mathrm{seg}$, then | |||
| $P$ holds for every element of the interval. However, that second constraint, which relates the two proofs, needs a bit of explaining. What does it mean for two elements to be equal with respect _to a path_? Well, the "obvious" interpretation would be that we require a proof $p\mathrm{seg} : pi_0 \equiv pi_1$. However, this isn't well-typed! The type of $pi_0$ is $P(i_0)$ and the type of $pi_1$ is $P(i_1)$, so we need a way to make them equal. | |||
| This is where the path $\mathrm{seg}$ comes in to save the day. Since it states $i_0$ and $i_1$ are equal, we can transport the proof $pi_0$ _along_ the path $\mathrm{seg}$ to get an inhabitant of the type $P(i_1)$, which makes our desired equality $pi_0$ between $pi_1$ _with respect to_ $\mathrm{seg}$ come out as $\mathrm{transp}(P, \mathrm{seg}, pi_0) \equiv pi_1$, which _is_ well-typed. | |||
| That's fine, I hear you say, but there is a question: how is the interval type _useful_? It certainly looks as though if it were useless, considering it's just got one element pretending to be two! However, using the interval higher inductive type, we can actually _prove_ functional extensionality, the principle that says two functions are equal when they're equal pointwise, everywhere. The proof below can be found, in a more presentable manner, in [the HoTT book], section 6.3. | |||
| <span class="theorem paragraph-marker">**Theorem**</span>. If $f$ and $g$ are two functions between $A$ and $B$ such that $f(x) \equiv g(x)$ for all elements $x : A$, then $f \equiv g$. | |||
| <span class="paragraph-marker">**Proof**</span>. Call the proof we were given $p : \prod_{(x : A)} f(x) \equiv g(x)$ We define, for all $x : A$, the function $p^\prime_{x} : \mathbb{I} \to B$ by induction on $I$. Let $p^\prime_{x}(i_0) = f(x)$, $p^\prime_{x}(i_1) = g(x)$. The equality between these terms is given by $p^\prime_{x}(\mathrm{seg}) = p(x)$. | |||
| Now, define $q : \mathbb{I} \to A \to B$ by $q(i) = \lambda x. p^\prime_x(i)$. We have that $q(i_0)$ is the function $\lambda x. p^\prime_{x}(i_0)$, which is defined to be $\lambda x. f(x)$, which is $\eta$-equal to $f$. Similarly, $q(i_1)$ is equal to $g$, and thus, $q(\mathrm{seg}) : f \equiv g$. <span class="qed">$\blacksquare$</span> | |||
| Isn't that _cool_? By augmenting our inductive types with the ability to additionally specify equalities between elements, we get a proof of function extensionality! I think that's pretty cool. Of course, if HITs were limited to structures like the interval, spheres, and other abstract mathematical things, they wouldn't be very interesting for programmers. However, the ability to endow types with additional equalities is _also_ useful when doing down-to-earth programming! A [2017 paper] by Basold et al explores three applications of HITs to programming, in addition to containing an accessible introduction to HoTT in general. | |||
| Another very general higher inductive type, one that might be more obviously useful, is the general type of _quotients_. Whenever $A$ is a type and $R$ is a binary, _propositional_ relation between members of $A$, we can form the quotient type $A/R$, which is given by the following constructors[^2]: | |||
| * $\mathrm{intro}$ says that, for each $x : A$, we can make an element of $A/R$, and | |||
| * $\mathrm{quot}$ which gives, for each $x, y : A$ which are related by $R$, an equality between $\mathrm{intro}(x)$ and $\mathrm{intro}(y)$. | |||
| The induction principle for quotients, which is far too complicated to include here (but can be derived mechanically from the specification given above and the knowledge of "equal with respect to some path" from the section on the interval), says roughly that we can pattern-match on $A/R$ if and only the function we're defining does not distinguish between elements related by $R$. | |||
| This type is very general! For example, given a type of naturals $\mathbb{N}$ and a two-place relation $\mathrm{mod2}$ which holds for numbers congruent modulo 2, we can form the quotient type $\mathbb{N}/\mathrm{mod2}$ of naturals mod 2. Functions (say, $f$) defined on this type must then respect the relation that, whenever $x \equiv y \mod 2$, $f(x) \equiv f(y)$. | |||
| All of this talk about HoTT, and in fact the book itself, though, neglected to mention one thing. What is the _computational content_ of the univalence axiom? What are the reduction rules for matching on higher inductive types? How do we take a proof, written in the language of HoTT, and run it? The Book does not address this, and in fact, it's still a half-open problem, and has been since 2013. Computing in the presence of all these paths, paths between paths, ad infinitum is mighty complicated. | |||
| # Cubical TT | |||
| The challenge of making a computational HoTT did not stop Cohen et al, who in [a 2016 paper] presented _Cubical Type Theory_, which, after three years of active research, provides a way to compute in the presence of univalence. There's just one problem, though: cubical type theory is _hella complicated_. | |||
| The core idea is simple enough: we extend type theory with a set of names $\mathbb{I}$, with points $0$ and $1$ and operations $\vee$, $\wedge$, and $1 - r$, which behave like a de Morgan algebra. To represent equalities, the type $\mathrm{Path}\ A\ t\ u$ is introduced, together with a "name abstraction" operation $\langle i \rangle\ t$ and "path application" $t\ r$, where $r$ is an element of the interval. | |||
| <div class="mathpar"> | |||
| <figure> | |||
| <div> | |||
| $$ | |||
| \frac{\Gamma, i : \mathbb{I} \vdash t : A}{\Gamma \vdash \langle i \rangle\ t : \mathrm{Path}\ A\ t[0/i]\ t[1/i]} | |||
| $$ | |||
| </div> | |||
| </figure> | |||
| <figcaption>Path formation</figcaption> | |||
| <figure> | |||
| <div> | |||
| $$ | |||
| \frac{\Gamma, t : \mathrm{Path}\ A\ a\ b\quad\Gamma \vdash r : \mathbb{I}}{\Gamma \vdash t\ r : A} | |||
| $$ | |||
| </div> | |||
| </figure> | |||
| <figcaption>Path elimination</figcaption> | |||
| </div> | |||
| The intuition, the authors say, is that a term with $n$ variables of $\mathbb{I}$-type free corresponds to an $n$-dimensional cube. | |||
| <table> | |||
| <tr> | |||
| <td>$\cdot \vdash A : \mathrm{Type}$</td> | |||
| <td class=image><img style="height: 30px;" alt="0 dimensional cube" src="/diagrams/eq/0cube.svg" /></td> | |||
| </tr> | |||
| <tr> | |||
| <td>$i : \mathbb{I} \vdash A : \mathrm{Type}$</td> | |||
| <td class=image><img style="height: 32px;" alt="1 dimensional cube" src="/diagrams/eq/1cube.svg" /></td> | |||
| </tr> | |||
| <tr> | |||
| <td>$i, j : \mathbb{I} \vdash A : \mathrm{Type}$</td> | |||
| <td class=image><img style="height: 120px;" alt="2 dimensional cube" src="/diagrams/eq/2cube.svg" /></td> | |||
| </tr> | |||
| </table> | |||
| This is about where anyone's "intuition" for Cubical Type Theory, especially my own, flies out the window. Specifically, using abstraction and the de Morgan algebra on names, we can define operations such as reflexivity ($\langle i \rangle a : \mathrm{Path}\ A\ a\ a$), symmetry ($\lambda p. \langle i \rangle p\ (1 - i) : \mathrm{Path}\ A\ a\ b \to \mathrm{Path}\ A\ b\ a$), congruence, and even function extensionality, which has a delightfully simple proof: $\lambda p. \langle i \rangle\ \lambda x. p\ x\ i$. | |||
| However, to transport along these paths, the paper defines a "face lattice", which consists of constraints on elements of the interval, uses that to define "systems", which are arbitrary restrictions of cubes; From systems, one can define "composition", which compute the lid of an open box (yeah, I don't get it either), "Kan filling", and finally, transport. Since the authors give a semantics of Cubical Type Theory in a previously well-established model of cubical sets, I'll just.. take their word on this. | |||
| The [Cubical Agda documentation] has a section explaining a generalised transport operation `transp` and the regular transport operation `transport`. I recommend that you go check _that_ out, since explaining each is beyond my powers. However, this transport operation _does_ let us prove that the J induction principle for equalities also holds for these cubical paths, and from that we can define all of the other nice operations! | |||
| Cubical Agda, a proof assistant based on Cubical Type Theory, exports a library which provides all of HoTT's primitive notions (The identity type, transport, the J rule, function extensionality, univalence), that compute properly. Furthermore, it supports higher inductive types! However, as I understand it, these can not be compiled into an executable program yet. This is because the `transp` operation, fundamental to computation in the presence of path types, is defined on the structure of the type we're transporting over, and type structure is not preserved when compiling. | |||
| # So What? | |||
| Even after all this explanation of fancy equality relations, you might still be unconvinced. I certainly was, for a while. But I'd argue that, if you care about typed programming enough to be interested in dependent types _at all_, you should be interested in, at least, the quotient inductive types of OTT, if not the more general higher inductive types of HoTT. | |||
| The reason for this is simple: inductive types let you restrict how elements of a type are _formed_. Quotient inductive types let you restrict, in a principled way, how elements of a type are _used_. Whereas in languages without quotients, like Haskell or even non-cubical Agda, one is forced to use the module system to hide the inductive structure of a type if they wish to prevent unauthorized fiddling with structure, in a language with quotients, we can have the type checker enforce, internally, that these invariants are maintained. | |||
| Just like quantitative type theory gives programmers a way to reason about resource usage, and efficiently implement mutable structures in a referentially-transparent way, I strongly believe that quotient types, and even univalent parametricity (when we figure out how to compile that) are the "next step forward" in writing reliable software using types as a verification method. | |||
| However, dependent types are not the only verification method! Indeed, there are a number of usability problems to solve with dependent types for them to be adopted by the mainstream. A grim fact that everyone who wants reliable software has to face every day is that most programmers are out there using _JavaScript_, and that the most popular typed language released recently is _Go_.[^3] | |||
| So I leave you, dear reader, with this question: what can we do, as researchers and implementors, to make dependently typed languages more user-friendly? If you are not a researcher, and you have tried a dependently typed language, what are pain points you have encountered? And if you haven't used a dependently typed language, why not? | |||
| <div class="special-thanks"> | |||
| With special thanks to | |||
| * [My friend V for helping with my supbar my English](https://anomalous.eu/) | |||
| * [My friend shikhin for proof-reading the mathematics.](https://twitter.com/idraumr) | |||
| </div> | |||
| [^1]: This is a simplified presentation that uses a single, inconsistent universe (Girard's paradox applies). The actual presentation uses a stratified, predicative hierarchy of $\mathrm{Set}_i$ universes to avoid this paradox. | |||
| [^2]: The presentation of quotients in the HoTT book also contains a _0-truncation_ constructor, which has to do with limiting quotients to work on sets only. The details are, IMO, out of scope for this post; So check out section 6.10 of the book to get all of them. | |||
| [^3]: Please read the italics on this paragraph as derision. | |||
| [a 2007 paper]: http://www.cs.nott.ac.uk/~psztxa/publ/obseqnow.pdf | |||
| [2017 paper]: https://www.researchgate.net/publication/315794623_Higher_Inductive_Types_in_Programming | |||
| [recent paper]: https://arxiv.org/abs/1909.05027 | |||
| [a 2016 paper]: https://arxiv.org/abs/1611.02108 | |||
| [a reddit comment]: https://www.reddit.com/r/haskell/comments/y8kca/generalizednewtypederiving_is_very_very_unsafe/c5tawm8/ | |||
| [the HoTT book]: https://homotopytypetheory.org/book/ | |||
| [Cubical Agda documentation]: https://agda.readthedocs.io/en/v2.6.0/language/cubical.html | |||
+ 637
- 0
pages/posts/2021-01-15-induction.md
View File
| @ -0,0 +1,637 @@ | |||
| --- | |||
| title: On Induction | |||
| date: January 15th, 2021 | |||
| --- | |||
| <!-- | |||
| battle plan: | |||
| - motivate induction via lists | |||
| - close enough to naturals that we can appeal to people's intuition about those | |||
| - a general schema for normal induction (easy enough) | |||
| - handwave about induction-induction (some syntax?) and induction-recursion (a universe?) | |||
| - handwave quotient & higher induction-induction | |||
| --> | |||
| [Last time] on this... thing... I update _very occasionally_, I talked about possible choices for representing equality in type theory. Equality is very important, since many properties of programs and mathematical operators are stated as equalities (e.g., in the definition of a group). However, expressing properties is useless if we can't prove them, and this is where inductive types come in. | |||
| [Last time]: /posts/reflections-on-equality.html | |||
| Inductive types allow users to extend their type theories with new types, generated by _constructors_, which respect an _induction principle_. Constructors are conceptually simple: they provide a way of *construct*ing elements of that type, like the name implies. The induction principle, though, requires a bit more thought. | |||
| The only inductive type | |||
| ----------------------- | |||
| Since this is a blog post about type theory, I am required, by law, to start this discussion about inductive types with the most boring one: the set of all natural numbers, $\mathbb{N}$. The set $\mathbb{N}$ (to be read, and written, `Nat`, from now on) is both uninteresting enough that the discussion can focus on the induction aspect, but also non-trivial enough for some complications to arise. | |||
| The type `Nat`{.dt} is generated by two constructors, one for `zero`{.dt}, and one for the `suc`{.dt}cessor of another number. We can represent this in Agda as in the code block below. Taken together, the signature for the type former (`Nat : Set`{.agda}) and the signatures of all the constructors make up the complete specification of the inductive type, called (confusingly) a signature. Looking at only these we can figure out its fundamental property—its induction principle. | |||
| ```agda | |||
| data Nat : Set where | |||
| zero : Nat | |||
| suc : Nat → Nat | |||
| ``` | |||
| Before we consider the full induction principle, it's useful to consider a simply-typed restriction, called the _recursor_. Every inductive type has a recursor, but this name makes the most sense when talking about natural numbers, because it operationally models primitive recursion. The recursor for the natural numbers is a (dependent) function with the following parameters: | |||
| - A _motive_, the type we elminate into; | |||
| - A _method_ for the constructor `zero`, that is, an element of `A`, and | |||
| - A _method_ for the constructor `succ`, which is a function from `A → A`. | |||
| To put it into code: | |||
| ``` | |||
| foldNat : (A : Type) → A → (A → A) → Nat → A | |||
| ``` | |||
| Furthermore, the recursor has, as anything in type theory, computational behaviour. That is, when applied to all of its arguments, `foldNat` evaluates. This evaluation is recursive, but pay attention to the structure: we only ever apply `foldNat` to values "smaller" (contained in) the data we started with. | |||
| ```agda | |||
| foldNat : (A : Type) → A → (A → A) → Nat → A | |||
| foldNat A z s zero = z | |||
| foldNat A z s (suc x) = s (foldNat A z s x) | |||
| ``` | |||
| To see how one derives the recursor from the signature, we would have to take a detour through category theory. While a complete semantic argument is preferable, for now, some handwaving is in order. To cite my sources: this presentation of algebras was given in [Kaposi 2020], a very well-written paper which you should check out if you want to understand how algebras work for higher inductive types. | |||
| [Kaposi 2020]: https://arxiv.org/pdf/1902.00297.pdf | |||
| Take a **`Nat`{.dt}-algebra** to be a dependent triple `(C : Set) × C × (C → C)`{.agda}. The type `C` is known as the _carrier_ of the algebra. From this type of algebras we can define a type family of _`Nat`{.dt}-algebra homomorphisms_ between two algebras, which are structure-preserving maps between them. This definition is a bit complicated, so it's in a box: | |||
| ```agda | |||
| Alg : Set₁ | |||
| Alg = Σ Set₀ λ Nat → Σ Nat λ _ → (Nat → Nat) | |||
| Morphism : Alg → Alg → Set | |||
| Morphism (N0 , z0 , s0) (N1 , z1 , s1) = | |||
| Σ (N0 → N1) λ NM → | |||
| Σ (NM z0 ≡ z1) λ _ → | |||
| ((n : N0) → NM (s0 n) ≡ s1 (NM n)) | |||
| ``` | |||
| A morphism between algebras $(N_0, z_0, s_0)$ and $(N_1, z_1, s_1)$ consists of a map $N^M : N_0 \to N_1$ between their carriers together with data proving that $N^M$ maps the objects in $N_0$ to the "right" objects in $N_1$. | |||
| Suppose for a second that we have a "special" `Nat`{.dt}-algebra, denoted `Nat*`{.dt}. The statement that there exists a recursion principle for the `Nat`{.dt}ural numbers is then a function with the type boxed below. | |||
| ``` | |||
| recursion : (α : Alg) → Morphism Nat* α | |||
| ``` | |||
| To borrow some more terminology from our category theorist friends, it's stating that `Nat*`{.dt} is _weakly initial_ in the category of `Nat`{.dt}-algebras: For every other algebra `α` we have a homomorphism `Nat* → α`. It turns out that, if our type theory has inductive types, we can implement this function! The initial algebra is given by `(Nat, zero, suc)` and the `recursion` principle by the function below: | |||
| ```agda | |||
| Nat* : Alg | |||
| Nat* = (Nat, zero, suc) | |||
| recursion : (α : Alg) → Morphism Nat* α | |||
| recursion (N0 , z0 , s0) = map , refl , λ n → refl where | |||
| map : Nat → N0 | |||
| map zero = z0 | |||
| map (suc x) = s0 (map x) | |||
| ``` | |||
| In particular, to be very needlessly formal, "every inductive type is the _initial algebra_ of some strictly-positive endofunctor." It's no surprise, then, that we can give such an initial algebra for the natural numbers in Agda, a theory with inductive types! The "shape" of this functor depends on the constructors of the inductive type, but the general principle is the same: Data representing the type (the carrier) together with data for every constructor, with the inductive type "replaced" by the carrier. | |||
| And then some more | |||
| ------------------ | |||
| A trivial inductive type we can discuss is the unit type, or top type: | |||
| ```agda | |||
| data Unit : Set where | |||
| point : Unit | |||
| ``` | |||
| Let's speedrun through the definition of `Unit`{.dt}-algebras, `Unit`{.dt}-algebra homomorphisms, and the initial `Unit`{.dt}-algebra. The name `point`{.dt} was picked for the constructor to be indicative of these structures: `Unit`{.dt} is the _initial pointed type_. A pointed type `T` is a type for which we have a point `p : T`—oops, there's our algebra type! It's `(T : Set) × T`. | |||
| _Wait, what? Really?_, I hear you ask. You proceed: _An algebra for the `Unit` type is just a pointed type?_ Yup, my dear reader: the only data we need to eliminate from `Unit` is the type we're eliminating into (the carrier `C`) and a value in `C`, that we map our `point` to! | |||
| The family of types between unit types can also be specified in Agda, but I'm absolutely sure you can work it out: It's a function $U^M : U_0 \to U_1$ such that $U^M p_0 \equiv p_1$. | |||
| ```agda | |||
| Unit-Alg : Set₁ | |||
| Unit-Alg = Σ Set λ Unit → Unit | |||
| Unit-Morphism : Unit-Alg → Unit-Alg → Set | |||
| Unit-Morphism (U0 , p0) (U1 , p1) = Σ (U0 → U1) λ UM → UM p0 ≡ p1 | |||
| ``` | |||
| Our definition for Unit-recursion is laughable. It's so trivial that I'm going to go a bit further, and instead of proving _weak_ initiality as we did for the naturals, prove _initiality_: There exists a **unique** map from `(Unit, point)` to any other algebra. For this, we need a notion of uniqueness. Contractibility will do: A type is contractible iff it's pointed and, for every other element, there exists an equality between the point and that element. Check out the box: | |||
| ```agda | |||
| isContr : Set → Set | |||
| isContr T = Σ T λ center → (other : T) → other ≡ center | |||
| ``` | |||
| Or, this is where I _would_ put a nice box together with an Agda-checked proof that `(Unit , point)` is initial... if I had one! Agda does not have a strong enough notion of equality for us to prove this. In particular, Agda out-of-the-box has no _function extensionality_ principle (see my post on equality). However, we _can_ postulate one, and after writing some equality-manipulation functions, write that proof. | |||
| <details> | |||
| <summary>Equality stuff</summary> | |||
| ```agda | |||
| postulate | |||
| funext : {ℓ ℓ' : _} | |||
| {A : Set ℓ} {B : A → Set ℓ'} | |||
| (f g : (x : A) → B x) | |||
| → ((x : A) → f x ≡ g x) → f ≡ g | |||
| subst : {ℓ ℓ' : _} | |||
| {A : Set ℓ} (B : A → Set ℓ') | |||
| {x y : A} | |||
| → x ≡ y → B x → B y | |||
| subst B refl x = x | |||
| pairPath : {ℓ ℓ' : _} | |||
| {A : Set ℓ} {B : A → Set ℓ'} | |||
| {x y : A} | |||
| {e : B x} {e' : B y} | |||
| (p : x ≡ y) | |||
| → subst B p e ≡ e' → (x , e) ≡ (y , e') | |||
| pairPath refl refl = refl | |||
| _∘_ : {ℓ : _} {A : Set ℓ} {x y z : A} → y ≡ z → x ≡ y → x ≡ z | |||
| refl ∘ refl = refl | |||
| UIP : {ℓ : _} {A : Set ℓ} {x y : A} (p q : x ≡ y) → p ≡ q | |||
| UIP refl refl = refl | |||
| ``` | |||
| </details> | |||
| I'll be the first to admit that all this equality stuff, _especially_ the postulate, is a bit gross. However, it's all justifiable: In particular, the setoid model of type theory validates all of MLTT + funext + UIP, so we're in the clear. The `pairPath` function has a very complicated type: it defines the setoid (or groupoid!) structure of the $\sum$-types. | |||
| If you can intuit that an equality between `(a, b) ≡ (c, d)` consists of a pair of equalities `(a ≡ c) × (b ≡ d)`, `pairPath` is that, but dependent. Since the second components of the pairs have types depending on the first element, we need to coerce `e` along the path between `x ≡ y` to get an element `subst B p e : B y` that we can compare with `e'`. | |||
| ```agda | |||
| Unit-initiality : (α : Unit-Alg) | |||
| → isContr (Unit-Morphism (Unit , point) α) | |||
| Unit-initiality (U0 , p0) = (map , refl) , contract where | |||
| map : Unit → U0 | |||
| map point = p0 | |||
| contract : (other : Unit-Morphism (Unit , point) (U0 , p0)) | |||
| → other ≡ (map , refl) | |||
| contract ( fun , p ) = | |||
| pairPath | |||
| (funext fun map (λ { point → p })) | |||
| (UIP _ _) | |||
| ``` | |||
| With funext, we can also prove `Nat-initiality`, the equivalent statement about natural numbers. Left as an exercise to the reader, though! | |||
| Upgrading your recursion: displayed algebras | |||
| -------------------------------------------- | |||
| Just like we can go from regular pairs to dependent pairs by complicating things, we can complicate the recursor to get an _induction principle_, which uniquely characterises each inductive type. From an algebra (the input to the recursor), we build a **displayed algebra**, which is a logical predicate over the algebra's carrier together with proofs for each of its methods. Let's go back to the natural numbers for a second, since those are more interesting than the unit type. | |||
| Given a $\mathbb{N}$-algebra $\alpha = (N, z, s)$, we define the type of displayed $\mathbb{N}$-algebras over $\alpha$ to be $\sum(N^D : N \to \mathrm{Set}) \sum(z^D : N^D z) (\prod(n : N) N^D n \to N^D (s\ n))$. That is, we "upgrade" the carrier $N$ to a predicate on carriers $N \to \mathrm{Set}$, $z$ gets upgraded to a proof of $N^D z$, and $s$ gets upgraded to a proof that $N^D (s\ n)$ follows from $N^D n$. Check out the box: | |||
| ```agda | |||
| Nat-Displayed : (α : Nat-Alg) → Set₁ | |||
| Nat-Displayed (N , z , s) = | |||
| Σ (N → Set) λ Nd → | |||
| Σ (Nd z) λ _ -> | |||
| (n : N) → Nd n → Nd (s n) | |||
| ``` | |||
| Now we can finally connect the idea of "inductive types" back to the idea of "induction" that some of us got familiar with in a high school proofs class, namely over the natural numbers: | |||
| > Suppose we have a property of the natural numbers, $P$. If: | |||
| > | |||
| > - $P$ holds for $0$, and | |||
| > - Assuming P holds for n, P holds for $n + 1$, then | |||
| > | |||
| > $P$ holds for every natural number. | |||
| This is the same thing we have encoded in the displayed algebras over $(N, z, s)$! Since a predicate is, type-theoretically, a family of types, we interpret our $P$ as $N^D : N \to \mathrm{Set}$. A predicate holds for a value iff you have an inhabitant of the predicate applied to that value, so our proofs become terms of the right type. The universal quantifier for $n$ becomes a dependent function, and the implication a regular function. | |||
| The final piece of our complicated terminology puzzle is the idea of a **section** of a displayed algebra over an algebra, a sentence so utterly convoluted that I wish I had never written it. Just like displayed algebras complicate the idea of algebras, sections complicate algebra homomorphisms. Just like a homomorphism has a map between the algebras' carriers, a section has a dependent map from algebra's carrier to the predicate of the algebra displayed over that one. The dependency structure doesn't make a lot of sense written out, so check out the code: | |||
| ```agda | |||
| Nat-Section : (α : Nat-Alg) → Nat-Displayed α → Set | |||
| Nat-Section (N , z , s ) (Nd , zd , sd ) = | |||
| Σ ((n : N) → Nd n) λ Ns → | |||
| Σ (Ns z ≡ zd) λ _ → | |||
| ((n : N) → Ns (s n) ≡ sd n (Ns n)) | |||
| ``` | |||
| The first component of a section is the induced function generated by the motives packaged together by the displayed algebra $(N^D, z^D, s^D)$. The second two components are _reduction rules_, packaged as propositional equalities! The second component, for instance, specifies that $N^S$ (the function) applied to the $z$ero of our algebra returns the method $z^D$. | |||
| The existence of an induction principle is packaged up by saying that any algebra displayed over the initial one has a section. In code, it's a dependent map `Induction : (M : Nat-Displayed Nat*) → Section M`{.agda}. We can implement that in Agda like in the box below, but because the `map` obeys the computation rules automatically, none of the proof components are incredibly interesting—they're both trivial proofs. | |||
| ```agda | |||
| Nat-induction : (M : Nat-Displayed Nat*) → Nat-Section Nat* M | |||
| Nat-induction (Nd , zd , sd) = map , refl , λ s → refl where | |||
| map : (n : Nat) → Nd n | |||
| map zero = zd | |||
| map (suc x) = sd x (map x) | |||
| ``` | |||
| As an _incredibly_ convoluted example we can use all our algebra machinery to implement.. drumroll, please... addition! | |||
| ```agda | |||
| add : Nat → Nat → Nat | |||
| add = (Nat-induction displayed) ₁ where | |||
| displayed : Nat-Displayed Nat* | |||
| displayed = (λ n → Nat → Nat) | |||
| , (λ z → z) | |||
| , λ _ k z → suc (k z) | |||
| _ : add (suc (suc zero)) (suc (suc zero)) | |||
| ≡ suc (suc (suc (suc zero))) | |||
| _ = refl | |||
| ``` | |||
| Again using our trivial example as a bit more practice before we move on, let's talk displayed algebras and sections for the Unit type. They're both quite easy. Assuming $(U, p)$ is our algebra, the displayed algebra ends up with a predicate $U^D : U → \mathrm{Set}$ together with a proof $p^D : U\ p$. Sections are also quite easy, since there's only one "propositional reduction rule" to give. | |||
| ```agda | |||
| Unit-Displayed : Unit-Alg → Set₁ | |||
| Unit-Displayed (U , p) = Σ (U → Set) λ UD → UD p | |||
| Unit-Section : (α : Unit-Alg) → Unit-Displayed α → Set | |||
| Unit-Section (U , p) (UD , pD) = | |||
| Σ ((x : U) → UD x) λ US → | |||
| US p ≡ pD | |||
| ``` | |||
| Agda once more makes the proofs for writing `Unit-Induction` trivial, so I'll leave both its type and implementation as an exercise for the reader. | |||
| You saw it coming: Vectors | |||
| -------------------------- | |||
| Both of the exceedingly interesting types we looked at above were simple, since they both just exist in a universe, `Set₀`. Now we up the difficulty considerably by adding both _parameters_ and _indices_. Both are arguments to the type itself, but they differ in how they can be used in the constructors. Again, since I am writing about dependent types, I'm obligated by law to mention this example.. fixed-length lists, or vectors. These are _parametrised_ by a type $A$ of elements and _indexed_ by a number $n : \mathbb{N}$, the length. | |||
| ```agda | |||
| data Vec (A : Set₀) : Nat → Set₀ where | |||
| nil : Vec A zero | |||
| cons : (n : Nat) → A → Vec A n → Vec A (suc n) | |||
| ``` | |||
| Parameters, at least in Agda, are introduced before the `:` in the type signature. Indices come later, but both can be dependent. Parameters have to be the same for every constructor (we only ever mention `Vec A`), but the `Nat`ural can vary between the constructors. One introduces a vector of length zero, and one increments the length of a smaller vector. | |||
| The type of algebras for vectors is a tad more interesting, so let's take a look. Since `Vec` is parametrised by `A`, so is `Vec-Alg`. We don't speak of general "vector algebras", only "vector-of-A algebras", so to speak. Since the natural number is an index, it becomes an argument to our carrier type. Both of the "constructor" data are applied to their indices, and since the `A` is bound as an argument to the algebra function, we can refer to it in the type of `cons` (the third component). | |||
| ```agda | |||
| Vec-Alg : Set₀ → Set₁ | |||
| Vec-Alg A = | |||
| Σ (Nat → Set₀) λ Vec → | |||
| Σ (Vec zero) λ nil → | |||
| {- cons : -} (n : Nat) → A → Vec n → Vec (suc n) | |||
| ``` | |||
| The type of homomorphisms for `Vec A`-algebras is mechanically derived from the type above by starting from a map `(n : Nat) → V0 n → V1 n` (where `V0`, `V1` are the carriers of the "source" and "target" algebras) and imposing the necessary conditions. | |||
| ```agda | |||
| Vec-Morphism : (A : Set₀) → Vec-Alg A → Vec-Alg A → Set₀ | |||
| Vec-Morphism A (V0 , n0 , c0) (V1 , n1 , c1) = | |||
| Σ ((n : Nat) → V0 n → V1 n) λ VM → | |||
| Σ (VM zero n0 ≡ n1) λ _ → | |||
| ((n : Nat) (a : A) (xs : V0 n) | |||
| → VM (suc n) (c0 n a xs) ≡ c1 n a (VM n xs)) | |||
| ``` | |||
| Just like in the Nat-algebra morphisms, we have two cases, one of which requires exchanging our map with a constructor—the successor/cons case. It's mostly the same, except for the `A` parameter we have to thread everywhere, and all the indices we have to respect. And, just like back then, assuming funext, we have an initial `Vec A`-algebra given by `(Vec A, nil, cons)`. The proof is full of fiddly details[^1], but it's again justified by the setoid model, with only `funext` needing to be postulated. | |||
| ```agda | |||
| Vec-initiality : (A : Set) (α : Vec-Alg A) | |||
| → isContr (Vec-Morphism A (Vec A , nil , cons) α) | |||
| Vec-initiality A (V0 , n0 , c0) = (map , resp) , contract where | |||
| map : (n : Nat) → Vec A n → V0 n | |||
| map zero nil = n0 | |||
| map (suc n) (cons .n a xs) = c0 n a (map n xs) | |||
| resp = refl , λ n a x → refl | |||
| ``` | |||
| Above we provide the map from `Vec A n` to the algebra `α`'s carrier, `V0`, and prove that it `resp`{.kw}ects the equalities imposed by `Vec A`-homomorphisms. Since Agda has pattern matching built in, these equalities are trivial (`refl`{.agda}). Our proof continues upside-down: The interesting thing here is the `map'≡map` equality. Skip the noise: keep reading after the code. | |||
| ```{.agda .continues} | |||
| contract : (other : Vec-Morphism A (Vec A , nil , cons) | |||
| (V0 , n0 , c0)) | |||
| → other ≡ (map , refl , λ n a xs → refl) | |||
| contract (map' , nM , cM) | |||
| = pairPath | |||
| map'≡map | |||
| (pairPath | |||
| (UIP _ _) | |||
| (funext3 _ _ (λ n a xs → UIP _ _))) | |||
| where | |||
| map'~map : (n : Nat) (xs : Vec A n) → map' n xs ≡ map n xs | |||
| map'~map .zero nil = nM | |||
| map'~map .(suc n) (cons n x xs) = | |||
| subst | |||
| (λ e → map' (suc n) (cons n x xs) ≡ c0 n x e) | |||
| (map'~map n xs) | |||
| (cM n x xs) | |||
| map'≡map = funext2 _ _ map'~map | |||
| ``` | |||
| We build the `map'≡map`{.va} equality by an appeal to `funext2`{.va}, a helper defined in terms of our `funext`{.op} postulate to reduce the noise a tad. Again, I want to stress that this is a failure of Agda: There is a family of semantic models of type theory in which equality in function types is pointwise _by definition_, including the setoid model, which would be very convenient here since we could keep our appeals to `UIP`{.op}. Anything that validates `funext`{.op} would do, though, including Cubical Agda. | |||
| Other than that, the proof is standard: Everything we need is given by the `nM`{.va} and `cM`{.va} equalities of the `other`{.va} morphism we're contracting. In the inductive step, the case for `(cons n x xs)`, we have a path `cM n x xs : map' (suc n) (cons n x xs) ≡ c0 n x (map' n xs)`. Since we want the `map' n xs` on the right-hand side to be `map n xs`, we `subst`{.op} it away using the path `map'~map n xs : map' n xs ≡ map n xs` obtained by a recursive application of `map'~map`{.fn}. | |||
| Now we turn to dependent elimination of vectors, or induction. For this we need to calculate the type of displayed algebras over a given `Vec A`-algebra. It's mechanical: The `V` of our algebra gets upgraded to a family of predicates `P : (n : Nat) → V n → Set₀`. The "constructor data" given by `n , c` become "proof data" of a type extending the `Vec A`-algebra. | |||
| ```agda | |||
| Vec-Displayed : (A : Set₀) → Vec-Alg A → Set₁ | |||
| Vec-Displayed A (V , z , c) = | |||
| Σ ((n : Nat) → V n → Set₀) λ P → | |||
| Σ (P zero z) λ nil → | |||
| {- cons -} (n : Nat) (x : A) (tail : V n) | |||
| → P n tail → P (suc n) (c n x tail) | |||
| ``` | |||
| In the `cons` case, the algebra has access both to the `tail` of type `V n` _and_ the inductive assumption `P n tail`. This represents, operationally, a choice between recurring or not. | |||
| You know the drill by now: after displayed algebras, algebra sections. Assume an algebra `α = (V, nil, cons)` and a displayed algebra `(P, nD, cD)` over `α`. The first component will be a dependent function of type `(n : Nat) (x : V n) → P n x`, and the second and third components will be propositional equalities representing reduction rules. Since the vectors and natural numbers are similar in structure, we'll end up with similar-looking reduction rules, just noisier. Here they are: | |||
| ```agda | |||
| Vec-Section : (A : Set₀) (α : Vec-Alg A) → Vec-Displayed A α → Set | |||
| Vec-Section A (V , n , c) (P , nD , cD) = | |||
| Σ ((n : Nat) (x : V n) → P n x) λ map → | |||
| Σ (map zero n ≡ nD) λ _ → | |||
| ( (n : Nat) (x : A) (tl : V n) | |||
| → map (suc n) (c n x tl) ≡ cD n x tl (map n tl)) | |||
| ``` | |||
| They're not pretty, so take a minute to internalise them. Again, we have the dependent `map`{.op}, together with a propositional equality which says `map zero n` evaluates to the `nD` datum of our displayed map. The third component specifies that `map (suc n)` defers to the `cD` component and recurs in the tail. It's not complicated conceptually, but it is complex to write down. Finally, the induction principle for natural numbers says that any displayed algebra over the initial `(Vec A , nil , cons)` has a section. Again, Agda trivialises the equalities: | |||
| ```agda | |||
| Vec-Induction : (A : Set₀) | |||
| (α : Vec-Displayed A (Vec A , nil , cons)) | |||
| → Vec-Section A (Vec A , nil , cons) α | |||
| Vec-Induction A (P , nD , cD) = map , refl , λ n a xs → refl where | |||
| map : (n : Nat) (xs : Vec A n) → P n xs | |||
| map .zero nil = nD | |||
| map .(suc n) (cons n x xs) = cD n x xs (map n xs) | |||
| ``` | |||
| I bet you've never seen types like these | |||
| ---------------------------------------- | |||
| This is a bet I'm willing to take. Unless you've gone looking for ways to formalise semantics of inductive types before, it's not very likely for you to have come across this algebra machinery before. A far more common way of dealing with inductive data types is dependent pattern matching: | |||
| ```agda | |||
| add : Nat → Nat → Nat | |||
| add zero n = n | |||
| add (suc x) n = suc (x + n) | |||
| map : {n : Nat} {A B : Set₀} → (A → B) → Vec A n → Vec B n | |||
| map f nil = nil | |||
| map f (cons x xs) = cons (f x) (map f xs) | |||
| ``` | |||
| However, there is a very good reason not to work directly with pattern matching in a formalisation. That reason can be found on page 24 of [this paper] by Cockx et al. Take a minute to recover and we can continue talking. A more tractable presentation of inductive types is directly with induction principles, instead of taking this detour through category theory. For instance, the natural numbers: | |||
| ```agda | |||
| Nat-induction : (P : Nat → Set) | |||
| → P zero | |||
| → ((n : Nat) → P n → P (suc n)) | |||
| → (n : Nat) → P n | |||
| Nat-induction P pz ps zero = pz | |||
| Nat-induction P pz ps (suc n) = ps n (Nat-induction P pz ps) | |||
| ``` | |||
| It turns out that this presentation, and the one based on algebras I've been going on about, are actually equivalent! Very plainly so. If you unfold the type of `Nat-Induction` (the one about algebras), and do some gratuitous renaming, you get this: | |||
| ```agda | |||
| Nat-Induction : | |||
| (M : Σ (Nat → Set) | |||
| λ P → Σ (P zero) | |||
| λ _ → (n : Nat) → P n → P (suc n) | |||
| ) | |||
| → Σ ((n : Nat) → M ₁ n) | |||
| λ Nat-ind → Σ (Nat-ind zero ≡ M ₂ ₁) | |||
| λ _ → (n : Nat) → Nat-ind (suc n) = M ₂ ₂ n (Nat-ind n) | |||
| ``` | |||
| It's ugly, especially with all the subscript projections, but if we apply some good ol' currying we can recover this type, by transforming (the dependent analogue of) `A × B × C → D` with `A → B → C → D`: | |||
| ```agda | |||
| Nat-Induction : (P : Nat → Set) | |||
| (pzero : P zero) | |||
| (psuc : (n : Nat) → P n → P (suc n)) | |||
| → Σ ((n : Nat) → P n) | |||
| λ ind → Σ (ind zero ≡ pzero) | |||
| λ _ → (n : Nat) → ind (suc n) ≡ psuc n (ind n) | |||
| ``` | |||
| I've gone and done some more renaming. `P` is a name for `M ₁`, `pzero` is `M ₂ ₁`, and `psuc` is `M ₂ ₂`. Again, just to emphasise what the contents of "a displayed algebra section over the initial algebra" turn out to be: | |||
| - The first component is **a function from the data type to a predicate**, | |||
| - The $n$ following components are **propositional equalities representing reduction rules**, for each constructor, recurring as appropriate. | |||
| If you'll allow me one of _those_ asides, this is just incredibly cool to me. The fact we can start from an inductive signature and derive not only the recursor, but from that derive the motives and methods of induction, and from _that_ derive exactly the behaviour of the induced map for a particular bundle of motives and methods? It feels.. right. Like this is what induction was meant to be. Not some needlessly formal underpinning for pattern matching, like I used to think of it as, but as distinguished, rich mathematical objects determined exactly by their constructors. | |||
| Complicating it further: Induction-induction | |||
| -------------------------------------------- | |||
| We've seen, in the past 2 thousand-something words, how to build algebras, algebra homomorphisms, displayed algebras and algebra sections for inductive types, both indexed and not. Now, we'll complicate it further: Induction-induction allows the formation of two inductive families of types $A : \mathrm{Set}$ and $B : A \to \mathrm{Set}$ _together_, such that the constructors of A can refer to those of B and vice-versa. | |||
| The classic example is defining a type together with an inductively-defined predicate on it, for instance defining sorted lists together with a "less than all elements" predicate in one big induction. However, in the interest of brevity, I'll consider a simpler example: A syntax for contexts and Π-types in type theory. We have one base type, `ι`, which is valid in any context, and a type for dependent products `Π`. If `σ` is a type in `Γ` and `τ` a type in the context `Γ, σ`, then `Π σ τ` is also a type in `Γ`. | |||
| ```agda | |||
| data Ctx : Set | |||
| data Ty : Ctx → Set | |||
| data Ctx where | |||
| stop : Ctx | |||
| pop : (Γ : Ctx) → Ty Γ → Ctx | |||
| data Ty where | |||
| ι : {Γ : Ctx} → Ty Γ | |||
| Π : {Γ : Ctx} (σ : Ty Γ) (τ : Ty (pop Γ σ)) → Ty Γ | |||
| ``` | |||
| Here I'm using Agda's forward-declarationthe definition of their algebras feature to specify the signatures of `Ctx` and `Ty` before its constructors. This is because the constructors of `Ctx` mention the type `Ty`, and the type _of_ `Ty` mentions `Ctx`, so there's no way to untangle them other than this. | |||
| When talking about our standard set of categorical gizmos for inspecting values of inductive type, it's important to note that, just like we can't untangle the definitions of `Ctx` and `Ty`, we can't untangle their algebras either. Instead of speaking of `Ctx`-algebras or `Ty`-algebras, we can only talk of `Ctx-Ty`-algebras.[^2] Let's think through the algebras first, since the rest are derived from that. | |||
| For our `Nat`-algebras, we had as a carrier an element of `Set₀`. For the `Vec`-algebras, we needed a carrier which was an element of `Nat → Set₀`. Now, since we have two types, one of which is indexed, we can't describe their carriers in isolation: We have a _telescope_ of carriers $Σ (\mathrm{Ty}^A : \mathrm{Set}_0) Σ (\mathrm{Ctx}^A : \mathrm{Ty}^A \to \mathrm{Set}_0)$ over which the type of the methods is quantified. Let's go through them in order. | |||
| - `stop : Ctx` gives rise to a method $\mathrm{stop}^A : \mathrm{Ctx}^A$, | |||
| - `pop : (Γ : Ctx) → Ty Γ → Ctx` generates a method $\mathrm{pop}^A : (Γ^A : \mathrm{Ctx}^A) → \mathrm{Ty}^A\ Γ^A → \mathrm{Ctx}^A$ | |||
| - `ι : {Γ : Ctx} → Ty Γ` leads us to jot down a method $\iota^A : \{Γ^A : \mathrm{Ctx}^A\} → \mathrm{Ty}^A\ \Gamma^A$ | |||
| - `Π : {Γ : Ctx} (σ : Ty Γ) (τ : Ty (pop Γ σ)) → Ty Γ` finally gives us a method with the hell-of-a-type | |||
| $\Pi^A : \{\Gamma^A : \mathrm{Ctx}^A\} (\sigma^A : \mathrm{Ty}^A\ \Gamma) (\tau : \mathrm{Ty}^A (\mathrm{pop}^A\ \Gamma^A\ \sigma^A) → \mathrm{Ty}^A\ \Gamma^A)$ | |||
| Let's go back to Agda-land, where I will write exactly the same thing but with syntax somehow even less convenient than LaTeX. Just as a reminder, `Σ A λ x → B` is how I've been writing $\sum(x : A) B$. | |||
| ```agda | |||
| Ctx-Ty-Alg : Set₁ | |||
| Ctx-Ty-Alg = | |||
| Σ Set₀ λ Ctx → | |||
| Σ (Ctx → Set₀) λ Ty → | |||
| Σ Ctx λ stop → | |||
| Σ ((Γ : Ctx) → Ty Γ → Ctx) λ pop → | |||
| Σ ({Γ : Ctx} → Ty Γ) λ ι → | |||
| ({Γ : Ctx} (σ : Ty Γ) (τ : Ty (pop Γ σ)) → Ty Γ) | |||
| ``` | |||
| The type of homomorphisms for these algebras are the same as the ones we've seen before, except for the fact they're way more complicated. Both of the carrier components still become functions, and all of the method components still become equalities which must be respected, except now there's more of them. | |||
| ```{.agda tag=Suffering} | |||
| Ctx-Ty-Morphism : Ctx-Ty-Alg → Ctx-Ty-Alg → Set₀ | |||
| Ctx-Ty-Morphism | |||
| (C0 , T0 , s0 , p0 , i0 , f0) | |||
| (C1 , T1 , s1 , p1 , i1 , f1) | |||
| = | |||
| Σ (C0 → C1) λ Ctx → | |||
| Σ ((x : C0) → T0 x → T1 (Ctx x)) λ Ty → | |||
| -- Constructor data for Ctx | |||
| Σ (Ctx s0 ≡ s1) λ stop → | |||
| Σ ( (x : C0) (ty : T0 x) | |||
| → Ctx (p0 x ty) ≡ p1 (Ctx x) (Ty x ty)) | |||
| λ pop → | |||
| -- Constructor data for Ty | |||
| Σ ({Γ : C0} → Ty Γ (i0 {Γ}) ≡ i1 {Ctx Γ}) λ iota → | |||
| ( {Γ : C0} (σ : T0 Γ) (τ : T0 (p0 Γ σ)) | |||
| → Ty Γ (f0 {Γ} σ τ) | |||
| ≡ f1 (Ty Γ σ) (subst T1 (pop Γ σ) (Ty (p0 Γ σ) τ))) | |||
| ``` | |||
| Ok, I lied. There's more than just the usual "more stuff" complication. In the case for `Π` (nameless, the last component), we need to compare `f0 σ τ` with `f1 (Ty Γ σ) (Ty (p0 Γ σ) τ)`. Read past the symbols: We need to make sure that the `Ty` operation maps `Π` types to `Π` types. But, there's a catch! `Ty (p0 Γ σ) τ)` has type `T1 (Ctx (p0 Γ σ))` (i.e., assemble the context in `C0` with `p0`, then translate to `C1` with `T1`), but `f1` wants something in `T1 (p1 (Ctx Γ) (Ty Γ σ))` (assemble the context in `C1` with translated components). | |||
| We know these types are equal though, the equation `pop` says _just that_! Agda isn't that clever, though (thankfully), so we have to manually cast along the path `pop Γ σ` to make these types line up. Since we have so many equations, we definitely would've ended up with at least one dependent path.[^3] | |||
| I'll pass on proving strict initiality in the interest of brevity, settling for the weak variant. Recall that initiality means we have a distinguished `Ctx-Ty`-algebra, given by the type formers and constructors, from which we can make a morphism to any other algebra. In types: | |||
| ```agda | |||
| Ctx-Ty-Initial : (M : Ctx-Ty-Alg) → Ctx-Ty-Morphism Ctx-Ty* M | |||
| Ctx-Ty-Initial (C0 , T0 , s0 , p0 , i0 , f0) | |||
| = C , T , refl , (λ x ty → refl) , refl , λ σ τ → refl | |||
| where | |||
| C : Ctx → C0 | |||
| T : (x : Ctx) → Ty x → T0 (C x) | |||
| C stop = s0 | |||
| C (pop c t) = p0 (C c) (T c t) | |||
| T γ ι = i0 {C γ} | |||
| T γ (Π σ τ) = f0 (T γ σ) (T (pop γ σ) τ) | |||
| ``` | |||
| I want to make clear that, while this looks like a bloody mess, it was incredibly simple to implement. See the equation `T γ (Π σ τ) = ...`? I didn't write that. I didn't _need_ to. Check out the type of the last component of `Ctx-Ty-Morphism Ctx-Ty* M`. It's literally just saying what the right-hand-side of `T γ (Π σ τ)` needs to be for `(C, T)` to be the morphism part of a **homo**morphism. And the homo (ahem) part is trivial! It's all `refl`s again (are you noticing a trend?). | |||
| Elevating it: Higher Inductive Types | |||
| ------------------------------------ | |||
| The algebra approach isn't limited to the `Set`-level mathematics we've been doing up to now, and it scales very simply to types with path constructors in addition to point constructors. For this part, we unfortunately can't _implement_ any of the proofs in standard Agda, especially Agda `--with-K` that we've been using up to now, but we can still talk about their types. Let's start with the second simplest higher inductive type: Not the circle, but the interval. | |||
| The interval has two endpoints, `l` and `r`, and a line `seg`{.op}ment between them. It's a contractible type, so it's equivalent to the Unit type we've seen before, but it's.. more. The existence of the interval type implies funext, and we'll show that using algebras. | |||
| ```agda | |||
| data I : Type₀ where | |||
| l r : I | |||
| seg : i0 ≡ i1 | |||
| ``` | |||
| The type of algebras for the interval is also simple. We have a carrier, $I^A$, two points $l^A : I^A$ and $r^A : I^A$, and an _equality_ $seg^A : l^A \equiv r^A$. Wait, an equality? Yup! Since the enpoinds `l` and `r` are equal, so must be whatever they map to. But, since we're in HoTT-land now, this equality doesn't necessarily need to be trivial, as we'll see in a second. | |||
| ```agda | |||
| I-Alg : Type₁ | |||
| I-Alg = Σ Type₀ λ I → Σ I λ l → Σ I λ r → l ≡ r | |||
| ``` | |||
| The type of algebra homomorphisms, like before, encompasses a map together with some propositional reductions of that map. We have three "standard" components `I`, `l`, `r`, which are just like for the type of booleans, and a mystery fourth component which expresses the right coherence condition. | |||
| ```agda | |||
| I-Alg-Morphism : I-Alg → I-Alg → Type | |||
| I-Alg-Morphism (I0 , l0 , r0 , seg0) (I1 , l1 , r1 , seg1) = | |||
| Σ (I0 → I1) λ I → | |||
| Σ (I l0 ≡ l1) λ l → | |||
| Σ (I r0 ≡ r1) λ r → | |||
| ``` | |||
| Now the type of the fourth component is interesting. We want `seg0` and `seg1` to be "equal" in some appropriate sense of equality. But they have totally different types! `seg0 : l0 ≡I0 r0` and `seg1 : l1 ≡I1 r1`. It's easy enough to fix the type of `seg0` to be a path in `I0`: `ap I seg0` is a path in `I1` between `I l0` and `I r0`. Out of the pan, into the fire, though. Now the endpoints don't match up! | |||
| Can we fix `I l0` and `I r0` in the endpoints of `seg0`? The answer, it turns out, is yes. We can use path _transitivity_ to alter both endpoints. `r` correctly lets us go from `I r0` to `r1`, but `l` is wrong—it takes `l1` to `I r0`. We want that backwards, so we apply _symmetry_ here. | |||
| ```agda | |||
| (r ∘ (ap I seg0 ∘ sym l)) ≡ seg1 | |||
| ``` | |||
| Now, I'll reproduce an argument from the HoTT book, which proves function extensionality follows from the interval type and its eliminator. But we'll do it with algebras. First, we need to postulate (since Agda is weak), that there exists a weakly initial `I`-algebra. This'll play the part of our data type. In reality, there's a couple more details, but we can ignore those, right? | |||
| <details> | |||
| <summary>We can't.</summary> | |||
| Instead of just full-on postulating the existence of an `I`-algebra and its initiality, I'll define the type `I` (lacking its `seg`) normally, postulate `seg`, then postulate the coherence condition in the definition of `I-Recursion`. This simplifies some proofs since it means `I-Recursion` will compute definitionally on point constructors. | |||
| ```agda | |||
| data I : Type where | |||
| l r : I | |||
| postulate | |||
| seg : l ≡ r | |||
| I* : I-Alg | |||
| I* = (I , l , r , seg) | |||
| I-Recursion : (α : I-Alg) → I-Alg-Morphism I* α | |||
| I-Recursion (I0 , l0 , r0 , seg0) = go , refl , refl , subst (λ e → e ≡ seg0) (∘refl (ap go seg)) sorry where | |||
| go : I → I0 | |||
| go l = l0 | |||
| go r = r0 | |||
| postulate | |||
| sorry : ap go seg ≡ seg0 | |||
| ``` | |||
| There's a bit of ugly equality-wrangling still, but it's fine. All that matters is that it type checks, I suppose. | |||
| </details> | |||
| Now, the argument. We want a function that, given $f, g : A \to B$ and a homotopy $p : \prod(x : A) \to f(x) \equiv g(x)$, produces a path $f \equiv g$. We define a family of functions $h_x : I \to B$ given a $x : A$, which maps `l` to `f(x)`, `r` to `g(x)`, and in the "`seg` case", returns `p(x)`. The algebra is simple: | |||
| ```agda | |||
| I→funext : {A B : Type} (f g : A → B) (hom : (x : A) → f x ≡ g x) → f ≡ g | |||
| I→funext {A} {B} f g p = ? where | |||
| h : A → I → B | |||
| h x = (I-Recursion (B , f x , g x , p x)) ₁ | |||
| ``` | |||
| And for my next trick, I'll define the function `h' = flip h`. Or, in Agda terms, `h' = λ i x → h x i`, a function from `I → A → B`. We have a path between the two endpoints of the segment, so we also have a path between the two "endpoinds" of this function, which we can calculate: | |||
| ```{.agda tag="Mmm, substitution"} | |||
| ap h' seg : (λ i x → h x i) l ≡ (λ i x → h x i) r -- type of ap | |||
| = (λ x → h x l) ≡ (λ x → h x r) -- β-reduce | |||
| = (λ x → f x) ≡ (λ x → g x) -- computation for h | |||
| = f ≡ g -- η-reduce | |||
| ``` | |||
| This concludes our proof: | |||
| ```agda | |||
| I→funext : {A B : Type} (f g : A → B) (hom : (x : A) → f x ≡ g x) → f ≡ g | |||
| I→funext {A} {B} f g p = ap h' seg where | |||
| h : A → I → B | |||
| h x = (I-Recursion (B , f x , g x , p x)) ₁ | |||
| h' : I → A → B | |||
| h' i x = h x i | |||
| ``` | |||
| This concludes our post | |||
| ----------------------- | |||
| God, this was a long one. Four thousand words! And a bit more, with this conclusion. | |||
| I've wanted to write about inductive types for a hecking long time now, ever since the day I finished the equality post. However, coming by motivations in the past year has been.. hard, for everyone. So it's good that I finally managed to it out there! _77 days later_. God. I might write some more type theory in the future, but don't hold your breath! 77 days is like, 36 thousand times more than you could do that for. | |||
| I ended up writing about algebras instead of eliminators or pattern matching because they seamlessly scale up even to higher induction-induction, which ends up having super complicated eliminators, far too much for me to derive by hand (especially early in the AMs, which is when most of this post was written). | |||
| <div class="special-thanks"> | |||
| With special thanks to the proofreader: | |||
| * [My friend Jonathan](https://squiddev.cc) | |||
| </div> | |||
| [this paper]: https://dl.acm.org/doi/10.1145/3236770 | |||
| [^1]: And, full disclosure, took me almost an hour to write at 2 AM... | |||
| [^2]: The best part of this presentation is that it makes painfully clear the infernal way that everything in type theory depends on everything else. | |||
| [^3]: Please forgive my HoTT accent. | |||
+ 321
- 0
site.hs
View File
| @ -0,0 +1,321 @@ | |||
| {-# LANGUAGE BangPatterns #-} | |||
| {-# LANGUAGE MultiWayIf #-} | |||
| {-# LANGUAGE OverloadedStrings #-} | |||
| import qualified Data.ByteString.Lazy.Char8 as BS | |||
| import Data.Functor | |||
| import Control.Concurrent | |||
| import Control.Exception | |||
| import Control.DeepSeq (rnf) | |||
| import Control.Monad | |||
| import Text.Pandoc.Highlighting | |||
| import Text.Pandoc.Options | |||
| import Text.Pandoc.Definition | |||
| import Text.Sass.Functions | |||
| import Text.Pandoc.Walk (query, walkM) | |||
| import Hakyll.Core.Compiler | |||
| import Hakyll.Web.Sass | |||
| import Hakyll | |||
| import qualified Skylighting as Sky | |||
| import Data.ByteString.Lazy.Char8 (pack, unpack) | |||
| import qualified Network.URI.Encode as URI (encode) | |||
| import System.Environment | |||
| import System.Process | |||
| import System.Exit | |||
| import System.IO | |||
| import qualified Data.Text as T | |||
| import qualified Data.Text.Encoding as T | |||
| import Hakyll.Core.Compiler.Internal | |||
| import Data.List | |||
| import Data.Char | |||
| import qualified Data.Map.Strict as Map | |||
| import Data.Monoid | |||
| import Debug.Trace | |||
| import Data.Maybe | |||
| readerOpts :: ReaderOptions | |||
| readerOpts = def { readerExtensions = pandocExtensions | |||
| , readerIndentedCodeClasses = ["amulet"] } | |||
| writerOptions :: Compiler WriterOptions | |||
| writerOptions = do | |||
| syntaxMap <- loadAllSnapshots "syntax/*.xml" "syntax" | |||
| <&> foldr (Sky.addSyntaxDefinition . itemBody) Sky.defaultSyntaxMap | |||
| pure $ defaultHakyllWriterOptions | |||
| { writerExtensions = extensionsFromList | |||
| [ Ext_tex_math_dollars | |||
| , Ext_tex_math_double_backslash | |||
| , Ext_latex_macros | |||
| ] <> writerExtensions defaultHakyllWriterOptions | |||
| , writerSyntaxMap = syntaxMap | |||
| , writerHighlightStyle = Just kate | |||
| } | |||
| rssfeed :: FeedConfiguration | |||
| rssfeed | |||
| = FeedConfiguration { feedTitle = "Abigail's Blag: Latest articles" | |||
| , feedDescription = "" | |||
| , feedAuthorName = "Abigail Magalhães" | |||
| , feedAuthorEmail = "[email protected]" | |||
| , feedRoot = "https://abby.how" | |||
| } | |||
| conf :: Configuration | |||
| conf = def { destinationDirectory = ".site" | |||
| , storeDirectory = ".store" | |||
| , tmpDirectory = ".store/tmp" | |||
| , deployCommand = "./sync" } | |||
| tikzFilter :: Block -> Compiler Block | |||
| tikzFilter (CodeBlock (id, "tikzpicture":extraClasses, namevals) contents) = | |||
| (imageBlock . T.pack . ("data:image/svg+xml;utf8," <>) . URI.encode . filter (/= '\n') . T.unpack . itemBody <$>) $ | |||
| makeItem contents | |||
| >>= loadAndApplyTemplate (fromFilePath "templates/tikz.tex") (bodyField "body") . fmap T.unpack | |||
| >>= withItemBody (pure . BS.fromStrict . T.encodeUtf8 | |||
| >=> unixFilterLBS "rubber-pipe" ["--pdf"] | |||
| >=> unixFilterLBS "pdftocairo" ["-svg", "-", "-"] | |||
| >=> pure . T.decodeUtf8 . BS.toStrict) | |||
| . fmap T.pack | |||
| where imageBlock fname = Para [Image (id, "tikzpicture":extraClasses, namevals) [] (fname, "")] | |||
| tikzFilter x = return x | |||
| katexFilter :: Pandoc -> Compiler Pandoc | |||
| katexFilter (Pandoc meta doc) = do | |||
| id <- compilerUnderlying <$> compilerAsk | |||
| t <- getMetadata id | |||
| case lookupString "fastbuild" t of | |||
| Just _ -> pure (Pandoc meta doc) | |||
| Nothing -> Pandoc meta <$> walkM go doc | |||
| where | |||
| go :: Inline -> Compiler Inline | |||
| go (Math kind math) = unsafeCompiler $ do | |||
| let args = | |||
| case kind of | |||
| DisplayMath -> ["-Std"] | |||
| InlineMath -> ["-St"] | |||
| (contents, _) <- readProcessBS "node_modules/.bin/katex" args . BS.fromStrict . T.encodeUtf8 $ math | |||
| pure . RawInline "html" . T.init . T.init . T.decodeUtf8 . BS.toStrict $ contents | |||
| go x = pure x | |||
| estimateReadingTime :: Pandoc -> Pandoc | |||
| estimateReadingTime (Pandoc meta doc) = Pandoc meta doc' where | |||
| wordCount = T.pack (show (getSum (query inlineLen doc))) | |||
| inlineLen (Str s) = Sum (length (T.words s)) | |||
| inlineLen _ = mempty | |||
| doc' = RawBlock "html" ("<span id=reading-length>" <> wordCount <> "</span>") | |||
| : doc | |||
| addLanguageTag :: Block -> Block | |||
| addLanguageTag block@(CodeBlock (identifier, classes@(language:classes'), kv) text) = | |||
| Div | |||
| ( mempty | |||
| , "code-container":if haskv then "custom-tag":classes' else classes' | |||
| , [] | |||
| ) | |||
| [Plain [Span (mempty, [], []) [Str tag]], block] | |||
| where | |||
| language' = case T.uncons language of | |||
| Nothing -> mempty | |||
| Just (c, cs) -> T.cons (toUpper c) cs | |||
| tag = fromMaybe language' (lookup "tag" kv) | |||
| haskv = fromMaybe False (True <$ lookup "tag" kv) | |||
| addLanguageTag block@(CodeBlock (identifier, [], kv) text) = Div (mempty, ["code-container"], []) [block] | |||
| addLanguageTag x = x | |||
| sassImporter :: SassImporter | |||
| sassImporter = SassImporter 0 go where | |||
| go "normalize" _ = do | |||
| c <- readFile "node_modules/normalize.css/normalize.css" | |||
| pure [ SassImport { importPath = Nothing | |||
| , importAbsolutePath = Nothing | |||
| , importSource = Just c | |||
| , importSourceMap = Nothing | |||
| } ] | |||
| go _ _ = pure [] | |||
| main :: IO () | |||
| main = (*>) (setEnv "AMC_LIBRARY_PATH" "/usr/lib/amuletml/lib/") $ hakyllWith conf $ do | |||
| let compiler = do | |||
| wops <- writerOptions | |||
| pandocCompilerWithTransformM readerOpts wops $ | |||
| walkM tikzFilter | |||
| >=> katexFilter | |||
| >=> pure . estimateReadingTime | |||
| >=> walkM (pure . addLanguageTag) | |||
| match "static/**/*" $ do | |||
| route idRoute | |||
| compile copyFileCompiler | |||
| match "css/**/*" $ do | |||
| route idRoute | |||
| compile copyFileCompiler | |||
| match "css/*.css" $ do | |||
| route idRoute | |||
| compile copyFileCompiler | |||
| match "css/*.scss" $ do | |||
| route $ setExtension "css" | |||
| compile $ sassCompilerWith def { sassOutputStyle = SassStyleCompressed | |||
| , sassImporters = Just [ sassImporter ] | |||
| } | |||
| match "diagrams/**/*.tex" $ do | |||
| route $ setExtension "svg" | |||
| compile $ getResourceBody | |||
| >>= loadAndApplyTemplate "templates/tikz.tex" (bodyField "body") | |||
| >>= withItemBody (return . pack | |||
| >=> unixFilterLBS "rubber-pipe" ["--pdf"] | |||
| >=> unixFilterLBS "pdftocairo" ["-svg", "-", "-"] | |||
| >=> return . unpack) | |||
| match "pages/posts/*" $ do | |||
| route $ metadataRoute pathFromTitle | |||
| compile $ compiler | |||
| >>= loadAndApplyTemplate "templates/post.html" postCtx | |||
| >>= saveSnapshot "content" | |||
| >>= loadAndApplyTemplate "templates/default.html" postCtx | |||
| >>= relativizeUrls | |||
| create ["archive.html"] $ do | |||
| route idRoute | |||
| compile $ do | |||
| posts <- recentFirst =<< loadAll "posts/*" | |||
| let archiveCtx = | |||
| listField "posts" postCtx (return posts) <> | |||
| constField "title" "Archives" <> | |||
| defaultContext | |||
| makeItem "" | |||
| >>= loadAndApplyTemplate "templates/archive.html" archiveCtx | |||
| >>= loadAndApplyTemplate "templates/default.html" archiveCtx | |||
| >>= relativizeUrls | |||
| match "pages/*.html" $ do | |||
| route $ gsubRoute "pages/" (const "") | |||
| compile $ do | |||
| posts <- fmap (take 5) . recentFirst =<< loadAll "posts/*" | |||
| let indexCtx = | |||
| listField "posts" postCtx (return posts) <> | |||
| constField "title" "Home" <> | |||
| defaultContext | |||
| getResourceBody | |||
| >>= applyAsTemplate indexCtx | |||
| >>= loadAndApplyTemplate "templates/default.html" indexCtx | |||
| >>= relativizeUrls | |||
| match "pages/*.md" $ do | |||
| route $ gsubRoute "pages/" (const "") <> setExtension "html" | |||
| compile $ compiler | |||
| >>= loadAndApplyTemplate "templates/default.html" defaultContext | |||
| >>= relativizeUrls | |||
| match "syntax/*.xml" $ compile $ do | |||
| path <- toFilePath <$> getUnderlying | |||
| contents <- itemBody <$> getResourceBody | |||
| debugCompiler ("Loaded syntax definition from " ++ show path) | |||
| res <- unsafeCompiler (Sky.parseSyntaxDefinitionFromString path contents) | |||
| _ <- saveSnapshot "syntax" =<< case res of | |||
| Left e -> fail e | |||
| Right x -> makeItem x | |||
| makeItem contents | |||
| match "templates/*" $ compile templateBodyCompiler | |||
| create ["feed.xml"] $ do | |||
| route idRoute | |||
| compile $ do | |||
| let feedCtx = postCtx <> bodyField "description" | |||
| posts <- (take 10 <$>) . recentFirst =<< loadAllSnapshots "posts/*" "content" | |||
| renderRss rssfeed feedCtx posts | |||
| postCtx :: Context String | |||
| postCtx = | |||
| dateField "date" "%B %e, %Y" | |||
| <> defaultContext | |||
| readProcessBS :: FilePath -> [String] -> BS.ByteString -> IO (BS.ByteString, String) | |||
| readProcessBS path args input = | |||
| let process = (proc path args) | |||
| { std_in = CreatePipe | |||
| , std_out = CreatePipe | |||
| , std_err = CreatePipe | |||
| } | |||
| in withCreateProcess process $ \stdin stdout stderr ph -> | |||
| case (stdin, stdout, stderr) of | |||
| (Nothing, _, _) -> fail "Failed to get a stdin handle." | |||
| (_, Nothing, _) -> fail "Failed to get a stdout handle." | |||
| (_, _, Nothing) -> fail "Failed to get a stderr handle." | |||
| (Just stdin, Just stdout, Just stderr) -> do | |||
| out <- BS.hGetContents stdout | |||
| err <- hGetContents stderr | |||
| withForkWait (evaluate $ rnf out) $ \waitOut -> | |||
| withForkWait (evaluate $ rnf err) $ \waitErr -> do | |||
| -- Write input and close. | |||
| BS.hPutStr stdin input | |||
| hClose stdin | |||
| -- wait on the output | |||
| waitOut | |||
| waitErr | |||
| hClose stdout | |||
| hClose stderr | |||
| -- wait on the process | |||
| ex <- waitForProcess ph | |||
| case ex of | |||
| ExitSuccess -> pure (out, err) | |||
| ExitFailure ex -> fail (err ++ "Exited with " ++ show ex) | |||
| where | |||
| withForkWait :: IO () -> (IO () -> IO a) -> IO a | |||
| withForkWait async body = do | |||
| waitVar <- newEmptyMVar :: IO (MVar (Either SomeException ())) | |||
| mask $ \restore -> do | |||
| tid <- forkIO $ try (restore async) >>= putMVar waitVar | |||
| let wait = takeMVar waitVar >>= either throwIO return | |||
| restore (body wait) `onException` killThread tid | |||
| pathFromTitle :: Metadata -> Routes | |||
| pathFromTitle meta = | |||
| let | |||
| declaredCategory = | |||
| case lookupString "category" meta of | |||
| Just s -> ((s ++ "/") ++) | |||
| Nothing -> ("posts/" <>) | |||
| !titleString = | |||
| case lookupString "title" meta of | |||
| Just s -> s | |||
| Nothing -> error "post has no title?" | |||
| title = filter (/= "") . map (filter isAlphaNum . map toLower) . words $ titleString | |||
| (category, title') = | |||
| if | "or" `elem` title -> (declaredCategory, takeWhile (/= "or") title) | |||
| | ["a", "quickie"] `isPrefixOf` title -> (("quick/" ++), drop 2 title) | |||
| | otherwise -> (declaredCategory, title) | |||
| in | |||
| case lookupString "path" meta of | |||
| Just p -> constRoute (category (p <> ".html")) | |||
| Nothing -> constRoute (category (intercalate "-" title' <> ".html")) | |||
| foldMapM :: (Monad w, Monoid m, Foldable f) => (a -> w m) -> f a -> w m | |||
| foldMapM k = foldr (\x y -> do { m <- k x; (m <>) <$> y }) (pure mempty) | |||
+ 6
- 0
stack.yaml
View File
| @ -0,0 +1,6 @@ | |||
| resolver: lts-16.20 | |||
| extra-deps: | |||
| - hakyll-sass-0.2.4@sha256:4d2fbd8b63f5ef15483fc6dda09e10eefd63b4f873ad38dec2a3607eb504a8ba,939 | |||
| - hsass-0.8.0@sha256:05fb3d435dbdf9f66a98db4e1ee57a313170a677e52ab3a5a05ced1fc42b0834,2899 | |||
| - hlibsass-0.1.10.1@sha256:08db56c633e9a83a642d8ea57dffa93112b092d05bf8f3b07491cfee9ee0dfa5,2565 | |||
+ 33
- 0
stack.yaml.lock
View File
| @ -0,0 +1,33 @@ | |||
| # This file was autogenerated by Stack. | |||
| # You should not edit this file by hand. | |||
| # For more information, please see the documentation at: | |||
| # https://docs.haskellstack.org/en/stable/lock_files | |||
| packages: | |||
| - completed: | |||
| hackage: hakyll-sass-0.2.4@sha256:4d2fbd8b63f5ef15483fc6dda09e10eefd63b4f873ad38dec2a3607eb504a8ba,939 | |||
| pantry-tree: | |||
| size: 217 | |||
| sha256: c03e74e71d010f009b8d972efc31fbd6dd25183e6d9afbec55f4b7f0d4a74b47 | |||
| original: | |||
| hackage: hakyll-sass-0.2.4@sha256:4d2fbd8b63f5ef15483fc6dda09e10eefd63b4f873ad38dec2a3607eb504a8ba,939 | |||
| - completed: | |||
| hackage: hsass-0.8.0@sha256:05fb3d435dbdf9f66a98db4e1ee57a313170a677e52ab3a5a05ced1fc42b0834,2899 | |||
| pantry-tree: | |||
| size: 1448 | |||
| sha256: b25aeb947cb4e0b550f8a6f226d06503ef0edcb54712ad9cdd4fb2b05bf16c7c | |||
| original: | |||
| hackage: hsass-0.8.0@sha256:05fb3d435dbdf9f66a98db4e1ee57a313170a677e52ab3a5a05ced1fc42b0834,2899 | |||
| - completed: | |||
| hackage: hlibsass-0.1.10.1@sha256:08db56c633e9a83a642d8ea57dffa93112b092d05bf8f3b07491cfee9ee0dfa5,2565 | |||
| pantry-tree: | |||
| size: 11229 | |||
| sha256: 39b62f1f3f30c5a9e12f9c6a040d6863edb5ce81951452e649152a18145ee1bc | |||
| original: | |||
| hackage: hlibsass-0.1.10.1@sha256:08db56c633e9a83a642d8ea57dffa93112b092d05bf8f3b07491cfee9ee0dfa5,2565 | |||
| snapshots: | |||
| - completed: | |||
| size: 532177 | |||
| url: https://raw.githubusercontent.com/commercialhaskell/stackage-snapshots/master/lts/16/20.yaml | |||
| sha256: 0e14ba5603f01e8496e8984fd84b545a012ca723f51a098c6c9d3694e404dc6d | |||
| original: lts-16.20 | |||
+ 140
- 0
static/Parser.hs
View File
| @ -0,0 +1,140 @@ | |||
| {-# LANGUAGE LambdaCase #-} | |||
| module Parser | |||
| ( Parser() | |||
| , module X | |||
| , Parser.any | |||
| , satisfy | |||
| , string | |||
| , digit | |||
| , number | |||
| , spaces | |||
| , reserved | |||
| , lexeme | |||
| , (<?>) | |||
| , runParser | |||
| , between ) where | |||
| import Control.Applicative as X | |||
| import Control.Monad as X | |||
| import Data.Char | |||
| newtype Parser a | |||
| = Parser { parse :: String -> Either String (a, String) } | |||
| runParser :: Parser a -> String -> Either String a | |||
| runParser (Parser p) s = fst <$> p s | |||
| (<?>) :: Parser a -> String -> Parser a | |||
| p <?> err = p <|> fail err | |||
| infixl 2 <?> | |||
| instance Functor Parser where | |||
| fn `fmap` (Parser p) = Parser go where | |||
| go st = case p st of | |||
| Left e -> Left e | |||
| Right (res, str') -> Right (fn res, str') | |||
| instance Applicative Parser where | |||
| pure x = Parser $ \str -> Right (x, str) | |||
| (Parser p) <*> (Parser p') = Parser go where | |||
| go st = case p st of | |||
| Left e -> Left e | |||
| Right (fn, st') -> case p' st' of | |||
| Left e' -> Left e' | |||
| Right (v, st'') -> Right (fn v, st'') | |||
| instance Alternative Parser where | |||
| empty = fail "nothing" | |||
| (Parser p) <|> (Parser p') = Parser go where | |||
| go st = case p st of | |||
| Left _ -> p' st | |||
| Right x -> Right x | |||
| instance Monad Parser where | |||
| return = pure | |||
| (Parser p) >>= f = Parser go where | |||
| go s = case p s of | |||
| Left e -> Left e | |||
| Right (x, s') -> parse (f x) s' | |||
| fail m = Parser go where | |||
| go = Left . go' | |||
| go' [] = "expected " ++ m ++ ", got to the end of stream" | |||
| go' (x:xs) = "expected " ++ m ++ ", got '" ++ x:"'" | |||
| any :: Parser Char | |||
| any = Parser go where | |||
| go [] = Left "any: end of file" | |||
| go (x:xs) = Right (x,xs) | |||
| satisfy :: (Char -> Bool) -> Parser Char | |||
| satisfy f = do | |||
| x <- Parser.any | |||
| if f x | |||
| then return x | |||
| else fail "a solution to the function" | |||
| char :: Char -> Parser Char | |||
| char c = satisfy (c ==) <?> "literal " ++ [c] | |||
| oneOf :: String -> Parser Char | |||
| oneOf s = satisfy (`elem` s) <?> "one of '" ++ s ++ "'" | |||
| string :: String -> Parser String | |||
| string [] = return [] | |||
| string (x:xs) = do | |||
| char x | |||
| string xs | |||
| return $ x:xs | |||
| natural :: Parser Integer | |||
| natural = read <$> some (satisfy isDigit) | |||
| lexeme :: Parser a -> Parser a | |||
| lexeme = (<* spaces) | |||
| reserved :: String -> Parser String | |||
| reserved = lexeme . string | |||
| spaces :: Parser String | |||
| spaces = many $ oneOf " \n\r" | |||
| digit :: Parser Char | |||
| digit = satisfy isDigit | |||
| number :: Parser Int | |||
| number = do | |||
| s <- string "-" <|> empty | |||
| cs <- some digit | |||
| return $ read (s ++ cs) | |||
| between :: Parser b -> Parser c -> Parser a -> Parser a | |||
| between o c x = o *> x <* c | |||
| contents :: Parser a -> Parser a | |||
| contents x = spaces *> x <* spaces | |||
| sep :: Parser b -> Parser a -> Parser [a] | |||
| sep s c = sep1 s c <|> return [] | |||
| sep1 :: Parser b -> Parser a -> Parser [a] | |||
| sep1 s c = do | |||
| x <- c | |||
| xs <- many $ s >> c | |||
| return $ x:xs | |||
| option :: a -> Parser a -> Parser a | |||
| option x p = p <|> return x | |||
| optionMaybe :: Parser a -> Parser (Maybe a) | |||
| optionMaybe p = option Nothing $ Just <$> p | |||
| optional :: Parser a -> Parser () | |||
| optional p = void p <|> return () | |||
| eof :: Parser () | |||
| eof = Parser go where | |||
| go (x:_) = Left $ "expected eof, got '" ++ x:"'" | |||
| go [] = Right ((), []) | |||
+ 239
- 0
static/Parser.hs.html
View File
| @ -0,0 +1,239 @@ | |||
| <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd"> | |||
| <html> | |||
| <head> | |||
| <meta http-equiv="content-type" content="text/html; charset=UTF-8"> | |||
| <title>~/Projects/blag/static/Parser.hs.html</title> | |||
| <meta name="Generator" content="Vim/7.4"> | |||
| <meta name="plugin-version" content="vim7.4_v2"> | |||
| <meta name="syntax" content="haskell"> | |||
| <meta name="settings" content="use_css,pre_wrap,no_foldcolumn,expand_tabs,prevent_copy=t"> | |||
| <meta name="colorscheme" content="onedark"> | |||
| <style type="text/css"> | |||
| <!-- | |||
| pre { white-space: pre-wrap; font-family: 'Iosevka', monospace; color: #ABB2BF; background-color: #282C34; } | |||
| body { font-family: 'Iosevka', monospace; color: #ABB2BF; background-color: #282C34; } | |||
| * { font-size: 1em; } | |||
| input { border: none; margin: 0; padding: 0; font-family: 'Iosevka', monospace; } | |||
| input[size='1'] { width: 1em; width: 1ch; } | |||
| input[size='2'] { width: 2em; width: 2ch; } | |||
| input[size='3'] { width: 3em; width: 3ch; } | |||
| input[size='4'] { width: 4em; width: 4ch; } | |||
| input[size='5'] { width: 5em; width: 5ch; } | |||
| input[size='6'] { width: 6em; width: 6ch; } | |||
| input[size='7'] { width: 7em; width: 7ch; } | |||
| input[size='8'] { width: 8em; width: 8ch; } | |||
| input[size='9'] { width: 9em; width: 9ch; } | |||
| input[size='10'] { width: 10em; width: 10ch; } | |||
| input[size='11'] { width: 11em; width: 11ch; } | |||
| input[size='12'] { width: 12em; width: 12ch; } | |||
| input[size='13'] { width: 13em; width: 13ch; } | |||
| input[size='14'] { width: 14em; width: 14ch; } | |||
| input[size='15'] { width: 15em; width: 15ch; } | |||
| input[size='16'] { width: 16em; width: 16ch; } | |||
| input[size='17'] { width: 17em; width: 17ch; } | |||
| input[size='18'] { width: 18em; width: 18ch; } | |||
| input[size='19'] { width: 19em; width: 19ch; } | |||
| input[size='20'] { width: 20em; width: 20ch; } | |||
| #oneCharWidth, #oneEmWidth, #oneInputWidth { padding: 0; margin: 0; position: absolute; left: -999999px; visibility: hidden; } | |||
| .em5 input[size='1'] { width: 0.05em; } .em5 input[size='2'] { width: 0.1em; } .em5 input[size='3'] { width: 0.15em; } .em5 input[size='4'] { width: 0.2em; } .em5 input[size='5'] { width: 0.25em; } .em5 input[size='6'] { width: 0.3em; } .em5 input[size='7'] { width: 0.35em; } .em5 input[size='8'] { width: 0.4em; } .em5 input[size='9'] { width: 0.45em; } .em5 input[size='10'] { width: 0.5em; } .em5 input[size='11'] { width: 0.55em; } .em5 input[size='12'] { width: 0.6em; } .em5 input[size='13'] { width: 0.65em; } .em5 input[size='14'] { width: 0.7em; } .em5 input[size='15'] { width: 0.75em; } .em5 input[size='16'] { width: 0.8em; } .em5 input[size='17'] { width: 0.85em; } .em5 input[size='18'] { width: 0.9em; } .em5 input[size='19'] { width: 0.95em; } .em5 input[size='20'] { width: 1.0em; } | |||
| .em10 input[size='1'] { width: 0.1em; } .em10 input[size='2'] { width: 0.2em; } .em10 input[size='3'] { width: 0.3em; } .em10 input[size='4'] { width: 0.4em; } .em10 input[size='5'] { width: 0.5em; } .em10 input[size='6'] { width: 0.6em; } .em10 input[size='7'] { width: 0.7em; } .em10 input[size='8'] { width: 0.8em; } .em10 input[size='9'] { width: 0.9em; } .em10 input[size='10'] { width: 1.0em; } .em10 input[size='11'] { width: 1.1em; } .em10 input[size='12'] { width: 1.2em; } .em10 input[size='13'] { width: 1.3em; } .em10 input[size='14'] { width: 1.4em; } .em10 input[size='15'] { width: 1.5em; } .em10 input[size='16'] { width: 1.6em; } .em10 input[size='17'] { width: 1.7em; } .em10 input[size='18'] { width: 1.8em; } .em10 input[size='19'] { width: 1.9em; } .em10 input[size='20'] { width: 2.0em; } | |||
| .em15 input[size='1'] { width: 0.15em; } .em15 input[size='2'] { width: 0.3em; } .em15 input[size='3'] { width: 0.45em; } .em15 input[size='4'] { width: 0.6em; } .em15 input[size='5'] { width: 0.75em; } .em15 input[size='6'] { width: 0.9em; } .em15 input[size='7'] { width: 1.05em; } .em15 input[size='8'] { width: 1.2em; } .em15 input[size='9'] { width: 1.35em; } .em15 input[size='10'] { width: 1.5em; } .em15 input[size='11'] { width: 1.65em; } .em15 input[size='12'] { width: 1.8em; } .em15 input[size='13'] { width: 1.95em; } .em15 input[size='14'] { width: 2.1em; } .em15 input[size='15'] { width: 2.25em; } .em15 input[size='16'] { width: 2.4em; } .em15 input[size='17'] { width: 2.55em; } .em15 input[size='18'] { width: 2.7em; } .em15 input[size='19'] { width: 2.85em; } .em15 input[size='20'] { width: 3.0em; } | |||
| .em20 input[size='1'] { width: 0.2em; } .em20 input[size='2'] { width: 0.4em; } .em20 input[size='3'] { width: 0.6em; } .em20 input[size='4'] { width: 0.8em; } .em20 input[size='5'] { width: 1.0em; } .em20 input[size='6'] { width: 1.2em; } .em20 input[size='7'] { width: 1.4em; } .em20 input[size='8'] { width: 1.6em; } .em20 input[size='9'] { width: 1.8em; } .em20 input[size='10'] { width: 2.0em; } .em20 input[size='11'] { width: 2.2em; } .em20 input[size='12'] { width: 2.4em; } .em20 input[size='13'] { width: 2.6em; } .em20 input[size='14'] { width: 2.8em; } .em20 input[size='15'] { width: 3.0em; } .em20 input[size='16'] { width: 3.2em; } .em20 input[size='17'] { width: 3.4em; } .em20 input[size='18'] { width: 3.6em; } .em20 input[size='19'] { width: 3.8em; } .em20 input[size='20'] { width: 4.0em; } | |||
| .em25 input[size='1'] { width: 0.25em; } .em25 input[size='2'] { width: 0.5em; } .em25 input[size='3'] { width: 0.75em; } .em25 input[size='4'] { width: 1.0em; } .em25 input[size='5'] { width: 1.25em; } .em25 input[size='6'] { width: 1.5em; } .em25 input[size='7'] { width: 1.75em; } .em25 input[size='8'] { width: 2.0em; } .em25 input[size='9'] { width: 2.25em; } .em25 input[size='10'] { width: 2.5em; } .em25 input[size='11'] { width: 2.75em; } .em25 input[size='12'] { width: 3.0em; } .em25 input[size='13'] { width: 3.25em; } .em25 input[size='14'] { width: 3.5em; } .em25 input[size='15'] { width: 3.75em; } .em25 input[size='16'] { width: 4.0em; } .em25 input[size='17'] { width: 4.25em; } .em25 input[size='18'] { width: 4.5em; } .em25 input[size='19'] { width: 4.75em; } .em25 input[size='20'] { width: 5.0em; } | |||
| .em30 input[size='1'] { width: 0.3em; } .em30 input[size='2'] { width: 0.6em; } .em30 input[size='3'] { width: 0.9em; } .em30 input[size='4'] { width: 1.2em; } .em30 input[size='5'] { width: 1.5em; } .em30 input[size='6'] { width: 1.8em; } .em30 input[size='7'] { width: 2.1em; } .em30 input[size='8'] { width: 2.4em; } .em30 input[size='9'] { width: 2.7em; } .em30 input[size='10'] { width: 3.0em; } .em30 input[size='11'] { width: 3.3em; } .em30 input[size='12'] { width: 3.6em; } .em30 input[size='13'] { width: 3.9em; } .em30 input[size='14'] { width: 4.2em; } .em30 input[size='15'] { width: 4.5em; } .em30 input[size='16'] { width: 4.8em; } .em30 input[size='17'] { width: 5.1em; } .em30 input[size='18'] { width: 5.4em; } .em30 input[size='19'] { width: 5.7em; } .em30 input[size='20'] { width: 6.0em; } | |||
| .em35 input[size='1'] { width: 0.35em; } .em35 input[size='2'] { width: 0.7em; } .em35 input[size='3'] { width: 1.05em; } .em35 input[size='4'] { width: 1.4em; } .em35 input[size='5'] { width: 1.75em; } .em35 input[size='6'] { width: 2.1em; } .em35 input[size='7'] { width: 2.45em; } .em35 input[size='8'] { width: 2.8em; } .em35 input[size='9'] { width: 3.15em; } .em35 input[size='10'] { width: 3.5em; } .em35 input[size='11'] { width: 3.85em; } .em35 input[size='12'] { width: 4.2em; } .em35 input[size='13'] { width: 4.55em; } .em35 input[size='14'] { width: 4.9em; } .em35 input[size='15'] { width: 5.25em; } .em35 input[size='16'] { width: 5.6em; } .em35 input[size='17'] { width: 5.95em; } .em35 input[size='18'] { width: 6.3em; } .em35 input[size='19'] { width: 6.65em; } .em35 input[size='20'] { width: 7.0em; } | |||
| .em40 input[size='1'] { width: 0.4em; } .em40 input[size='2'] { width: 0.8em; } .em40 input[size='3'] { width: 1.2em; } .em40 input[size='4'] { width: 1.6em; } .em40 input[size='5'] { width: 2.0em; } .em40 input[size='6'] { width: 2.4em; } .em40 input[size='7'] { width: 2.8em; } .em40 input[size='8'] { width: 3.2em; } .em40 input[size='9'] { width: 3.6em; } .em40 input[size='10'] { width: 4.0em; } .em40 input[size='11'] { width: 4.4em; } .em40 input[size='12'] { width: 4.8em; } .em40 input[size='13'] { width: 5.2em; } .em40 input[size='14'] { width: 5.6em; } .em40 input[size='15'] { width: 6.0em; } .em40 input[size='16'] { width: 6.4em; } .em40 input[size='17'] { width: 6.8em; } .em40 input[size='18'] { width: 7.2em; } .em40 input[size='19'] { width: 7.6em; } .em40 input[size='20'] { width: 8.0em; } | |||
| .em45 input[size='1'] { width: 0.45em; } .em45 input[size='2'] { width: 0.9em; } .em45 input[size='3'] { width: 1.35em; } .em45 input[size='4'] { width: 1.8em; } .em45 input[size='5'] { width: 2.25em; } .em45 input[size='6'] { width: 2.7em; } .em45 input[size='7'] { width: 3.15em; } .em45 input[size='8'] { width: 3.6em; } .em45 input[size='9'] { width: 4.05em; } .em45 input[size='10'] { width: 4.5em; } .em45 input[size='11'] { width: 4.95em; } .em45 input[size='12'] { width: 5.4em; } .em45 input[size='13'] { width: 5.85em; } .em45 input[size='14'] { width: 6.3em; } .em45 input[size='15'] { width: 6.75em; } .em45 input[size='16'] { width: 7.2em; } .em45 input[size='17'] { width: 7.65em; } .em45 input[size='18'] { width: 8.1em; } .em45 input[size='19'] { width: 8.55em; } .em45 input[size='20'] { width: 9.0em; } | |||
| .em50 input[size='1'] { width: 0.5em; } .em50 input[size='2'] { width: 1.0em; } .em50 input[size='3'] { width: 1.5em; } .em50 input[size='4'] { width: 2.0em; } .em50 input[size='5'] { width: 2.5em; } .em50 input[size='6'] { width: 3.0em; } .em50 input[size='7'] { width: 3.5em; } .em50 input[size='8'] { width: 4.0em; } .em50 input[size='9'] { width: 4.5em; } .em50 input[size='10'] { width: 5.0em; } .em50 input[size='11'] { width: 5.5em; } .em50 input[size='12'] { width: 6.0em; } .em50 input[size='13'] { width: 6.5em; } .em50 input[size='14'] { width: 7.0em; } .em50 input[size='15'] { width: 7.5em; } .em50 input[size='16'] { width: 8.0em; } .em50 input[size='17'] { width: 8.5em; } .em50 input[size='18'] { width: 9.0em; } .em50 input[size='19'] { width: 9.5em; } .em50 input[size='20'] { width: 10.0em; } | |||
| .em55 input[size='1'] { width: 0.55em; } .em55 input[size='2'] { width: 1.1em; } .em55 input[size='3'] { width: 1.65em; } .em55 input[size='4'] { width: 2.2em; } .em55 input[size='5'] { width: 2.75em; } .em55 input[size='6'] { width: 3.3em; } .em55 input[size='7'] { width: 3.85em; } .em55 input[size='8'] { width: 4.4em; } .em55 input[size='9'] { width: 4.95em; } .em55 input[size='10'] { width: 5.5em; } .em55 input[size='11'] { width: 6.05em; } .em55 input[size='12'] { width: 6.6em; } .em55 input[size='13'] { width: 7.15em; } .em55 input[size='14'] { width: 7.7em; } .em55 input[size='15'] { width: 8.25em; } .em55 input[size='16'] { width: 8.8em; } .em55 input[size='17'] { width: 9.35em; } .em55 input[size='18'] { width: 9.9em; } .em55 input[size='19'] { width: 10.45em; } .em55 input[size='20'] { width: 11.0em; } | |||
| .em60 input[size='1'] { width: 0.6em; } .em60 input[size='2'] { width: 1.2em; } .em60 input[size='3'] { width: 1.8em; } .em60 input[size='4'] { width: 2.4em; } .em60 input[size='5'] { width: 3.0em; } .em60 input[size='6'] { width: 3.6em; } .em60 input[size='7'] { width: 4.2em; } .em60 input[size='8'] { width: 4.8em; } .em60 input[size='9'] { width: 5.4em; } .em60 input[size='10'] { width: 6.0em; } .em60 input[size='11'] { width: 6.6em; } .em60 input[size='12'] { width: 7.2em; } .em60 input[size='13'] { width: 7.8em; } .em60 input[size='14'] { width: 8.4em; } .em60 input[size='15'] { width: 9.0em; } .em60 input[size='16'] { width: 9.6em; } .em60 input[size='17'] { width: 10.2em; } .em60 input[size='18'] { width: 10.8em; } .em60 input[size='19'] { width: 11.4em; } .em60 input[size='20'] { width: 12.0em; } | |||
| .em65 input[size='1'] { width: 0.65em; } .em65 input[size='2'] { width: 1.3em; } .em65 input[size='3'] { width: 1.95em; } .em65 input[size='4'] { width: 2.6em; } .em65 input[size='5'] { width: 3.25em; } .em65 input[size='6'] { width: 3.9em; } .em65 input[size='7'] { width: 4.55em; } .em65 input[size='8'] { width: 5.2em; } .em65 input[size='9'] { width: 5.85em; } .em65 input[size='10'] { width: 6.5em; } .em65 input[size='11'] { width: 7.15em; } .em65 input[size='12'] { width: 7.8em; } .em65 input[size='13'] { width: 8.45em; } .em65 input[size='14'] { width: 9.1em; } .em65 input[size='15'] { width: 9.75em; } .em65 input[size='16'] { width: 10.4em; } .em65 input[size='17'] { width: 11.05em; } .em65 input[size='18'] { width: 11.7em; } .em65 input[size='19'] { width: 12.35em; } .em65 input[size='20'] { width: 13.0em; } | |||
| .em70 input[size='1'] { width: 0.7em; } .em70 input[size='2'] { width: 1.4em; } .em70 input[size='3'] { width: 2.1em; } .em70 input[size='4'] { width: 2.8em; } .em70 input[size='5'] { width: 3.5em; } .em70 input[size='6'] { width: 4.2em; } .em70 input[size='7'] { width: 4.9em; } .em70 input[size='8'] { width: 5.6em; } .em70 input[size='9'] { width: 6.3em; } .em70 input[size='10'] { width: 7.0em; } .em70 input[size='11'] { width: 7.7em; } .em70 input[size='12'] { width: 8.4em; } .em70 input[size='13'] { width: 9.1em; } .em70 input[size='14'] { width: 9.8em; } .em70 input[size='15'] { width: 10.5em; } .em70 input[size='16'] { width: 11.2em; } .em70 input[size='17'] { width: 11.9em; } .em70 input[size='18'] { width: 12.6em; } .em70 input[size='19'] { width: 13.3em; } .em70 input[size='20'] { width: 14.0em; } | |||
| .em75 input[size='1'] { width: 0.75em; } .em75 input[size='2'] { width: 1.5em; } .em75 input[size='3'] { width: 2.25em; } .em75 input[size='4'] { width: 3.0em; } .em75 input[size='5'] { width: 3.75em; } .em75 input[size='6'] { width: 4.5em; } .em75 input[size='7'] { width: 5.25em; } .em75 input[size='8'] { width: 6.0em; } .em75 input[size='9'] { width: 6.75em; } .em75 input[size='10'] { width: 7.5em; } .em75 input[size='11'] { width: 8.25em; } .em75 input[size='12'] { width: 9.0em; } .em75 input[size='13'] { width: 9.75em; } .em75 input[size='14'] { width: 10.5em; } .em75 input[size='15'] { width: 11.25em; } .em75 input[size='16'] { width: 12.0em; } .em75 input[size='17'] { width: 12.75em; } .em75 input[size='18'] { width: 13.5em; } .em75 input[size='19'] { width: 14.25em; } .em75 input[size='20'] { width: 15.0em; } | |||
| .em80 input[size='1'] { width: 0.8em; } .em80 input[size='2'] { width: 1.6em; } .em80 input[size='3'] { width: 2.4em; } .em80 input[size='4'] { width: 3.2em; } .em80 input[size='5'] { width: 4.0em; } .em80 input[size='6'] { width: 4.8em; } .em80 input[size='7'] { width: 5.6em; } .em80 input[size='8'] { width: 6.4em; } .em80 input[size='9'] { width: 7.2em; } .em80 input[size='10'] { width: 8.0em; } .em80 input[size='11'] { width: 8.8em; } .em80 input[size='12'] { width: 9.6em; } .em80 input[size='13'] { width: 10.4em; } .em80 input[size='14'] { width: 11.2em; } .em80 input[size='15'] { width: 12.0em; } .em80 input[size='16'] { width: 12.8em; } .em80 input[size='17'] { width: 13.6em; } .em80 input[size='18'] { width: 14.4em; } .em80 input[size='19'] { width: 15.2em; } .em80 input[size='20'] { width: 16.0em; } | |||
| .em85 input[size='1'] { width: 0.85em; } .em85 input[size='2'] { width: 1.7em; } .em85 input[size='3'] { width: 2.55em; } .em85 input[size='4'] { width: 3.4em; } .em85 input[size='5'] { width: 4.25em; } .em85 input[size='6'] { width: 5.1em; } .em85 input[size='7'] { width: 5.95em; } .em85 input[size='8'] { width: 6.8em; } .em85 input[size='9'] { width: 7.65em; } .em85 input[size='10'] { width: 8.5em; } .em85 input[size='11'] { width: 9.35em; } .em85 input[size='12'] { width: 10.2em; } .em85 input[size='13'] { width: 11.05em; } .em85 input[size='14'] { width: 11.9em; } .em85 input[size='15'] { width: 12.75em; } .em85 input[size='16'] { width: 13.6em; } .em85 input[size='17'] { width: 14.45em; } .em85 input[size='18'] { width: 15.3em; } .em85 input[size='19'] { width: 16.15em; } .em85 input[size='20'] { width: 17.0em; } | |||
| .em90 input[size='1'] { width: 0.9em; } .em90 input[size='2'] { width: 1.8em; } .em90 input[size='3'] { width: 2.7em; } .em90 input[size='4'] { width: 3.6em; } .em90 input[size='5'] { width: 4.5em; } .em90 input[size='6'] { width: 5.4em; } .em90 input[size='7'] { width: 6.3em; } .em90 input[size='8'] { width: 7.2em; } .em90 input[size='9'] { width: 8.1em; } .em90 input[size='10'] { width: 9.0em; } .em90 input[size='11'] { width: 9.9em; } .em90 input[size='12'] { width: 10.8em; } .em90 input[size='13'] { width: 11.7em; } .em90 input[size='14'] { width: 12.6em; } .em90 input[size='15'] { width: 13.5em; } .em90 input[size='16'] { width: 14.4em; } .em90 input[size='17'] { width: 15.3em; } .em90 input[size='18'] { width: 16.2em; } .em90 input[size='19'] { width: 17.1em; } .em90 input[size='20'] { width: 18.0em; } | |||
| .em95 input[size='1'] { width: 0.95em; } .em95 input[size='2'] { width: 1.9em; } .em95 input[size='3'] { width: 2.85em; } .em95 input[size='4'] { width: 3.8em; } .em95 input[size='5'] { width: 4.75em; } .em95 input[size='6'] { width: 5.7em; } .em95 input[size='7'] { width: 6.65em; } .em95 input[size='8'] { width: 7.6em; } .em95 input[size='9'] { width: 8.55em; } .em95 input[size='10'] { width: 9.5em; } .em95 input[size='11'] { width: 10.45em; } .em95 input[size='12'] { width: 11.4em; } .em95 input[size='13'] { width: 12.35em; } .em95 input[size='14'] { width: 13.3em; } .em95 input[size='15'] { width: 14.25em; } .em95 input[size='16'] { width: 15.2em; } .em95 input[size='17'] { width: 16.15em; } .em95 input[size='18'] { width: 17.1em; } .em95 input[size='19'] { width: 18.05em; } .em95 input[size='20'] { width: 19.0em; } | |||
| .em100 input[size='1'] { width: 1.0em; } .em100 input[size='2'] { width: 2.0em; } .em100 input[size='3'] { width: 3.0em; } .em100 input[size='4'] { width: 4.0em; } .em100 input[size='5'] { width: 5.0em; } .em100 input[size='6'] { width: 6.0em; } .em100 input[size='7'] { width: 7.0em; } .em100 input[size='8'] { width: 8.0em; } .em100 input[size='9'] { width: 9.0em; } .em100 input[size='10'] { width: 10.0em; } .em100 input[size='11'] { width: 11.0em; } .em100 input[size='12'] { width: 12.0em; } .em100 input[size='13'] { width: 13.0em; } .em100 input[size='14'] { width: 14.0em; } .em100 input[size='15'] { width: 15.0em; } .em100 input[size='16'] { width: 16.0em; } .em100 input[size='17'] { width: 17.0em; } .em100 input[size='18'] { width: 18.0em; } .em100 input[size='19'] { width: 19.0em; } .em100 input[size='20'] { width: 20.0em; } | |||
| input.Folded { cursor: default; } | |||
| .Conditional { color: #C678DD; } | |||
| .Operator { color: #C678DD; } | |||
| .Keyword { color: #E06C75; } | |||
| .String { color: #98C379; } | |||
| .Identifier { color: #E06C75; } | |||
| .haskellType { color: #61AFEF; } | |||
| .Structure { color: #E5C07B; } | |||
| .Number { color: #D19A66; } | |||
| --> | |||
| </style> | |||
| <script type='text/javascript'> | |||
| <!-- | |||
| /* simulate a "ch" unit by asking the browser how big a zero character is */ | |||
| function FixCharWidth() { | |||
| /* get the hidden element which gives the width of a single character */ | |||
| var goodWidth = document.getElementById("oneCharWidth").clientWidth; | |||
| /* get all input elements, we'll filter on class later */ | |||
| var inputTags = document.getElementsByTagName("input"); | |||
| var ratio = 5; | |||
| var inputWidth = document.getElementById("oneInputWidth").clientWidth; | |||
| var emWidth = document.getElementById("oneEmWidth").clientWidth; | |||
| if (inputWidth > goodWidth) { | |||
| while (ratio < 100*goodWidth/emWidth && ratio < 100) { | |||
| ratio += 5; | |||
| } | |||
| document.getElementById("vimCodeElement").className = "em"+ratio; | |||
| } | |||
| } | |||
| --> | |||
| </script> | |||
| </head> | |||
| <body onload='FixCharWidth();'> | |||
| <!-- hidden divs used by javascript to get the width of a char --> | |||
| <div id='oneCharWidth'>0</div> | |||
| <div id='oneInputWidth'><input size='1' value='0'></div> | |||
| <div id='oneEmWidth' style='width: 1em;'></div> | |||
| <pre id='vimCodeElement'> | |||
| {-# LANGUAGE LambdaCase #-} | |||
| <span class="Structure">module</span> <span class="haskellType">Parser</span> | |||
| ( <span class="haskellType">Parser</span>() | |||
| , <span class="Structure">module</span> <span class="haskellType">X</span> | |||
| , <span class="haskellType">Parser</span><span class="Operator">.</span>any | |||
| , satisfy | |||
| , string | |||
| , digit | |||
| , number | |||
| , spaces | |||
| , reserved | |||
| , lexeme | |||
| , (<span class="Operator"><?></span>) | |||
| , runParser | |||
| , between ) <span class="Structure">where</span> | |||
| <span class="Structure">import</span> <span class="haskellType">Control</span><span class="Operator">.</span><span class="haskellType">Applicative</span> <span class="Structure">as</span> <span class="haskellType">X</span> | |||
| <span class="Structure">import</span> <span class="haskellType">Control</span><span class="Operator">.</span><span class="haskellType">Monad</span> <span class="Structure">as</span> <span class="haskellType">X</span> | |||
| <span class="Structure">import</span> <span class="haskellType">Data</span><span class="Operator">.</span><span class="haskellType">Char</span> | |||
| <span class="Structure">newtype</span> <span class="haskellType">Parser</span> a | |||
| <span class="Operator">=</span> <span class="haskellType">Parser</span> { <span class="Identifier">parse</span> <span class="Operator">::</span> <span class="haskellType">String</span> <span class="Operator">-></span> <span class="haskellType">Either</span> <span class="haskellType">String</span> (a, <span class="haskellType">String</span>) } | |||
| <span class="Identifier">runParser</span> <span class="Operator">::</span> <span class="haskellType">Parser</span> a <span class="Operator">-></span> <span class="haskellType">String</span> <span class="Operator">-></span> <span class="haskellType">Either</span> <span class="haskellType">String</span> a | |||
| runParser (<span class="haskellType">Parser</span> p) s <span class="Operator">=</span> fst <span class="Operator"><$></span> p s | |||
| (<span class="Operator"><?></span>) <span class="Operator">::</span> <span class="haskellType">Parser</span> a <span class="Operator">-></span> <span class="haskellType">String</span> <span class="Operator">-></span> <span class="haskellType">Parser</span> a | |||
| p <span class="Operator"><?></span> err <span class="Operator">=</span> p <span class="Operator"><|></span> fail err | |||
| <span class="Keyword">infixl</span> <span class="Number">2</span> <span class="Operator"><?></span> | |||
| <span class="Structure">instance</span> <span class="haskellType">Functor</span> <span class="haskellType">Parser</span> <span class="Structure">where</span> | |||
| fn <span class="Operator">`fmap`</span> (<span class="haskellType">Parser</span> p) <span class="Operator">=</span> <span class="haskellType">Parser</span> go <span class="Structure">where</span> | |||
| go st <span class="Operator">=</span> <span class="Keyword">case</span> p st <span class="Keyword">of</span> | |||
| <span class="haskellType">Left</span> e <span class="Operator">-></span> <span class="haskellType">Left</span> e | |||
| <span class="haskellType">Right</span> (res, str') <span class="Operator">-></span> <span class="haskellType">Right</span> (fn res, str') | |||
| <span class="Structure">instance</span> <span class="haskellType">Applicative</span> <span class="haskellType">Parser</span> <span class="Structure">where</span> | |||
| pure x <span class="Operator">=</span> <span class="haskellType">Parser</span> <span class="Operator">$</span> <span class="Operator">\</span>str <span class="Operator">-></span> <span class="haskellType">Right</span> (x, str) | |||
| (<span class="haskellType">Parser</span> p) <span class="Operator"><*></span> (<span class="haskellType">Parser</span> p') <span class="Operator">=</span> <span class="haskellType">Parser</span> go <span class="Structure">where</span> | |||
| go st <span class="Operator">=</span> <span class="Keyword">case</span> p st <span class="Keyword">of</span> | |||
| <span class="haskellType">Left</span> e <span class="Operator">-></span> <span class="haskellType">Left</span> e | |||
| <span class="haskellType">Right</span> (fn, st') <span class="Operator">-></span> <span class="Keyword">case</span> p' st' <span class="Keyword">of</span> | |||
| <span class="haskellType">Left</span> e' <span class="Operator">-></span> <span class="haskellType">Left</span> e' | |||
| <span class="haskellType">Right</span> (v, st'') <span class="Operator">-></span> <span class="haskellType">Right</span> (fn v, st'') | |||
| <span class="Structure">instance</span> <span class="haskellType">Alternative</span> <span class="haskellType">Parser</span> <span class="Structure">where</span> | |||
| empty <span class="Operator">=</span> fail <span class="String">"nothing"</span> | |||
| (<span class="haskellType">Parser</span> p) <span class="Operator"><|></span> (<span class="haskellType">Parser</span> p') <span class="Operator">=</span> <span class="haskellType">Parser</span> go <span class="Structure">where</span> | |||
| go st <span class="Operator">=</span> <span class="Keyword">case</span> p st <span class="Keyword">of</span> | |||
| <span class="haskellType">Left</span> <span class="Operator">_</span> <span class="Operator">-></span> p' st | |||
| <span class="haskellType">Right</span> x <span class="Operator">-></span> <span class="haskellType">Right</span> x | |||
| <span class="Structure">instance</span> <span class="haskellType">Monad</span> <span class="haskellType">Parser</span> <span class="Structure">where</span> | |||
| return <span class="Operator">=</span> pure | |||
| (<span class="haskellType">Parser</span> p) <span class="Operator">>>=</span> f <span class="Operator">=</span> <span class="haskellType">Parser</span> go <span class="Structure">where</span> | |||
| go s <span class="Operator">=</span> <span class="Keyword">case</span> p s <span class="Keyword">of</span> | |||
| <span class="haskellType">Left</span> e <span class="Operator">-></span> <span class="haskellType">Left</span> e | |||
| <span class="haskellType">Right</span> (x, s') <span class="Operator">-></span> parse (f x) s' | |||
| fail m <span class="Operator">=</span> <span class="haskellType">Parser</span> go <span class="Structure">where</span> | |||
| go <span class="Operator">=</span> <span class="haskellType">Left</span> <span class="Operator">.</span> go' | |||
| go' [] <span class="Operator">=</span> <span class="String">"expected "</span> <span class="Operator">++</span> m <span class="Operator">++</span> <span class="String">", got to the end of stream"</span> | |||
| go' (x<span class="Operator">:</span>xs) <span class="Operator">=</span> <span class="String">"expected "</span> <span class="Operator">++</span> m <span class="Operator">++</span> <span class="String">", got '"</span> <span class="Operator">++</span> x<span class="Operator">:</span><span class="String">"'"</span> | |||
| <span class="Identifier">any</span> <span class="Operator">::</span> <span class="haskellType">Parser</span> <span class="haskellType">Char</span> | |||
| any <span class="Operator">=</span> <span class="haskellType">Parser</span> go <span class="Structure">where</span> | |||
| go [] <span class="Operator">=</span> <span class="haskellType">Left</span> <span class="String">"any: end of file"</span> | |||
| go (x<span class="Operator">:</span>xs) <span class="Operator">=</span> <span class="haskellType">Right</span> (x,xs) | |||
| <span class="Identifier">satisfy</span> <span class="Operator">::</span> (<span class="haskellType">Char</span> <span class="Operator">-></span> <span class="haskellType">Bool</span>) <span class="Operator">-></span> <span class="haskellType">Parser</span> <span class="haskellType">Char</span> | |||
| satisfy f <span class="Operator">=</span> <span class="Keyword">do</span> x <span class="Operator"><-</span> <span class="haskellType">Parser</span><span class="Operator">.</span>any | |||
| <span class="Conditional">if</span> f x | |||
| <span class="Conditional">then</span> return x | |||
| <span class="Conditional">else</span> fail <span class="String">"a solution to the function"</span> | |||
| <span class="Identifier">char</span> <span class="Operator">::</span> <span class="haskellType">Char</span> <span class="Operator">-></span> <span class="haskellType">Parser</span> <span class="haskellType">Char</span> | |||
| char c <span class="Operator">=</span> satisfy (c <span class="Operator">==</span>) <span class="Operator"><?></span> <span class="String">"literal "</span> <span class="Operator">++</span> [c] | |||
| <span class="Identifier">oneOf</span> <span class="Operator">::</span> <span class="haskellType">String</span> <span class="Operator">-></span> <span class="haskellType">Parser</span> <span class="haskellType">Char</span> | |||
| oneOf s <span class="Operator">=</span> satisfy (<span class="Operator">`elem`</span> s) <span class="Operator"><?></span> <span class="String">"one of '"</span> <span class="Operator">++</span> s <span class="Operator">++</span> <span class="String">"'"</span> | |||
| <span class="Identifier">string</span> <span class="Operator">::</span> <span class="haskellType">String</span> <span class="Operator">-></span> <span class="haskellType">Parser</span> <span class="haskellType">String</span> | |||
| string [] <span class="Operator">=</span> return [] | |||
| string (x<span class="Operator">:</span>xs) <span class="Operator">=</span> <span class="Keyword">do</span> char x | |||
| string xs | |||
| return <span class="Operator">$</span> x<span class="Operator">:</span>xs | |||
| <span class="Identifier">natural</span> <span class="Operator">::</span> <span class="haskellType">Parser</span> <span class="haskellType">Integer</span> | |||
| natural <span class="Operator">=</span> read <span class="Operator"><$></span> some (satisfy isDigit) | |||
| <span class="Identifier">lexeme</span> <span class="Operator">::</span> <span class="haskellType">Parser</span> a <span class="Operator">-></span> <span class="haskellType">Parser</span> a | |||
| lexeme <span class="Operator">=</span> (<span class="Operator"><*</span> spaces) | |||
| <span class="Identifier">reserved</span> <span class="Operator">::</span> <span class="haskellType">String</span> <span class="Operator">-></span> <span class="haskellType">Parser</span> <span class="haskellType">String</span> | |||
| reserved <span class="Operator">=</span> lexeme <span class="Operator">.</span> string | |||
| <span class="Identifier">spaces</span> <span class="Operator">::</span> <span class="haskellType">Parser</span> <span class="haskellType">String</span> | |||
| spaces <span class="Operator">=</span> many <span class="Operator">$</span> oneOf <span class="String">" \n\r"</span> | |||
| <span class="Identifier">digit</span> <span class="Operator">::</span> <span class="haskellType">Parser</span> <span class="haskellType">Char</span> | |||
| digit <span class="Operator">=</span> satisfy isDigit | |||
| <span class="Identifier">number</span> <span class="Operator">::</span> <span class="haskellType">Parser</span> <span class="haskellType">Int</span> | |||
| number <span class="Operator">=</span> <span class="Keyword">do</span> | |||
| s <span class="Operator"><-</span> string <span class="String">"-"</span> <span class="Operator"><|></span> empty | |||
| cs <span class="Operator"><-</span> some digit | |||
| return <span class="Operator">$</span> read (s <span class="Operator">++</span> cs) | |||
| <span class="Identifier">between</span> <span class="Operator">::</span> <span class="haskellType">Parser</span> b <span class="Operator">-></span> <span class="haskellType">Parser</span> c <span class="Operator">-></span> <span class="haskellType">Parser</span> a <span class="Operator">-></span> <span class="haskellType">Parser</span> a | |||
| between o c x <span class="Operator">=</span> o <span class="Operator">*></span> x <span class="Operator"><*</span> c | |||
| <span class="Identifier">contents</span> <span class="Operator">::</span> <span class="haskellType">Parser</span> a <span class="Operator">-></span> <span class="haskellType">Parser</span> a | |||
| contents x <span class="Operator">=</span> spaces <span class="Operator">*></span> x <span class="Operator"><*</span> spaces | |||
| <span class="Identifier">sep</span> <span class="Operator">::</span> <span class="haskellType">Parser</span> b <span class="Operator">-></span> <span class="haskellType">Parser</span> a <span class="Operator">-></span> <span class="haskellType">Parser</span> [a] | |||
| sep s c <span class="Operator">=</span> sep1 s c <span class="Operator"><|></span> return [] | |||
| <span class="Identifier">sep1</span> <span class="Operator">::</span> <span class="haskellType">Parser</span> b <span class="Operator">-></span> <span class="haskellType">Parser</span> a <span class="Operator">-></span> <span class="haskellType">Parser</span> [a] | |||
| sep1 s c <span class="Operator">=</span> <span class="Keyword">do</span> x <span class="Operator"><-</span> c | |||
| xs <span class="Operator"><-</span> many <span class="Operator">$</span> s <span class="Operator">>></span> c | |||
| return <span class="Operator">$</span> x<span class="Operator">:</span>xs | |||
| <span class="Identifier">option</span> <span class="Operator">::</span> a <span class="Operator">-></span> <span class="haskellType">Parser</span> a <span class="Operator">-></span> <span class="haskellType">Parser</span> a | |||
| option x p <span class="Operator">=</span> p <span class="Operator"><|></span> return x | |||
| <span class="Identifier">optionMaybe</span> <span class="Operator">::</span> <span class="haskellType">Parser</span> a <span class="Operator">-></span> <span class="haskellType">Parser</span> (<span class="haskellType">Maybe</span> a) | |||
| optionMaybe p <span class="Operator">=</span> option <span class="haskellType">Nothing</span> <span class="Operator">$</span> <span class="haskellType">Just</span> <span class="Operator"><$></span> p | |||
| <span class="Identifier">optional</span> <span class="Operator">::</span> <span class="haskellType">Parser</span> a <span class="Operator">-></span> <span class="haskellType">Parser</span> () | |||
| optional p <span class="Operator">=</span> void p <span class="Operator"><|></span> return () | |||
| <span class="Identifier">eof</span> <span class="Operator">::</span> <span class="haskellType">Parser</span> () | |||
| eof <span class="Operator">=</span> <span class="haskellType">Parser</span> go <span class="Structure">where</span> | |||
| go (x<span class="Operator">:_</span>) <span class="Operator">=</span> <span class="haskellType">Left</span> <span class="Operator">$</span> <span class="String">"expected eof, got '"</span> <span class="Operator">++</span> x<span class="Operator">:</span><span class="String">"'"</span> | |||
| go [] <span class="Operator">=</span> <span class="haskellType">Right</span> ((), []) | |||
| </pre> | |||
| </body> | |||
| </html> | |||
| <!-- vim: set foldmethod=manual : --> | |||
+ 10
- 0
static/default.css
View File
| @ -0,0 +1,10 @@ | |||
| body{color:black;font-size:16px;margin:0px auto 0px | |||
| auto;width:80%;font-family:Fira Sans, sans-serif}div#header{border-bottom:2px | |||
| solid black;margin-bottom:30px;padding:12px 0px 12px 0px}div#logo | |||
| a{color:black;float:left;font-size:18px;font-weight:bold;font-family:Iosevka, | |||
| Iosevka Term, Fira Mono, Inconsolata, monospace;text-decoration:none}div > | |||
| span.kw{color:#007020}div > span.type{color:#902000}div#header | |||
| #navigation{text-align:right}div#header #navigation | |||
| a{color:black;font-size:18px;font-weight:bold;margin-left:12px;text-decoration:none;text-transform:uppercase}div#footer{border-top:solid | |||
| 2px black;color:#555;font-size:12px;margin-top:30px;padding:12px 0px 12px | |||
| 0px;text-align:right}div#content{text-align:justify;text-justify:inter-word}h1{font-size:24px}h2{font-size:20px}div.info{color:#555;font-size:14px;font-style:italic} | |||
+ 100
- 0
static/demorgan-1.ml.html
View File
| @ -0,0 +1,100 @@ | |||
| <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd"> | |||
| <html> | |||
| <head> | |||
| <meta http-equiv="content-type" content="text/html; charset=UTF-8"> | |||
| <title>~/Projects/blag/demorgan-1.ml.html</title> | |||
| <meta name="Generator" content="Vim/8.0"> | |||
| <meta name="plugin-version" content="vim8.1_v1"> | |||
| <meta name="syntax" content="amulet"> | |||
| <meta name="settings" content="use_css,pre_wrap,no_foldcolumn,expand_tabs,prevent_copy=t"> | |||
| <meta name="colorscheme" content="onedark"> | |||
| <style type="text/css"> | |||
| <!-- | |||
| pre { white-space: pre-wrap; font-family: 'Iosevka','Iosevka Term', monospace; color: #ABB2BF; background-color: #282C34; } | |||
| body { font-family: 'Iosevka','Iosevka Term', monospace; color: #ABB2BF; background-color: #282C34; } | |||
| * { font-size: 1em; } | |||
| input { border: none; margin: 0; padding: 0; font-family: 'Iosevka','Iosevka Term', monospace; } | |||
| input[size='1'] { width: 1em; width: 1ch; } | |||
| input[size='2'] { width: 2em; width: 2ch; } | |||
| input[size='3'] { width: 3em; width: 3ch; } | |||
| input[size='4'] { width: 4em; width: 4ch; } | |||
| input[size='5'] { width: 5em; width: 5ch; } | |||
| input[size='6'] { width: 6em; width: 6ch; } | |||
| input[size='7'] { width: 7em; width: 7ch; } | |||
| input[size='8'] { width: 8em; width: 8ch; } | |||
| input[size='9'] { width: 9em; width: 9ch; } | |||
| input[size='10'] { width: 10em; width: 10ch; } | |||
| input[size='11'] { width: 11em; width: 11ch; } | |||
| input[size='12'] { width: 12em; width: 12ch; } | |||
| input[size='13'] { width: 13em; width: 13ch; } | |||
| input[size='14'] { width: 14em; width: 14ch; } | |||
| input[size='15'] { width: 15em; width: 15ch; } | |||
| input[size='16'] { width: 16em; width: 16ch; } | |||
| input[size='17'] { width: 17em; width: 17ch; } | |||
| input[size='18'] { width: 18em; width: 18ch; } | |||
| input[size='19'] { width: 19em; width: 19ch; } | |||
| input[size='20'] { width: 20em; width: 20ch; } | |||
| #oneCharWidth, #oneEmWidth, #oneInputWidth { padding: 0; margin: 0; position: absolute; left: -999999px; visibility: hidden; } | |||
| .em5 input[size='1'] { width: 0.05em; } .em5 input[size='2'] { width: 0.1em; } .em5 input[size='3'] { width: 0.15em; } .em5 input[size='4'] { width: 0.2em; } .em5 input[size='5'] { width: 0.25em; } .em5 input[size='6'] { width: 0.3em; } .em5 input[size='7'] { width: 0.35em; } .em5 input[size='8'] { width: 0.4em; } .em5 input[size='9'] { width: 0.45em; } .em5 input[size='10'] { width: 0.5em; } .em5 input[size='11'] { width: 0.55em; } .em5 input[size='12'] { width: 0.6em; } .em5 input[size='13'] { width: 0.65em; } .em5 input[size='14'] { width: 0.7em; } .em5 input[size='15'] { width: 0.75em; } .em5 input[size='16'] { width: 0.8em; } .em5 input[size='17'] { width: 0.85em; } .em5 input[size='18'] { width: 0.9em; } .em5 input[size='19'] { width: 0.95em; } .em5 input[size='20'] { width: 1.0em; } | |||
| .em10 input[size='1'] { width: 0.1em; } .em10 input[size='2'] { width: 0.2em; } .em10 input[size='3'] { width: 0.3em; } .em10 input[size='4'] { width: 0.4em; } .em10 input[size='5'] { width: 0.5em; } .em10 input[size='6'] { width: 0.6em; } .em10 input[size='7'] { width: 0.7em; } .em10 input[size='8'] { width: 0.8em; } .em10 input[size='9'] { width: 0.9em; } .em10 input[size='10'] { width: 1.0em; } .em10 input[size='11'] { width: 1.1em; } .em10 input[size='12'] { width: 1.2em; } .em10 input[size='13'] { width: 1.3em; } .em10 input[size='14'] { width: 1.4em; } .em10 input[size='15'] { width: 1.5em; } .em10 input[size='16'] { width: 1.6em; } .em10 input[size='17'] { width: 1.7em; } .em10 input[size='18'] { width: 1.8em; } .em10 input[size='19'] { width: 1.9em; } .em10 input[size='20'] { width: 2.0em; } | |||
| .em15 input[size='1'] { width: 0.15em; } .em15 input[size='2'] { width: 0.3em; } .em15 input[size='3'] { width: 0.45em; } .em15 input[size='4'] { width: 0.6em; } .em15 input[size='5'] { width: 0.75em; } .em15 input[size='6'] { width: 0.9em; } .em15 input[size='7'] { width: 1.05em; } .em15 input[size='8'] { width: 1.2em; } .em15 input[size='9'] { width: 1.35em; } .em15 input[size='10'] { width: 1.5em; } .em15 input[size='11'] { width: 1.65em; } .em15 input[size='12'] { width: 1.8em; } .em15 input[size='13'] { width: 1.95em; } .em15 input[size='14'] { width: 2.1em; } .em15 input[size='15'] { width: 2.25em; } .em15 input[size='16'] { width: 2.4em; } .em15 input[size='17'] { width: 2.55em; } .em15 input[size='18'] { width: 2.7em; } .em15 input[size='19'] { width: 2.85em; } .em15 input[size='20'] { width: 3.0em; } | |||
| .em20 input[size='1'] { width: 0.2em; } .em20 input[size='2'] { width: 0.4em; } .em20 input[size='3'] { width: 0.6em; } .em20 input[size='4'] { width: 0.8em; } .em20 input[size='5'] { width: 1.0em; } .em20 input[size='6'] { width: 1.2em; } .em20 input[size='7'] { width: 1.4em; } .em20 input[size='8'] { width: 1.6em; } .em20 input[size='9'] { width: 1.8em; } .em20 input[size='10'] { width: 2.0em; } .em20 input[size='11'] { width: 2.2em; } .em20 input[size='12'] { width: 2.4em; } .em20 input[size='13'] { width: 2.6em; } .em20 input[size='14'] { width: 2.8em; } .em20 input[size='15'] { width: 3.0em; } .em20 input[size='16'] { width: 3.2em; } .em20 input[size='17'] { width: 3.4em; } .em20 input[size='18'] { width: 3.6em; } .em20 input[size='19'] { width: 3.8em; } .em20 input[size='20'] { width: 4.0em; } | |||
| .em25 input[size='1'] { width: 0.25em; } .em25 input[size='2'] { width: 0.5em; } .em25 input[size='3'] { width: 0.75em; } .em25 input[size='4'] { width: 1.0em; } .em25 input[size='5'] { width: 1.25em; } .em25 input[size='6'] { width: 1.5em; } .em25 input[size='7'] { width: 1.75em; } .em25 input[size='8'] { width: 2.0em; } .em25 input[size='9'] { width: 2.25em; } .em25 input[size='10'] { width: 2.5em; } .em25 input[size='11'] { width: 2.75em; } .em25 input[size='12'] { width: 3.0em; } .em25 input[size='13'] { width: 3.25em; } .em25 input[size='14'] { width: 3.5em; } .em25 input[size='15'] { width: 3.75em; } .em25 input[size='16'] { width: 4.0em; } .em25 input[size='17'] { width: 4.25em; } .em25 input[size='18'] { width: 4.5em; } .em25 input[size='19'] { width: 4.75em; } .em25 input[size='20'] { width: 5.0em; } | |||
| .em30 input[size='1'] { width: 0.3em; } .em30 input[size='2'] { width: 0.6em; } .em30 input[size='3'] { width: 0.9em; } .em30 input[size='4'] { width: 1.2em; } .em30 input[size='5'] { width: 1.5em; } .em30 input[size='6'] { width: 1.8em; } .em30 input[size='7'] { width: 2.1em; } .em30 input[size='8'] { width: 2.4em; } .em30 input[size='9'] { width: 2.7em; } .em30 input[size='10'] { width: 3.0em; } .em30 input[size='11'] { width: 3.3em; } .em30 input[size='12'] { width: 3.6em; } .em30 input[size='13'] { width: 3.9em; } .em30 input[size='14'] { width: 4.2em; } .em30 input[size='15'] { width: 4.5em; } .em30 input[size='16'] { width: 4.8em; } .em30 input[size='17'] { width: 5.1em; } .em30 input[size='18'] { width: 5.4em; } .em30 input[size='19'] { width: 5.7em; } .em30 input[size='20'] { width: 6.0em; } | |||
| .em35 input[size='1'] { width: 0.35em; } .em35 input[size='2'] { width: 0.7em; } .em35 input[size='3'] { width: 1.05em; } .em35 input[size='4'] { width: 1.4em; } .em35 input[size='5'] { width: 1.75em; } .em35 input[size='6'] { width: 2.1em; } .em35 input[size='7'] { width: 2.45em; } .em35 input[size='8'] { width: 2.8em; } .em35 input[size='9'] { width: 3.15em; } .em35 input[size='10'] { width: 3.5em; } .em35 input[size='11'] { width: 3.85em; } .em35 input[size='12'] { width: 4.2em; } .em35 input[size='13'] { width: 4.55em; } .em35 input[size='14'] { width: 4.9em; } .em35 input[size='15'] { width: 5.25em; } .em35 input[size='16'] { width: 5.6em; } .em35 input[size='17'] { width: 5.95em; } .em35 input[size='18'] { width: 6.3em; } .em35 input[size='19'] { width: 6.65em; } .em35 input[size='20'] { width: 7.0em; } | |||
| .em40 input[size='1'] { width: 0.4em; } .em40 input[size='2'] { width: 0.8em; } .em40 input[size='3'] { width: 1.2em; } .em40 input[size='4'] { width: 1.6em; } .em40 input[size='5'] { width: 2.0em; } .em40 input[size='6'] { width: 2.4em; } .em40 input[size='7'] { width: 2.8em; } .em40 input[size='8'] { width: 3.2em; } .em40 input[size='9'] { width: 3.6em; } .em40 input[size='10'] { width: 4.0em; } .em40 input[size='11'] { width: 4.4em; } .em40 input[size='12'] { width: 4.8em; } .em40 input[size='13'] { width: 5.2em; } .em40 input[size='14'] { width: 5.6em; } .em40 input[size='15'] { width: 6.0em; } .em40 input[size='16'] { width: 6.4em; } .em40 input[size='17'] { width: 6.8em; } .em40 input[size='18'] { width: 7.2em; } .em40 input[size='19'] { width: 7.6em; } .em40 input[size='20'] { width: 8.0em; } | |||
| .em45 input[size='1'] { width: 0.45em; } .em45 input[size='2'] { width: 0.9em; } .em45 input[size='3'] { width: 1.35em; } .em45 input[size='4'] { width: 1.8em; } .em45 input[size='5'] { width: 2.25em; } .em45 input[size='6'] { width: 2.7em; } .em45 input[size='7'] { width: 3.15em; } .em45 input[size='8'] { width: 3.6em; } .em45 input[size='9'] { width: 4.05em; } .em45 input[size='10'] { width: 4.5em; } .em45 input[size='11'] { width: 4.95em; } .em45 input[size='12'] { width: 5.4em; } .em45 input[size='13'] { width: 5.85em; } .em45 input[size='14'] { width: 6.3em; } .em45 input[size='15'] { width: 6.75em; } .em45 input[size='16'] { width: 7.2em; } .em45 input[size='17'] { width: 7.65em; } .em45 input[size='18'] { width: 8.1em; } .em45 input[size='19'] { width: 8.55em; } .em45 input[size='20'] { width: 9.0em; } | |||
| .em50 input[size='1'] { width: 0.5em; } .em50 input[size='2'] { width: 1.0em; } .em50 input[size='3'] { width: 1.5em; } .em50 input[size='4'] { width: 2.0em; } .em50 input[size='5'] { width: 2.5em; } .em50 input[size='6'] { width: 3.0em; } .em50 input[size='7'] { width: 3.5em; } .em50 input[size='8'] { width: 4.0em; } .em50 input[size='9'] { width: 4.5em; } .em50 input[size='10'] { width: 5.0em; } .em50 input[size='11'] { width: 5.5em; } .em50 input[size='12'] { width: 6.0em; } .em50 input[size='13'] { width: 6.5em; } .em50 input[size='14'] { width: 7.0em; } .em50 input[size='15'] { width: 7.5em; } .em50 input[size='16'] { width: 8.0em; } .em50 input[size='17'] { width: 8.5em; } .em50 input[size='18'] { width: 9.0em; } .em50 input[size='19'] { width: 9.5em; } .em50 input[size='20'] { width: 10.0em; } | |||
| .em55 input[size='1'] { width: 0.55em; } .em55 input[size='2'] { width: 1.1em; } .em55 input[size='3'] { width: 1.65em; } .em55 input[size='4'] { width: 2.2em; } .em55 input[size='5'] { width: 2.75em; } .em55 input[size='6'] { width: 3.3em; } .em55 input[size='7'] { width: 3.85em; } .em55 input[size='8'] { width: 4.4em; } .em55 input[size='9'] { width: 4.95em; } .em55 input[size='10'] { width: 5.5em; } .em55 input[size='11'] { width: 6.05em; } .em55 input[size='12'] { width: 6.6em; } .em55 input[size='13'] { width: 7.15em; } .em55 input[size='14'] { width: 7.7em; } .em55 input[size='15'] { width: 8.25em; } .em55 input[size='16'] { width: 8.8em; } .em55 input[size='17'] { width: 9.35em; } .em55 input[size='18'] { width: 9.9em; } .em55 input[size='19'] { width: 10.45em; } .em55 input[size='20'] { width: 11.0em; } | |||
| .em60 input[size='1'] { width: 0.6em; } .em60 input[size='2'] { width: 1.2em; } .em60 input[size='3'] { width: 1.8em; } .em60 input[size='4'] { width: 2.4em; } .em60 input[size='5'] { width: 3.0em; } .em60 input[size='6'] { width: 3.6em; } .em60 input[size='7'] { width: 4.2em; } .em60 input[size='8'] { width: 4.8em; } .em60 input[size='9'] { width: 5.4em; } .em60 input[size='10'] { width: 6.0em; } .em60 input[size='11'] { width: 6.6em; } .em60 input[size='12'] { width: 7.2em; } .em60 input[size='13'] { width: 7.8em; } .em60 input[size='14'] { width: 8.4em; } .em60 input[size='15'] { width: 9.0em; } .em60 input[size='16'] { width: 9.6em; } .em60 input[size='17'] { width: 10.2em; } .em60 input[size='18'] { width: 10.8em; } .em60 input[size='19'] { width: 11.4em; } .em60 input[size='20'] { width: 12.0em; } | |||
| .em65 input[size='1'] { width: 0.65em; } .em65 input[size='2'] { width: 1.3em; } .em65 input[size='3'] { width: 1.95em; } .em65 input[size='4'] { width: 2.6em; } .em65 input[size='5'] { width: 3.25em; } .em65 input[size='6'] { width: 3.9em; } .em65 input[size='7'] { width: 4.55em; } .em65 input[size='8'] { width: 5.2em; } .em65 input[size='9'] { width: 5.85em; } .em65 input[size='10'] { width: 6.5em; } .em65 input[size='11'] { width: 7.15em; } .em65 input[size='12'] { width: 7.8em; } .em65 input[size='13'] { width: 8.45em; } .em65 input[size='14'] { width: 9.1em; } .em65 input[size='15'] { width: 9.75em; } .em65 input[size='16'] { width: 10.4em; } .em65 input[size='17'] { width: 11.05em; } .em65 input[size='18'] { width: 11.7em; } .em65 input[size='19'] { width: 12.35em; } .em65 input[size='20'] { width: 13.0em; } | |||
| .em70 input[size='1'] { width: 0.7em; } .em70 input[size='2'] { width: 1.4em; } .em70 input[size='3'] { width: 2.1em; } .em70 input[size='4'] { width: 2.8em; } .em70 input[size='5'] { width: 3.5em; } .em70 input[size='6'] { width: 4.2em; } .em70 input[size='7'] { width: 4.9em; } .em70 input[size='8'] { width: 5.6em; } .em70 input[size='9'] { width: 6.3em; } .em70 input[size='10'] { width: 7.0em; } .em70 input[size='11'] { width: 7.7em; } .em70 input[size='12'] { width: 8.4em; } .em70 input[size='13'] { width: 9.1em; } .em70 input[size='14'] { width: 9.8em; } .em70 input[size='15'] { width: 10.5em; } .em70 input[size='16'] { width: 11.2em; } .em70 input[size='17'] { width: 11.9em; } .em70 input[size='18'] { width: 12.6em; } .em70 input[size='19'] { width: 13.3em; } .em70 input[size='20'] { width: 14.0em; } | |||
| .em75 input[size='1'] { width: 0.75em; } .em75 input[size='2'] { width: 1.5em; } .em75 input[size='3'] { width: 2.25em; } .em75 input[size='4'] { width: 3.0em; } .em75 input[size='5'] { width: 3.75em; } .em75 input[size='6'] { width: 4.5em; } .em75 input[size='7'] { width: 5.25em; } .em75 input[size='8'] { width: 6.0em; } .em75 input[size='9'] { width: 6.75em; } .em75 input[size='10'] { width: 7.5em; } .em75 input[size='11'] { width: 8.25em; } .em75 input[size='12'] { width: 9.0em; } .em75 input[size='13'] { width: 9.75em; } .em75 input[size='14'] { width: 10.5em; } .em75 input[size='15'] { width: 11.25em; } .em75 input[size='16'] { width: 12.0em; } .em75 input[size='17'] { width: 12.75em; } .em75 input[size='18'] { width: 13.5em; } .em75 input[size='19'] { width: 14.25em; } .em75 input[size='20'] { width: 15.0em; } | |||
| .em80 input[size='1'] { width: 0.8em; } .em80 input[size='2'] { width: 1.6em; } .em80 input[size='3'] { width: 2.4em; } .em80 input[size='4'] { width: 3.2em; } .em80 input[size='5'] { width: 4.0em; } .em80 input[size='6'] { width: 4.8em; } .em80 input[size='7'] { width: 5.6em; } .em80 input[size='8'] { width: 6.4em; } .em80 input[size='9'] { width: 7.2em; } .em80 input[size='10'] { width: 8.0em; } .em80 input[size='11'] { width: 8.8em; } .em80 input[size='12'] { width: 9.6em; } .em80 input[size='13'] { width: 10.4em; } .em80 input[size='14'] { width: 11.2em; } .em80 input[size='15'] { width: 12.0em; } .em80 input[size='16'] { width: 12.8em; } .em80 input[size='17'] { width: 13.6em; } .em80 input[size='18'] { width: 14.4em; } .em80 input[size='19'] { width: 15.2em; } .em80 input[size='20'] { width: 16.0em; } | |||
| .em85 input[size='1'] { width: 0.85em; } .em85 input[size='2'] { width: 1.7em; } .em85 input[size='3'] { width: 2.55em; } .em85 input[size='4'] { width: 3.4em; } .em85 input[size='5'] { width: 4.25em; } .em85 input[size='6'] { width: 5.1em; } .em85 input[size='7'] { width: 5.95em; } .em85 input[size='8'] { width: 6.8em; } .em85 input[size='9'] { width: 7.65em; } .em85 input[size='10'] { width: 8.5em; } .em85 input[size='11'] { width: 9.35em; } .em85 input[size='12'] { width: 10.2em; } .em85 input[size='13'] { width: 11.05em; } .em85 input[size='14'] { width: 11.9em; } .em85 input[size='15'] { width: 12.75em; } .em85 input[size='16'] { width: 13.6em; } .em85 input[size='17'] { width: 14.45em; } .em85 input[size='18'] { width: 15.3em; } .em85 input[size='19'] { width: 16.15em; } .em85 input[size='20'] { width: 17.0em; } | |||
| .em90 input[size='1'] { width: 0.9em; } .em90 input[size='2'] { width: 1.8em; } .em90 input[size='3'] { width: 2.7em; } .em90 input[size='4'] { width: 3.6em; } .em90 input[size='5'] { width: 4.5em; } .em90 input[size='6'] { width: 5.4em; } .em90 input[size='7'] { width: 6.3em; } .em90 input[size='8'] { width: 7.2em; } .em90 input[size='9'] { width: 8.1em; } .em90 input[size='10'] { width: 9.0em; } .em90 input[size='11'] { width: 9.9em; } .em90 input[size='12'] { width: 10.8em; } .em90 input[size='13'] { width: 11.7em; } .em90 input[size='14'] { width: 12.6em; } .em90 input[size='15'] { width: 13.5em; } .em90 input[size='16'] { width: 14.4em; } .em90 input[size='17'] { width: 15.3em; } .em90 input[size='18'] { width: 16.2em; } .em90 input[size='19'] { width: 17.1em; } .em90 input[size='20'] { width: 18.0em; } | |||
| .em95 input[size='1'] { width: 0.95em; } .em95 input[size='2'] { width: 1.9em; } .em95 input[size='3'] { width: 2.85em; } .em95 input[size='4'] { width: 3.8em; } .em95 input[size='5'] { width: 4.75em; } .em95 input[size='6'] { width: 5.7em; } .em95 input[size='7'] { width: 6.65em; } .em95 input[size='8'] { width: 7.6em; } .em95 input[size='9'] { width: 8.55em; } .em95 input[size='10'] { width: 9.5em; } .em95 input[size='11'] { width: 10.45em; } .em95 input[size='12'] { width: 11.4em; } .em95 input[size='13'] { width: 12.35em; } .em95 input[size='14'] { width: 13.3em; } .em95 input[size='15'] { width: 14.25em; } .em95 input[size='16'] { width: 15.2em; } .em95 input[size='17'] { width: 16.15em; } .em95 input[size='18'] { width: 17.1em; } .em95 input[size='19'] { width: 18.05em; } .em95 input[size='20'] { width: 19.0em; } | |||
| .em100 input[size='1'] { width: 1.0em; } .em100 input[size='2'] { width: 2.0em; } .em100 input[size='3'] { width: 3.0em; } .em100 input[size='4'] { width: 4.0em; } .em100 input[size='5'] { width: 5.0em; } .em100 input[size='6'] { width: 6.0em; } .em100 input[size='7'] { width: 7.0em; } .em100 input[size='8'] { width: 8.0em; } .em100 input[size='9'] { width: 9.0em; } .em100 input[size='10'] { width: 10.0em; } .em100 input[size='11'] { width: 11.0em; } .em100 input[size='12'] { width: 12.0em; } .em100 input[size='13'] { width: 13.0em; } .em100 input[size='14'] { width: 14.0em; } .em100 input[size='15'] { width: 15.0em; } .em100 input[size='16'] { width: 16.0em; } .em100 input[size='17'] { width: 17.0em; } .em100 input[size='18'] { width: 18.0em; } .em100 input[size='19'] { width: 19.0em; } .em100 input[size='20'] { width: 20.0em; } | |||
| input.Folded { cursor: default; } | |||
| .Operator { color: #C678DD; } | |||
| .Constant { color: #56B6C2; } | |||
| .Keyword { color: #E06C75; } | |||
| --> | |||
| </style> | |||
| <script type='text/javascript'> | |||
| <!-- | |||
| /* simulate a "ch" unit by asking the browser how big a zero character is */ | |||
| function FixCharWidth() { | |||
| /* get the hidden element which gives the width of a single character */ | |||
| var goodWidth = document.getElementById("oneCharWidth").clientWidth; | |||
| /* get all input elements, we'll filter on class later */ | |||
| var inputTags = document.getElementsByTagName("input"); | |||
| var ratio = 5; | |||
| var inputWidth = document.getElementById("oneInputWidth").clientWidth; | |||
| var emWidth = document.getElementById("oneEmWidth").clientWidth; | |||
| if (inputWidth > goodWidth) { | |||
| while (ratio < 100*goodWidth/emWidth && ratio < 100) { | |||
| ratio += 5; | |||
| } | |||
| document.getElementById("vimCodeElement").className = "em"+ratio; | |||
| } | |||
| } | |||
| --> | |||
| </script> | |||
| </head> | |||
| <body onload='FixCharWidth();'> | |||
| <!-- hidden divs used by javascript to get the width of a char --> | |||
| <div id='oneCharWidth'>0</div> | |||
| <div id='oneInputWidth'><input size='1' value='0'></div> | |||
| <div id='oneEmWidth' style='width: 1em;'></div> | |||
| <pre id='vimCodeElement'> | |||
| <span class="Constant">Equiv</span> <span class="Keyword">(fun</span> <span class="Keyword">(</span><span class="Constant">Not</span> g<span class="Keyword">)</span> <span class="Keyword">-></span> <span class="Keyword">(</span><span class="Constant">Not</span> <span class="Keyword">(fun</span> b <span class="Keyword">-></span> g <span class="Keyword">(</span><span class="Constant">L</span> b<span class="Keyword">))</span><span class="Operator">,</span> <span class="Constant">Not</span> <span class="Keyword">(fun</span> c <span class="Keyword">-></span> g <span class="Keyword">(</span><span class="Constant">R</span> c<span class="Keyword">)))</span><span class="Operator">,</span> <span class="Keyword">fun</span> <span class="Keyword">((</span><span class="Constant">Not</span> h<span class="Keyword">)</span><span class="Operator">,</span> <span class="Keyword">(</span><span class="Constant">Not</span> g<span class="Keyword">))</span> <span class="Keyword">-></span> <span class="Constant">Not</span> <span class="Keyword">function</span> | |||
| <span class="Operator">|</span> <span class="Keyword">(</span><span class="Constant">L</span> y<span class="Keyword">)</span> <span class="Keyword">-></span> h y | |||
| <span class="Operator">|</span> <span class="Keyword">(</span><span class="Constant">R</span> a<span class="Keyword">)</span> <span class="Keyword">-></span> h <span class="Keyword">(</span>g a<span class="Keyword">))</span> | |||
| </pre> | |||
| </body> | |||
| </html> | |||
| <!-- vim: set foldmethod=manual : --> | |||
+ 3024
- 0
static/doom.svg
File diff suppressed because it is too large
View File
{kind=link}
+ 119
- 0
static/forth_machine.js
View File
| @ -0,0 +1,119 @@ | |||
| let draw = SVG().addTo('#forth').size('100%', '100%') | |||
| let stack_element = (container, text) => { | |||
| let group = container.group() | |||
| group.add( | |||
| container.rect() | |||
| .size(100, 25) | |||
| .stroke('#000').fill('#ddd') | |||
| .attr('stroke-width', 2)); | |||
| group.add(container.text(text).dmove((65 - text.length) / 2, -2)); | |||
| console.log(group); | |||
| return group; | |||
| } | |||
| let the_code = [ | |||
| [ 'push', 2 ], | |||
| [ 'push', 3 ], | |||
| [ 'push', 4 ], | |||
| [ 'mul' ], | |||
| [ 'add' ] | |||
| ] | |||
| let the_stack = [], pc = 0, final = false; | |||
| let stack_container = draw.nested().move(draw.width() - '10%', 0) | |||
| let code_node = document.getElementById('code'); | |||
| let push_val = (int) => { | |||
| let the_element = | |||
| stack_element(stack_container, int.toString()).move(10, 0); | |||
| the_element.animate(100, 0, 'now').move(10, 10); | |||
| the_stack.forEach(elem => elem.svg.animate(100, 0, 'now').dy(25)); | |||
| the_stack.push({ svg: the_element, val: int }); | |||
| } | |||
| let pop_val = () => { | |||
| let item = the_stack.pop() | |||
| item.svg.remove(); | |||
| the_stack.forEach(elem => elem.svg.dy(-25)); | |||
| return item.val; | |||
| } | |||
| let render_code = (code, pc) => { | |||
| while (code_node.firstChild) { | |||
| code_node.removeChild(code_node.firstChild); | |||
| } | |||
| let list = document.createElement('ul'); | |||
| list.style = 'list-style-type: none;'; | |||
| code.forEach((instruction, idx) => { | |||
| let i_type = instruction[0]; | |||
| let li = document.createElement('li'); | |||
| if (idx == pc) { | |||
| let cursor = document.createElement('span') | |||
| cursor.innerText = '> '; | |||
| cursor.classList.add('instruction-cursor'); | |||
| li.appendChild(cursor); | |||
| } | |||
| let type_field = document.createElement('span'); | |||
| type_field.innerText = i_type; | |||
| type_field.classList.add('instruction'); | |||
| li.appendChild(type_field); | |||
| for (let i = 1; i < instruction.length; i++) { | |||
| li.append(' '); | |||
| let operand_field = document.createElement('span'); | |||
| operand_field.innerText = instruction[i]; | |||
| operand_field.classList.add('operand'); | |||
| li.appendChild(operand_field); | |||
| } | |||
| list.appendChild(li); | |||
| }); | |||
| code_node.appendChild(list); | |||
| }; | |||
| let reset = () => { | |||
| the_stack.forEach(e => e.svg.remove()); | |||
| the_stack = []; | |||
| pc = 0; | |||
| final = false; | |||
| document.getElementById('step').disabled = false; | |||
| render_code(the_code, 0); | |||
| } | |||
| let step = () => { | |||
| if (!final) { | |||
| const insn = the_code[pc++]; | |||
| switch (insn[0]) { | |||
| case 'push': | |||
| push_val(insn[1]); | |||
| break; | |||
| case 'add': | |||
| if (the_stack.length < 2) { | |||
| console.error("machine error"); | |||
| document.getElementById('step').disabled = true; | |||
| } else { | |||
| let x = pop_val(), y = pop_val(); | |||
| push_val(x + y); | |||
| } | |||
| break; | |||
| case 'mul': | |||
| if (the_stack.length < 2) { | |||
| console.error("machine error"); | |||
| document.getElementById('step').disabled = true; | |||
| } else { | |||
| let x = pop_val(), y = pop_val(); | |||
| push_val(x * y); | |||
| } | |||
| break; | |||
| } | |||
| } | |||
| render_code(the_code, pc); | |||
| if (pc >= the_code.length) { | |||
| console.log("final state"); | |||
| document.getElementById('step').disabled = true; | |||
| final = true; | |||
| } | |||
| } | |||
| render_code(the_code, pc); | |||
+ 22
- 0
static/generated_code.lua
View File
| @ -0,0 +1,22 @@ | |||
| eq_3f_1 = setmetatable1(({["lookup"]=({})}), ({["__call"]=(function(temp_this, x, y) | |||
| local temp_method | |||
| local temp = temp_this["lookup"] | |||
| if temp then | |||
| local temp1 = temp[type1(x)] | |||
| if temp1 then | |||
| temp_method = temp1[type1(y)] or nil | |||
| else | |||
| temp_method = nil | |||
| end | |||
| else | |||
| temp_method = nil | |||
| end | |||
| if not temp_method then | |||
| if temp_this["default"] then | |||
| temp_method = temp_this["default"] | |||
| else | |||
| error1("No matching method to call for " .. (type1(x) .. " ") .. (type1(y) .. " ") .. "\nthere are methods to call for " .. keys1(temp_this["lookup"])) | |||
| end | |||
| end | |||
| return temp_method(x, y) | |||
| end)})) | |||
+ 124
- 0
static/generated_code.lua.html
View File
| @ -0,0 +1,124 @@ | |||
| <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd"> | |||
| <html> | |||
| <head> | |||
| <meta http-equiv="content-type" content="text/html; charset=UTF-8"> | |||
| <title>~/Projects/blag/static/generated_code.lua.html</title> | |||
| <meta name="Generator" content="Vim/7.4"> | |||
| <meta name="plugin-version" content="vim7.4_v2"> | |||
| <meta name="syntax" content="lua"> | |||
| <meta name="settings" content="use_css,pre_wrap,no_foldcolumn,expand_tabs,prevent_copy=t"> | |||
| <meta name="colorscheme" content="onedark"> | |||
| <style type="text/css"> | |||
| <!-- | |||
| pre { white-space: pre-wrap; font-family: 'Iosevka','Iosevka Term', monospace; color: #ABB2BF; background-color: #282C34; } | |||
| body { font-family: 'Iosevka','Iosevka Term', monospace; color: #ABB2BF; background-color: #282C34; } | |||
| * { font-size: 1em; } | |||
| input { border: none; margin: 0; padding: 0; font-family: 'Iosevka','Iosevka Term', monospace; } | |||
| input[size='1'] { width: 1em; width: 1ch; } | |||
| input[size='2'] { width: 2em; width: 2ch; } | |||
| input[size='3'] { width: 3em; width: 3ch; } | |||
| input[size='4'] { width: 4em; width: 4ch; } | |||
| input[size='5'] { width: 5em; width: 5ch; } | |||
| input[size='6'] { width: 6em; width: 6ch; } | |||
| input[size='7'] { width: 7em; width: 7ch; } | |||
| input[size='8'] { width: 8em; width: 8ch; } | |||
| input[size='9'] { width: 9em; width: 9ch; } | |||
| input[size='10'] { width: 10em; width: 10ch; } | |||
| input[size='11'] { width: 11em; width: 11ch; } | |||
| input[size='12'] { width: 12em; width: 12ch; } | |||
| input[size='13'] { width: 13em; width: 13ch; } | |||
| input[size='14'] { width: 14em; width: 14ch; } | |||
| input[size='15'] { width: 15em; width: 15ch; } | |||
| input[size='16'] { width: 16em; width: 16ch; } | |||
| input[size='17'] { width: 17em; width: 17ch; } | |||
| input[size='18'] { width: 18em; width: 18ch; } | |||
| input[size='19'] { width: 19em; width: 19ch; } | |||
| input[size='20'] { width: 20em; width: 20ch; } | |||
| #oneCharWidth, #oneEmWidth, #oneInputWidth { padding: 0; margin: 0; position: absolute; left: -999999px; visibility: hidden; } | |||
| .em5 input[size='1'] { width: 0.05em; } .em5 input[size='2'] { width: 0.1em; } .em5 input[size='3'] { width: 0.15em; } .em5 input[size='4'] { width: 0.2em; } .em5 input[size='5'] { width: 0.25em; } .em5 input[size='6'] { width: 0.3em; } .em5 input[size='7'] { width: 0.35em; } .em5 input[size='8'] { width: 0.4em; } .em5 input[size='9'] { width: 0.45em; } .em5 input[size='10'] { width: 0.5em; } .em5 input[size='11'] { width: 0.55em; } .em5 input[size='12'] { width: 0.6em; } .em5 input[size='13'] { width: 0.65em; } .em5 input[size='14'] { width: 0.7em; } .em5 input[size='15'] { width: 0.75em; } .em5 input[size='16'] { width: 0.8em; } .em5 input[size='17'] { width: 0.85em; } .em5 input[size='18'] { width: 0.9em; } .em5 input[size='19'] { width: 0.95em; } .em5 input[size='20'] { width: 1.0em; } | |||
| .em10 input[size='1'] { width: 0.1em; } .em10 input[size='2'] { width: 0.2em; } .em10 input[size='3'] { width: 0.3em; } .em10 input[size='4'] { width: 0.4em; } .em10 input[size='5'] { width: 0.5em; } .em10 input[size='6'] { width: 0.6em; } .em10 input[size='7'] { width: 0.7em; } .em10 input[size='8'] { width: 0.8em; } .em10 input[size='9'] { width: 0.9em; } .em10 input[size='10'] { width: 1.0em; } .em10 input[size='11'] { width: 1.1em; } .em10 input[size='12'] { width: 1.2em; } .em10 input[size='13'] { width: 1.3em; } .em10 input[size='14'] { width: 1.4em; } .em10 input[size='15'] { width: 1.5em; } .em10 input[size='16'] { width: 1.6em; } .em10 input[size='17'] { width: 1.7em; } .em10 input[size='18'] { width: 1.8em; } .em10 input[size='19'] { width: 1.9em; } .em10 input[size='20'] { width: 2.0em; } | |||
| .em15 input[size='1'] { width: 0.15em; } .em15 input[size='2'] { width: 0.3em; } .em15 input[size='3'] { width: 0.45em; } .em15 input[size='4'] { width: 0.6em; } .em15 input[size='5'] { width: 0.75em; } .em15 input[size='6'] { width: 0.9em; } .em15 input[size='7'] { width: 1.05em; } .em15 input[size='8'] { width: 1.2em; } .em15 input[size='9'] { width: 1.35em; } .em15 input[size='10'] { width: 1.5em; } .em15 input[size='11'] { width: 1.65em; } .em15 input[size='12'] { width: 1.8em; } .em15 input[size='13'] { width: 1.95em; } .em15 input[size='14'] { width: 2.1em; } .em15 input[size='15'] { width: 2.25em; } .em15 input[size='16'] { width: 2.4em; } .em15 input[size='17'] { width: 2.55em; } .em15 input[size='18'] { width: 2.7em; } .em15 input[size='19'] { width: 2.85em; } .em15 input[size='20'] { width: 3.0em; } | |||
| .em20 input[size='1'] { width: 0.2em; } .em20 input[size='2'] { width: 0.4em; } .em20 input[size='3'] { width: 0.6em; } .em20 input[size='4'] { width: 0.8em; } .em20 input[size='5'] { width: 1.0em; } .em20 input[size='6'] { width: 1.2em; } .em20 input[size='7'] { width: 1.4em; } .em20 input[size='8'] { width: 1.6em; } .em20 input[size='9'] { width: 1.8em; } .em20 input[size='10'] { width: 2.0em; } .em20 input[size='11'] { width: 2.2em; } .em20 input[size='12'] { width: 2.4em; } .em20 input[size='13'] { width: 2.6em; } .em20 input[size='14'] { width: 2.8em; } .em20 input[size='15'] { width: 3.0em; } .em20 input[size='16'] { width: 3.2em; } .em20 input[size='17'] { width: 3.4em; } .em20 input[size='18'] { width: 3.6em; } .em20 input[size='19'] { width: 3.8em; } .em20 input[size='20'] { width: 4.0em; } | |||
| .em25 input[size='1'] { width: 0.25em; } .em25 input[size='2'] { width: 0.5em; } .em25 input[size='3'] { width: 0.75em; } .em25 input[size='4'] { width: 1.0em; } .em25 input[size='5'] { width: 1.25em; } .em25 input[size='6'] { width: 1.5em; } .em25 input[size='7'] { width: 1.75em; } .em25 input[size='8'] { width: 2.0em; } .em25 input[size='9'] { width: 2.25em; } .em25 input[size='10'] { width: 2.5em; } .em25 input[size='11'] { width: 2.75em; } .em25 input[size='12'] { width: 3.0em; } .em25 input[size='13'] { width: 3.25em; } .em25 input[size='14'] { width: 3.5em; } .em25 input[size='15'] { width: 3.75em; } .em25 input[size='16'] { width: 4.0em; } .em25 input[size='17'] { width: 4.25em; } .em25 input[size='18'] { width: 4.5em; } .em25 input[size='19'] { width: 4.75em; } .em25 input[size='20'] { width: 5.0em; } | |||
| .em30 input[size='1'] { width: 0.3em; } .em30 input[size='2'] { width: 0.6em; } .em30 input[size='3'] { width: 0.9em; } .em30 input[size='4'] { width: 1.2em; } .em30 input[size='5'] { width: 1.5em; } .em30 input[size='6'] { width: 1.8em; } .em30 input[size='7'] { width: 2.1em; } .em30 input[size='8'] { width: 2.4em; } .em30 input[size='9'] { width: 2.7em; } .em30 input[size='10'] { width: 3.0em; } .em30 input[size='11'] { width: 3.3em; } .em30 input[size='12'] { width: 3.6em; } .em30 input[size='13'] { width: 3.9em; } .em30 input[size='14'] { width: 4.2em; } .em30 input[size='15'] { width: 4.5em; } .em30 input[size='16'] { width: 4.8em; } .em30 input[size='17'] { width: 5.1em; } .em30 input[size='18'] { width: 5.4em; } .em30 input[size='19'] { width: 5.7em; } .em30 input[size='20'] { width: 6.0em; } | |||
| .em35 input[size='1'] { width: 0.35em; } .em35 input[size='2'] { width: 0.7em; } .em35 input[size='3'] { width: 1.05em; } .em35 input[size='4'] { width: 1.4em; } .em35 input[size='5'] { width: 1.75em; } .em35 input[size='6'] { width: 2.1em; } .em35 input[size='7'] { width: 2.45em; } .em35 input[size='8'] { width: 2.8em; } .em35 input[size='9'] { width: 3.15em; } .em35 input[size='10'] { width: 3.5em; } .em35 input[size='11'] { width: 3.85em; } .em35 input[size='12'] { width: 4.2em; } .em35 input[size='13'] { width: 4.55em; } .em35 input[size='14'] { width: 4.9em; } .em35 input[size='15'] { width: 5.25em; } .em35 input[size='16'] { width: 5.6em; } .em35 input[size='17'] { width: 5.95em; } .em35 input[size='18'] { width: 6.3em; } .em35 input[size='19'] { width: 6.65em; } .em35 input[size='20'] { width: 7.0em; } | |||
| .em40 input[size='1'] { width: 0.4em; } .em40 input[size='2'] { width: 0.8em; } .em40 input[size='3'] { width: 1.2em; } .em40 input[size='4'] { width: 1.6em; } .em40 input[size='5'] { width: 2.0em; } .em40 input[size='6'] { width: 2.4em; } .em40 input[size='7'] { width: 2.8em; } .em40 input[size='8'] { width: 3.2em; } .em40 input[size='9'] { width: 3.6em; } .em40 input[size='10'] { width: 4.0em; } .em40 input[size='11'] { width: 4.4em; } .em40 input[size='12'] { width: 4.8em; } .em40 input[size='13'] { width: 5.2em; } .em40 input[size='14'] { width: 5.6em; } .em40 input[size='15'] { width: 6.0em; } .em40 input[size='16'] { width: 6.4em; } .em40 input[size='17'] { width: 6.8em; } .em40 input[size='18'] { width: 7.2em; } .em40 input[size='19'] { width: 7.6em; } .em40 input[size='20'] { width: 8.0em; } | |||
| .em45 input[size='1'] { width: 0.45em; } .em45 input[size='2'] { width: 0.9em; } .em45 input[size='3'] { width: 1.35em; } .em45 input[size='4'] { width: 1.8em; } .em45 input[size='5'] { width: 2.25em; } .em45 input[size='6'] { width: 2.7em; } .em45 input[size='7'] { width: 3.15em; } .em45 input[size='8'] { width: 3.6em; } .em45 input[size='9'] { width: 4.05em; } .em45 input[size='10'] { width: 4.5em; } .em45 input[size='11'] { width: 4.95em; } .em45 input[size='12'] { width: 5.4em; } .em45 input[size='13'] { width: 5.85em; } .em45 input[size='14'] { width: 6.3em; } .em45 input[size='15'] { width: 6.75em; } .em45 input[size='16'] { width: 7.2em; } .em45 input[size='17'] { width: 7.65em; } .em45 input[size='18'] { width: 8.1em; } .em45 input[size='19'] { width: 8.55em; } .em45 input[size='20'] { width: 9.0em; } | |||
| .em50 input[size='1'] { width: 0.5em; } .em50 input[size='2'] { width: 1.0em; } .em50 input[size='3'] { width: 1.5em; } .em50 input[size='4'] { width: 2.0em; } .em50 input[size='5'] { width: 2.5em; } .em50 input[size='6'] { width: 3.0em; } .em50 input[size='7'] { width: 3.5em; } .em50 input[size='8'] { width: 4.0em; } .em50 input[size='9'] { width: 4.5em; } .em50 input[size='10'] { width: 5.0em; } .em50 input[size='11'] { width: 5.5em; } .em50 input[size='12'] { width: 6.0em; } .em50 input[size='13'] { width: 6.5em; } .em50 input[size='14'] { width: 7.0em; } .em50 input[size='15'] { width: 7.5em; } .em50 input[size='16'] { width: 8.0em; } .em50 input[size='17'] { width: 8.5em; } .em50 input[size='18'] { width: 9.0em; } .em50 input[size='19'] { width: 9.5em; } .em50 input[size='20'] { width: 10.0em; } | |||
| .em55 input[size='1'] { width: 0.55em; } .em55 input[size='2'] { width: 1.1em; } .em55 input[size='3'] { width: 1.65em; } .em55 input[size='4'] { width: 2.2em; } .em55 input[size='5'] { width: 2.75em; } .em55 input[size='6'] { width: 3.3em; } .em55 input[size='7'] { width: 3.85em; } .em55 input[size='8'] { width: 4.4em; } .em55 input[size='9'] { width: 4.95em; } .em55 input[size='10'] { width: 5.5em; } .em55 input[size='11'] { width: 6.05em; } .em55 input[size='12'] { width: 6.6em; } .em55 input[size='13'] { width: 7.15em; } .em55 input[size='14'] { width: 7.7em; } .em55 input[size='15'] { width: 8.25em; } .em55 input[size='16'] { width: 8.8em; } .em55 input[size='17'] { width: 9.35em; } .em55 input[size='18'] { width: 9.9em; } .em55 input[size='19'] { width: 10.45em; } .em55 input[size='20'] { width: 11.0em; } | |||
| .em60 input[size='1'] { width: 0.6em; } .em60 input[size='2'] { width: 1.2em; } .em60 input[size='3'] { width: 1.8em; } .em60 input[size='4'] { width: 2.4em; } .em60 input[size='5'] { width: 3.0em; } .em60 input[size='6'] { width: 3.6em; } .em60 input[size='7'] { width: 4.2em; } .em60 input[size='8'] { width: 4.8em; } .em60 input[size='9'] { width: 5.4em; } .em60 input[size='10'] { width: 6.0em; } .em60 input[size='11'] { width: 6.6em; } .em60 input[size='12'] { width: 7.2em; } .em60 input[size='13'] { width: 7.8em; } .em60 input[size='14'] { width: 8.4em; } .em60 input[size='15'] { width: 9.0em; } .em60 input[size='16'] { width: 9.6em; } .em60 input[size='17'] { width: 10.2em; } .em60 input[size='18'] { width: 10.8em; } .em60 input[size='19'] { width: 11.4em; } .em60 input[size='20'] { width: 12.0em; } | |||
| .em65 input[size='1'] { width: 0.65em; } .em65 input[size='2'] { width: 1.3em; } .em65 input[size='3'] { width: 1.95em; } .em65 input[size='4'] { width: 2.6em; } .em65 input[size='5'] { width: 3.25em; } .em65 input[size='6'] { width: 3.9em; } .em65 input[size='7'] { width: 4.55em; } .em65 input[size='8'] { width: 5.2em; } .em65 input[size='9'] { width: 5.85em; } .em65 input[size='10'] { width: 6.5em; } .em65 input[size='11'] { width: 7.15em; } .em65 input[size='12'] { width: 7.8em; } .em65 input[size='13'] { width: 8.45em; } .em65 input[size='14'] { width: 9.1em; } .em65 input[size='15'] { width: 9.75em; } .em65 input[size='16'] { width: 10.4em; } .em65 input[size='17'] { width: 11.05em; } .em65 input[size='18'] { width: 11.7em; } .em65 input[size='19'] { width: 12.35em; } .em65 input[size='20'] { width: 13.0em; } | |||
| .em70 input[size='1'] { width: 0.7em; } .em70 input[size='2'] { width: 1.4em; } .em70 input[size='3'] { width: 2.1em; } .em70 input[size='4'] { width: 2.8em; } .em70 input[size='5'] { width: 3.5em; } .em70 input[size='6'] { width: 4.2em; } .em70 input[size='7'] { width: 4.9em; } .em70 input[size='8'] { width: 5.6em; } .em70 input[size='9'] { width: 6.3em; } .em70 input[size='10'] { width: 7.0em; } .em70 input[size='11'] { width: 7.7em; } .em70 input[size='12'] { width: 8.4em; } .em70 input[size='13'] { width: 9.1em; } .em70 input[size='14'] { width: 9.8em; } .em70 input[size='15'] { width: 10.5em; } .em70 input[size='16'] { width: 11.2em; } .em70 input[size='17'] { width: 11.9em; } .em70 input[size='18'] { width: 12.6em; } .em70 input[size='19'] { width: 13.3em; } .em70 input[size='20'] { width: 14.0em; } | |||
| .em75 input[size='1'] { width: 0.75em; } .em75 input[size='2'] { width: 1.5em; } .em75 input[size='3'] { width: 2.25em; } .em75 input[size='4'] { width: 3.0em; } .em75 input[size='5'] { width: 3.75em; } .em75 input[size='6'] { width: 4.5em; } .em75 input[size='7'] { width: 5.25em; } .em75 input[size='8'] { width: 6.0em; } .em75 input[size='9'] { width: 6.75em; } .em75 input[size='10'] { width: 7.5em; } .em75 input[size='11'] { width: 8.25em; } .em75 input[size='12'] { width: 9.0em; } .em75 input[size='13'] { width: 9.75em; } .em75 input[size='14'] { width: 10.5em; } .em75 input[size='15'] { width: 11.25em; } .em75 input[size='16'] { width: 12.0em; } .em75 input[size='17'] { width: 12.75em; } .em75 input[size='18'] { width: 13.5em; } .em75 input[size='19'] { width: 14.25em; } .em75 input[size='20'] { width: 15.0em; } | |||
| .em80 input[size='1'] { width: 0.8em; } .em80 input[size='2'] { width: 1.6em; } .em80 input[size='3'] { width: 2.4em; } .em80 input[size='4'] { width: 3.2em; } .em80 input[size='5'] { width: 4.0em; } .em80 input[size='6'] { width: 4.8em; } .em80 input[size='7'] { width: 5.6em; } .em80 input[size='8'] { width: 6.4em; } .em80 input[size='9'] { width: 7.2em; } .em80 input[size='10'] { width: 8.0em; } .em80 input[size='11'] { width: 8.8em; } .em80 input[size='12'] { width: 9.6em; } .em80 input[size='13'] { width: 10.4em; } .em80 input[size='14'] { width: 11.2em; } .em80 input[size='15'] { width: 12.0em; } .em80 input[size='16'] { width: 12.8em; } .em80 input[size='17'] { width: 13.6em; } .em80 input[size='18'] { width: 14.4em; } .em80 input[size='19'] { width: 15.2em; } .em80 input[size='20'] { width: 16.0em; } | |||
| .em85 input[size='1'] { width: 0.85em; } .em85 input[size='2'] { width: 1.7em; } .em85 input[size='3'] { width: 2.55em; } .em85 input[size='4'] { width: 3.4em; } .em85 input[size='5'] { width: 4.25em; } .em85 input[size='6'] { width: 5.1em; } .em85 input[size='7'] { width: 5.95em; } .em85 input[size='8'] { width: 6.8em; } .em85 input[size='9'] { width: 7.65em; } .em85 input[size='10'] { width: 8.5em; } .em85 input[size='11'] { width: 9.35em; } .em85 input[size='12'] { width: 10.2em; } .em85 input[size='13'] { width: 11.05em; } .em85 input[size='14'] { width: 11.9em; } .em85 input[size='15'] { width: 12.75em; } .em85 input[size='16'] { width: 13.6em; } .em85 input[size='17'] { width: 14.45em; } .em85 input[size='18'] { width: 15.3em; } .em85 input[size='19'] { width: 16.15em; } .em85 input[size='20'] { width: 17.0em; } | |||
| .em90 input[size='1'] { width: 0.9em; } .em90 input[size='2'] { width: 1.8em; } .em90 input[size='3'] { width: 2.7em; } .em90 input[size='4'] { width: 3.6em; } .em90 input[size='5'] { width: 4.5em; } .em90 input[size='6'] { width: 5.4em; } .em90 input[size='7'] { width: 6.3em; } .em90 input[size='8'] { width: 7.2em; } .em90 input[size='9'] { width: 8.1em; } .em90 input[size='10'] { width: 9.0em; } .em90 input[size='11'] { width: 9.9em; } .em90 input[size='12'] { width: 10.8em; } .em90 input[size='13'] { width: 11.7em; } .em90 input[size='14'] { width: 12.6em; } .em90 input[size='15'] { width: 13.5em; } .em90 input[size='16'] { width: 14.4em; } .em90 input[size='17'] { width: 15.3em; } .em90 input[size='18'] { width: 16.2em; } .em90 input[size='19'] { width: 17.1em; } .em90 input[size='20'] { width: 18.0em; } | |||
| .em95 input[size='1'] { width: 0.95em; } .em95 input[size='2'] { width: 1.9em; } .em95 input[size='3'] { width: 2.85em; } .em95 input[size='4'] { width: 3.8em; } .em95 input[size='5'] { width: 4.75em; } .em95 input[size='6'] { width: 5.7em; } .em95 input[size='7'] { width: 6.65em; } .em95 input[size='8'] { width: 7.6em; } .em95 input[size='9'] { width: 8.55em; } .em95 input[size='10'] { width: 9.5em; } .em95 input[size='11'] { width: 10.45em; } .em95 input[size='12'] { width: 11.4em; } .em95 input[size='13'] { width: 12.35em; } .em95 input[size='14'] { width: 13.3em; } .em95 input[size='15'] { width: 14.25em; } .em95 input[size='16'] { width: 15.2em; } .em95 input[size='17'] { width: 16.15em; } .em95 input[size='18'] { width: 17.1em; } .em95 input[size='19'] { width: 18.05em; } .em95 input[size='20'] { width: 19.0em; } | |||
| .em100 input[size='1'] { width: 1.0em; } .em100 input[size='2'] { width: 2.0em; } .em100 input[size='3'] { width: 3.0em; } .em100 input[size='4'] { width: 4.0em; } .em100 input[size='5'] { width: 5.0em; } .em100 input[size='6'] { width: 6.0em; } .em100 input[size='7'] { width: 7.0em; } .em100 input[size='8'] { width: 8.0em; } .em100 input[size='9'] { width: 9.0em; } .em100 input[size='10'] { width: 10.0em; } .em100 input[size='11'] { width: 11.0em; } .em100 input[size='12'] { width: 12.0em; } .em100 input[size='13'] { width: 13.0em; } .em100 input[size='14'] { width: 14.0em; } .em100 input[size='15'] { width: 15.0em; } .em100 input[size='16'] { width: 16.0em; } .em100 input[size='17'] { width: 17.0em; } .em100 input[size='18'] { width: 18.0em; } .em100 input[size='19'] { width: 19.0em; } .em100 input[size='20'] { width: 20.0em; } | |||
| input.Folded { cursor: default; } | |||
| .Operator { color: #C678DD; } | |||
| .Conditional { color: #C678DD; } | |||
| .Type { color: #E5C07B; } | |||
| .Constant { color: #56B6C2; } | |||
| .Structure { color: #E5C07B; } | |||
| .Statement { color: #C678DD; } | |||
| .PreProc { color: #E5C07B; } | |||
| .String { color: #98C379; } | |||
| --> | |||
| </style> | |||
| <script type='text/javascript'> | |||
| <!-- | |||
| /* simulate a "ch" unit by asking the browser how big a zero character is */ | |||
| function FixCharWidth() { | |||
| /* get the hidden element which gives the width of a single character */ | |||
| var goodWidth = document.getElementById("oneCharWidth").clientWidth; | |||
| /* get all input elements, we'll filter on class later */ | |||
| var inputTags = document.getElementsByTagName("input"); | |||
| var ratio = 5; | |||
| var inputWidth = document.getElementById("oneInputWidth").clientWidth; | |||
| var emWidth = document.getElementById("oneEmWidth").clientWidth; | |||
| if (inputWidth > goodWidth) { | |||
| while (ratio < 100*goodWidth/emWidth && ratio < 100) { | |||
| ratio += 5; | |||
| } | |||
| document.getElementById("vimCodeElement").className = "em"+ratio; | |||
| } | |||
| } | |||
| --> | |||
| </script> | |||
| </head> | |||
| <body onload='FixCharWidth();'> | |||
| <!-- hidden divs used by javascript to get the width of a char --> | |||
| <div id='oneCharWidth'>0</div> | |||
| <div id='oneInputWidth'><input size='1' value='0'></div> | |||
| <div id='oneEmWidth' style='width: 1em;'></div> | |||
| <pre id='vimCodeElement'> | |||
| eq_3f_1 <span class="Operator">=</span> <span class="PreProc">setmetatable1</span>((<span class="Structure">{</span>[<span class="String">"lookup"</span>]<span class="Operator">=</span>(<span class="Structure">{}</span>)<span class="Structure">}</span>), (<span class="Structure">{</span>[<span class="String">"__call"</span>]<span class="Operator">=</span>(<span class="Statement">function</span>(temp_this, x, y) | |||
| <span class="Type">local</span> temp_method | |||
| <span class="Type">local</span> temp <span class="Operator">=</span> temp_this[<span class="String">"lookup"</span>] | |||
| <span class="Conditional">if</span> temp <span class="Conditional">then</span> | |||
| <span class="Type">local</span> temp1 <span class="Operator">=</span> temp[<span class="PreProc">type1</span>(x)] | |||
| <span class="Conditional">if</span> temp1 <span class="Conditional">then</span> | |||
| temp_method <span class="Operator">=</span> temp1[<span class="PreProc">type1</span>(y)] <span class="Operator">or</span> <span class="Constant">nil</span> | |||
| <span class="Conditional">else</span> | |||
| temp_method <span class="Operator">=</span> <span class="Constant">nil</span> | |||
| <span class="Conditional">end</span> | |||
| <span class="Conditional">else</span> | |||
| temp_method <span class="Operator">=</span> <span class="Constant">nil</span> | |||
| <span class="Conditional">end</span> | |||
| <span class="Conditional">if</span> <span class="Operator">not</span> temp_method <span class="Conditional">then</span> | |||
| <span class="Conditional">if</span> temp_this[<span class="String">"default"</span>] <span class="Conditional">then</span> | |||
| temp_method <span class="Operator">=</span> temp_this[<span class="String">"default"</span>] | |||
| <span class="Conditional">else</span> | |||
| <span class="PreProc">error1</span>(<span class="String">"No matching method to call for "</span> <span class="Operator">..</span> (<span class="PreProc">type1</span>(x) <span class="Operator">..</span> <span class="String">" "</span>) <span class="Operator">..</span> (<span class="PreProc">type1</span>(y) <span class="Operator">..</span> <span class="String">" "</span>) <span class="Operator">..</span> <span class="String">"</span>\n<span class="String">there are methods to call for "</span> <span class="Operator">..</span> <span class="PreProc">keys1</span>(temp_this[<span class="String">"lookup"</span>])) | |||
| <span class="Conditional">end</span> | |||
| <span class="Conditional">end</span> | |||
| <span class="Statement">return</span> <span class="PreProc">temp_method</span>(x, y) | |||
| <span class="Statement">end</span>)<span class="Structure">}</span>)) | |||
| </pre> | |||
| </body> | |||
| </html> | |||
| <!-- vim: set foldmethod=manual : --> | |||
BIN
static/icon/android-chrome-192x192.png
View File
{kind=link}
| Before | After |
|---|---|
|
|
|
| Width: 192 | Height: 192 | Size: 28 KiB |
BIN
static/icon/android-chrome-512x512.png
View File
{kind=link}
| Before | After |
|---|---|
|
|
|
| Width: 512 | Height: 512 | Size: 149 KiB |
BIN
static/icon/apple-touch-icon.png
View File
{kind=link}
| Before | After |
|---|---|
|
|
|
| Width: 180 | Height: 180 | Size: 25 KiB |
BIN
static/icon/favicon-16x16.png
View File
{kind=link}
| Before | After |
|---|---|
|
|
|
| Width: 16 | Height: 16 | Size: 632 B |
BIN
static/icon/favicon-32x32.png
View File
{kind=link}
| Before | After |
|---|---|
|
|
|
| Width: 32 | Height: 32 | Size: 1.5 KiB |
BIN
static/icon/favicon.ico
View File
| Before | After |
|---|---|
|
|
BIN
static/icon/valid-html20.png
View File
{kind=link}
| Before | After |
|---|---|
|
|
|
| Width: 88 | Height: 31 | Size: 1.5 KiB |
+ 93
- 0
static/licenses/LICENSE.FantasqueSansMono
View File
| @ -0,0 +1,93 @@ | |||
| Copyright (c) 2013-2017, Jany Belluz ([email protected]) | |||
| This Font Software is licensed under the SIL Open Font License, Version 1.1. | |||
| This license is copied below, and is also available with a FAQ at: | |||
| http://scripts.sil.org/OFL | |||
| ----------------------------------------------------------- | |||
| SIL OPEN FONT LICENSE Version 1.1 - 26 February 2007 | |||
| ----------------------------------------------------------- | |||
| PREAMBLE | |||
| The goals of the Open Font License (OFL) are to stimulate worldwide | |||
| development of collaborative font projects, to support the font creation | |||
| efforts of academic and linguistic communities, and to provide a free and | |||
| open framework in which fonts may be shared and improved in partnership | |||
| with others. | |||
| The OFL allows the licensed fonts to be used, studied, modified and | |||
| redistributed freely as long as they are not sold by themselves. The | |||
| fonts, including any derivative works, can be bundled, embedded, | |||
| redistributed and/or sold with any software provided that any reserved | |||
| names are not used by derivative works. The fonts and derivatives, | |||
| however, cannot be released under any other type of license. The | |||
| requirement for fonts to remain under this license does not apply | |||
| to any document created using the fonts or their derivatives. | |||
| DEFINITIONS | |||
| "Font Software" refers to the set of files released by the Copyright | |||
| Holder(s) under this license and clearly marked as such. This may | |||
| include source files, build scripts and documentation. | |||
| "Reserved Font Name" refers to any names specified as such after the | |||
| copyright statement(s). | |||
| "Original Version" refers to the collection of Font Software components as | |||
| distributed by the Copyright Holder(s). | |||
| "Modified Version" refers to any derivative made by adding to, deleting, | |||
| or substituting -- in part or in whole -- any of the components of the | |||
| Original Version, by changing formats or by porting the Font Software to a | |||
| new environment. | |||
| "Author" refers to any designer, engineer, programmer, technical | |||
| writer or other person who contributed to the Font Software. | |||
| PERMISSION & CONDITIONS | |||
| Permission is hereby granted, free of charge, to any person obtaining | |||
| a copy of the Font Software, to use, study, copy, merge, embed, modify, | |||
| redistribute, and sell modified and unmodified copies of the Font | |||
| Software, subject to the following conditions: | |||
| 1) Neither the Font Software nor any of its individual components, | |||
| in Original or Modified Versions, may be sold by itself. | |||
| 2) Original or Modified Versions of the Font Software may be bundled, | |||
| redistributed and/or sold with any software, provided that each copy | |||
| contains the above copyright notice and this license. These can be | |||
| included either as stand-alone text files, human-readable headers or | |||
| in the appropriate machine-readable metadata fields within text or | |||
| binary files as long as those fields can be easily viewed by the user. | |||
| 3) No Modified Version of the Font Software may use the Reserved Font | |||
| Name(s) unless explicit written permission is granted by the corresponding | |||
| Copyright Holder. This restriction only applies to the primary font name as | |||
| presented to the users. | |||
| 4) The name(s) of the Copyright Holder(s) or the Author(s) of the Font | |||
| Software shall not be used to promote, endorse or advertise any | |||
| Modified Version, except to acknowledge the contribution(s) of the | |||
| Copyright Holder(s) and the Author(s) or with their explicit written | |||
| permission. | |||
| 5) The Font Software, modified or unmodified, in part or in whole, | |||
| must be distributed entirely under this license, and must not be | |||
| distributed under any other license. The requirement for fonts to | |||
| remain under this license does not apply to any document created | |||
| using the Font Software. | |||
| TERMINATION | |||
| This license becomes null and void if any of the above conditions are | |||
| not met. | |||
| DISCLAIMER | |||
| THE FONT SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, | |||
| EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO ANY WARRANTIES OF | |||
| MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT | |||
| OF COPYRIGHT, PATENT, TRADEMARK, OR OTHER RIGHT. IN NO EVENT SHALL THE | |||
| COPYRIGHT HOLDER BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, | |||
| INCLUDING ANY GENERAL, SPECIAL, INDIRECT, INCIDENTAL, OR CONSEQUENTIAL | |||
| DAMAGES, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING | |||
| FROM, OUT OF THE USE OR INABILITY TO USE THE FONT SOFTWARE OR FROM | |||
| OTHER DEALINGS IN THE FONT SOFTWARE. | |||
+ 21
- 0
static/licenses/LICENSE.KaTeX
View File
| @ -0,0 +1,21 @@ | |||
| The MIT License (MIT) | |||
| Copyright (c) 2013-2018 Khan Academy | |||
| Permission is hereby granted, free of charge, to any person obtaining a copy | |||
| of this software and associated documentation files (the "Software"), to deal | |||
| in the Software without restriction, including without limitation the rights | |||
| to use, copy, modify, merge, publish, distribute, sublicense, and/or sell | |||
| copies of the Software, and to permit persons to whom the Software is | |||
| furnished to do so, subject to the following conditions: | |||
| The above copyright notice and this permission notice shall be included in all | |||
| copies or substantial portions of the Software. | |||
| THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR | |||
| IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, | |||
| FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE | |||
| AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER | |||
| LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, | |||
| OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE | |||
| SOFTWARE. | |||
BIN
static/pfp.jpg
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 1500 | Height: 1500 | Size: 948 KiB |
+ 215
- 0
static/profunctor-impredicative.ml.html
View File
| @ -0,0 +1,215 @@ | |||
| <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd"> | |||
| <html> | |||
| <head> | |||
| <meta http-equiv="content-type" content="text/html; charset=UTF-8"> | |||
| <title>~/Projects/amulet/profunctor-impredicative.ml.html</title> | |||
| <meta name="Generator" content="Vim/8.0"> | |||
| <meta name="plugin-version" content="vim8.1_v1"> | |||
| <meta name="syntax" content="amulet"> | |||
| <meta name="settings" content="use_css,pre_wrap,no_foldcolumn,expand_tabs,prevent_copy=t"> | |||
| <meta name="colorscheme" content="onedark"> | |||
| <style type="text/css"> | |||
| <!-- | |||
| pre { white-space: pre-wrap; font-family: 'Iosevka','Iosevka Term', monospace; color: #ABB2BF; background-color: #282C34; } | |||
| body { font-family: 'Iosevka','Iosevka Term', monospace; color: #ABB2BF; background-color: #282C34; } | |||
| * { font-size: 1em; } | |||
| input { border: none; margin: 0; padding: 0; font-family: 'Iosevka','Iosevka Term', monospace; } | |||
| input[size='1'] { width: 1em; width: 1ch; } | |||
| input[size='2'] { width: 2em; width: 2ch; } | |||
| input[size='3'] { width: 3em; width: 3ch; } | |||
| input[size='4'] { width: 4em; width: 4ch; } | |||
| input[size='5'] { width: 5em; width: 5ch; } | |||
| input[size='6'] { width: 6em; width: 6ch; } | |||
| input[size='7'] { width: 7em; width: 7ch; } | |||
| input[size='8'] { width: 8em; width: 8ch; } | |||
| input[size='9'] { width: 9em; width: 9ch; } | |||
| input[size='10'] { width: 10em; width: 10ch; } | |||
| input[size='11'] { width: 11em; width: 11ch; } | |||
| input[size='12'] { width: 12em; width: 12ch; } | |||
| input[size='13'] { width: 13em; width: 13ch; } | |||
| input[size='14'] { width: 14em; width: 14ch; } | |||
| input[size='15'] { width: 15em; width: 15ch; } | |||
| input[size='16'] { width: 16em; width: 16ch; } | |||
| input[size='17'] { width: 17em; width: 17ch; } | |||
| input[size='18'] { width: 18em; width: 18ch; } | |||
| input[size='19'] { width: 19em; width: 19ch; } | |||
| input[size='20'] { width: 20em; width: 20ch; } | |||
| #oneCharWidth, #oneEmWidth, #oneInputWidth { padding: 0; margin: 0; position: absolute; left: -999999px; visibility: hidden; } | |||
| .em5 input[size='1'] { width: 0.05em; } .em5 input[size='2'] { width: 0.1em; } .em5 input[size='3'] { width: 0.15em; } .em5 input[size='4'] { width: 0.2em; } .em5 input[size='5'] { width: 0.25em; } .em5 input[size='6'] { width: 0.3em; } .em5 input[size='7'] { width: 0.35em; } .em5 input[size='8'] { width: 0.4em; } .em5 input[size='9'] { width: 0.45em; } .em5 input[size='10'] { width: 0.5em; } .em5 input[size='11'] { width: 0.55em; } .em5 input[size='12'] { width: 0.6em; } .em5 input[size='13'] { width: 0.65em; } .em5 input[size='14'] { width: 0.7em; } .em5 input[size='15'] { width: 0.75em; } .em5 input[size='16'] { width: 0.8em; } .em5 input[size='17'] { width: 0.85em; } .em5 input[size='18'] { width: 0.9em; } .em5 input[size='19'] { width: 0.95em; } .em5 input[size='20'] { width: 1.0em; } | |||
| .em10 input[size='1'] { width: 0.1em; } .em10 input[size='2'] { width: 0.2em; } .em10 input[size='3'] { width: 0.3em; } .em10 input[size='4'] { width: 0.4em; } .em10 input[size='5'] { width: 0.5em; } .em10 input[size='6'] { width: 0.6em; } .em10 input[size='7'] { width: 0.7em; } .em10 input[size='8'] { width: 0.8em; } .em10 input[size='9'] { width: 0.9em; } .em10 input[size='10'] { width: 1.0em; } .em10 input[size='11'] { width: 1.1em; } .em10 input[size='12'] { width: 1.2em; } .em10 input[size='13'] { width: 1.3em; } .em10 input[size='14'] { width: 1.4em; } .em10 input[size='15'] { width: 1.5em; } .em10 input[size='16'] { width: 1.6em; } .em10 input[size='17'] { width: 1.7em; } .em10 input[size='18'] { width: 1.8em; } .em10 input[size='19'] { width: 1.9em; } .em10 input[size='20'] { width: 2.0em; } | |||
| .em15 input[size='1'] { width: 0.15em; } .em15 input[size='2'] { width: 0.3em; } .em15 input[size='3'] { width: 0.45em; } .em15 input[size='4'] { width: 0.6em; } .em15 input[size='5'] { width: 0.75em; } .em15 input[size='6'] { width: 0.9em; } .em15 input[size='7'] { width: 1.05em; } .em15 input[size='8'] { width: 1.2em; } .em15 input[size='9'] { width: 1.35em; } .em15 input[size='10'] { width: 1.5em; } .em15 input[size='11'] { width: 1.65em; } .em15 input[size='12'] { width: 1.8em; } .em15 input[size='13'] { width: 1.95em; } .em15 input[size='14'] { width: 2.1em; } .em15 input[size='15'] { width: 2.25em; } .em15 input[size='16'] { width: 2.4em; } .em15 input[size='17'] { width: 2.55em; } .em15 input[size='18'] { width: 2.7em; } .em15 input[size='19'] { width: 2.85em; } .em15 input[size='20'] { width: 3.0em; } | |||
| .em20 input[size='1'] { width: 0.2em; } .em20 input[size='2'] { width: 0.4em; } .em20 input[size='3'] { width: 0.6em; } .em20 input[size='4'] { width: 0.8em; } .em20 input[size='5'] { width: 1.0em; } .em20 input[size='6'] { width: 1.2em; } .em20 input[size='7'] { width: 1.4em; } .em20 input[size='8'] { width: 1.6em; } .em20 input[size='9'] { width: 1.8em; } .em20 input[size='10'] { width: 2.0em; } .em20 input[size='11'] { width: 2.2em; } .em20 input[size='12'] { width: 2.4em; } .em20 input[size='13'] { width: 2.6em; } .em20 input[size='14'] { width: 2.8em; } .em20 input[size='15'] { width: 3.0em; } .em20 input[size='16'] { width: 3.2em; } .em20 input[size='17'] { width: 3.4em; } .em20 input[size='18'] { width: 3.6em; } .em20 input[size='19'] { width: 3.8em; } .em20 input[size='20'] { width: 4.0em; } | |||
| .em25 input[size='1'] { width: 0.25em; } .em25 input[size='2'] { width: 0.5em; } .em25 input[size='3'] { width: 0.75em; } .em25 input[size='4'] { width: 1.0em; } .em25 input[size='5'] { width: 1.25em; } .em25 input[size='6'] { width: 1.5em; } .em25 input[size='7'] { width: 1.75em; } .em25 input[size='8'] { width: 2.0em; } .em25 input[size='9'] { width: 2.25em; } .em25 input[size='10'] { width: 2.5em; } .em25 input[size='11'] { width: 2.75em; } .em25 input[size='12'] { width: 3.0em; } .em25 input[size='13'] { width: 3.25em; } .em25 input[size='14'] { width: 3.5em; } .em25 input[size='15'] { width: 3.75em; } .em25 input[size='16'] { width: 4.0em; } .em25 input[size='17'] { width: 4.25em; } .em25 input[size='18'] { width: 4.5em; } .em25 input[size='19'] { width: 4.75em; } .em25 input[size='20'] { width: 5.0em; } | |||
| .em30 input[size='1'] { width: 0.3em; } .em30 input[size='2'] { width: 0.6em; } .em30 input[size='3'] { width: 0.9em; } .em30 input[size='4'] { width: 1.2em; } .em30 input[size='5'] { width: 1.5em; } .em30 input[size='6'] { width: 1.8em; } .em30 input[size='7'] { width: 2.1em; } .em30 input[size='8'] { width: 2.4em; } .em30 input[size='9'] { width: 2.7em; } .em30 input[size='10'] { width: 3.0em; } .em30 input[size='11'] { width: 3.3em; } .em30 input[size='12'] { width: 3.6em; } .em30 input[size='13'] { width: 3.9em; } .em30 input[size='14'] { width: 4.2em; } .em30 input[size='15'] { width: 4.5em; } .em30 input[size='16'] { width: 4.8em; } .em30 input[size='17'] { width: 5.1em; } .em30 input[size='18'] { width: 5.4em; } .em30 input[size='19'] { width: 5.7em; } .em30 input[size='20'] { width: 6.0em; } | |||
| .em35 input[size='1'] { width: 0.35em; } .em35 input[size='2'] { width: 0.7em; } .em35 input[size='3'] { width: 1.05em; } .em35 input[size='4'] { width: 1.4em; } .em35 input[size='5'] { width: 1.75em; } .em35 input[size='6'] { width: 2.1em; } .em35 input[size='7'] { width: 2.45em; } .em35 input[size='8'] { width: 2.8em; } .em35 input[size='9'] { width: 3.15em; } .em35 input[size='10'] { width: 3.5em; } .em35 input[size='11'] { width: 3.85em; } .em35 input[size='12'] { width: 4.2em; } .em35 input[size='13'] { width: 4.55em; } .em35 input[size='14'] { width: 4.9em; } .em35 input[size='15'] { width: 5.25em; } .em35 input[size='16'] { width: 5.6em; } .em35 input[size='17'] { width: 5.95em; } .em35 input[size='18'] { width: 6.3em; } .em35 input[size='19'] { width: 6.65em; } .em35 input[size='20'] { width: 7.0em; } | |||
| .em40 input[size='1'] { width: 0.4em; } .em40 input[size='2'] { width: 0.8em; } .em40 input[size='3'] { width: 1.2em; } .em40 input[size='4'] { width: 1.6em; } .em40 input[size='5'] { width: 2.0em; } .em40 input[size='6'] { width: 2.4em; } .em40 input[size='7'] { width: 2.8em; } .em40 input[size='8'] { width: 3.2em; } .em40 input[size='9'] { width: 3.6em; } .em40 input[size='10'] { width: 4.0em; } .em40 input[size='11'] { width: 4.4em; } .em40 input[size='12'] { width: 4.8em; } .em40 input[size='13'] { width: 5.2em; } .em40 input[size='14'] { width: 5.6em; } .em40 input[size='15'] { width: 6.0em; } .em40 input[size='16'] { width: 6.4em; } .em40 input[size='17'] { width: 6.8em; } .em40 input[size='18'] { width: 7.2em; } .em40 input[size='19'] { width: 7.6em; } .em40 input[size='20'] { width: 8.0em; } | |||
| .em45 input[size='1'] { width: 0.45em; } .em45 input[size='2'] { width: 0.9em; } .em45 input[size='3'] { width: 1.35em; } .em45 input[size='4'] { width: 1.8em; } .em45 input[size='5'] { width: 2.25em; } .em45 input[size='6'] { width: 2.7em; } .em45 input[size='7'] { width: 3.15em; } .em45 input[size='8'] { width: 3.6em; } .em45 input[size='9'] { width: 4.05em; } .em45 input[size='10'] { width: 4.5em; } .em45 input[size='11'] { width: 4.95em; } .em45 input[size='12'] { width: 5.4em; } .em45 input[size='13'] { width: 5.85em; } .em45 input[size='14'] { width: 6.3em; } .em45 input[size='15'] { width: 6.75em; } .em45 input[size='16'] { width: 7.2em; } .em45 input[size='17'] { width: 7.65em; } .em45 input[size='18'] { width: 8.1em; } .em45 input[size='19'] { width: 8.55em; } .em45 input[size='20'] { width: 9.0em; } | |||
| .em50 input[size='1'] { width: 0.5em; } .em50 input[size='2'] { width: 1.0em; } .em50 input[size='3'] { width: 1.5em; } .em50 input[size='4'] { width: 2.0em; } .em50 input[size='5'] { width: 2.5em; } .em50 input[size='6'] { width: 3.0em; } .em50 input[size='7'] { width: 3.5em; } .em50 input[size='8'] { width: 4.0em; } .em50 input[size='9'] { width: 4.5em; } .em50 input[size='10'] { width: 5.0em; } .em50 input[size='11'] { width: 5.5em; } .em50 input[size='12'] { width: 6.0em; } .em50 input[size='13'] { width: 6.5em; } .em50 input[size='14'] { width: 7.0em; } .em50 input[size='15'] { width: 7.5em; } .em50 input[size='16'] { width: 8.0em; } .em50 input[size='17'] { width: 8.5em; } .em50 input[size='18'] { width: 9.0em; } .em50 input[size='19'] { width: 9.5em; } .em50 input[size='20'] { width: 10.0em; } | |||
| .em55 input[size='1'] { width: 0.55em; } .em55 input[size='2'] { width: 1.1em; } .em55 input[size='3'] { width: 1.65em; } .em55 input[size='4'] { width: 2.2em; } .em55 input[size='5'] { width: 2.75em; } .em55 input[size='6'] { width: 3.3em; } .em55 input[size='7'] { width: 3.85em; } .em55 input[size='8'] { width: 4.4em; } .em55 input[size='9'] { width: 4.95em; } .em55 input[size='10'] { width: 5.5em; } .em55 input[size='11'] { width: 6.05em; } .em55 input[size='12'] { width: 6.6em; } .em55 input[size='13'] { width: 7.15em; } .em55 input[size='14'] { width: 7.7em; } .em55 input[size='15'] { width: 8.25em; } .em55 input[size='16'] { width: 8.8em; } .em55 input[size='17'] { width: 9.35em; } .em55 input[size='18'] { width: 9.9em; } .em55 input[size='19'] { width: 10.45em; } .em55 input[size='20'] { width: 11.0em; } | |||
| .em60 input[size='1'] { width: 0.6em; } .em60 input[size='2'] { width: 1.2em; } .em60 input[size='3'] { width: 1.8em; } .em60 input[size='4'] { width: 2.4em; } .em60 input[size='5'] { width: 3.0em; } .em60 input[size='6'] { width: 3.6em; } .em60 input[size='7'] { width: 4.2em; } .em60 input[size='8'] { width: 4.8em; } .em60 input[size='9'] { width: 5.4em; } .em60 input[size='10'] { width: 6.0em; } .em60 input[size='11'] { width: 6.6em; } .em60 input[size='12'] { width: 7.2em; } .em60 input[size='13'] { width: 7.8em; } .em60 input[size='14'] { width: 8.4em; } .em60 input[size='15'] { width: 9.0em; } .em60 input[size='16'] { width: 9.6em; } .em60 input[size='17'] { width: 10.2em; } .em60 input[size='18'] { width: 10.8em; } .em60 input[size='19'] { width: 11.4em; } .em60 input[size='20'] { width: 12.0em; } | |||
| .em65 input[size='1'] { width: 0.65em; } .em65 input[size='2'] { width: 1.3em; } .em65 input[size='3'] { width: 1.95em; } .em65 input[size='4'] { width: 2.6em; } .em65 input[size='5'] { width: 3.25em; } .em65 input[size='6'] { width: 3.9em; } .em65 input[size='7'] { width: 4.55em; } .em65 input[size='8'] { width: 5.2em; } .em65 input[size='9'] { width: 5.85em; } .em65 input[size='10'] { width: 6.5em; } .em65 input[size='11'] { width: 7.15em; } .em65 input[size='12'] { width: 7.8em; } .em65 input[size='13'] { width: 8.45em; } .em65 input[size='14'] { width: 9.1em; } .em65 input[size='15'] { width: 9.75em; } .em65 input[size='16'] { width: 10.4em; } .em65 input[size='17'] { width: 11.05em; } .em65 input[size='18'] { width: 11.7em; } .em65 input[size='19'] { width: 12.35em; } .em65 input[size='20'] { width: 13.0em; } | |||
| .em70 input[size='1'] { width: 0.7em; } .em70 input[size='2'] { width: 1.4em; } .em70 input[size='3'] { width: 2.1em; } .em70 input[size='4'] { width: 2.8em; } .em70 input[size='5'] { width: 3.5em; } .em70 input[size='6'] { width: 4.2em; } .em70 input[size='7'] { width: 4.9em; } .em70 input[size='8'] { width: 5.6em; } .em70 input[size='9'] { width: 6.3em; } .em70 input[size='10'] { width: 7.0em; } .em70 input[size='11'] { width: 7.7em; } .em70 input[size='12'] { width: 8.4em; } .em70 input[size='13'] { width: 9.1em; } .em70 input[size='14'] { width: 9.8em; } .em70 input[size='15'] { width: 10.5em; } .em70 input[size='16'] { width: 11.2em; } .em70 input[size='17'] { width: 11.9em; } .em70 input[size='18'] { width: 12.6em; } .em70 input[size='19'] { width: 13.3em; } .em70 input[size='20'] { width: 14.0em; } | |||
| .em75 input[size='1'] { width: 0.75em; } .em75 input[size='2'] { width: 1.5em; } .em75 input[size='3'] { width: 2.25em; } .em75 input[size='4'] { width: 3.0em; } .em75 input[size='5'] { width: 3.75em; } .em75 input[size='6'] { width: 4.5em; } .em75 input[size='7'] { width: 5.25em; } .em75 input[size='8'] { width: 6.0em; } .em75 input[size='9'] { width: 6.75em; } .em75 input[size='10'] { width: 7.5em; } .em75 input[size='11'] { width: 8.25em; } .em75 input[size='12'] { width: 9.0em; } .em75 input[size='13'] { width: 9.75em; } .em75 input[size='14'] { width: 10.5em; } .em75 input[size='15'] { width: 11.25em; } .em75 input[size='16'] { width: 12.0em; } .em75 input[size='17'] { width: 12.75em; } .em75 input[size='18'] { width: 13.5em; } .em75 input[size='19'] { width: 14.25em; } .em75 input[size='20'] { width: 15.0em; } | |||
| .em80 input[size='1'] { width: 0.8em; } .em80 input[size='2'] { width: 1.6em; } .em80 input[size='3'] { width: 2.4em; } .em80 input[size='4'] { width: 3.2em; } .em80 input[size='5'] { width: 4.0em; } .em80 input[size='6'] { width: 4.8em; } .em80 input[size='7'] { width: 5.6em; } .em80 input[size='8'] { width: 6.4em; } .em80 input[size='9'] { width: 7.2em; } .em80 input[size='10'] { width: 8.0em; } .em80 input[size='11'] { width: 8.8em; } .em80 input[size='12'] { width: 9.6em; } .em80 input[size='13'] { width: 10.4em; } .em80 input[size='14'] { width: 11.2em; } .em80 input[size='15'] { width: 12.0em; } .em80 input[size='16'] { width: 12.8em; } .em80 input[size='17'] { width: 13.6em; } .em80 input[size='18'] { width: 14.4em; } .em80 input[size='19'] { width: 15.2em; } .em80 input[size='20'] { width: 16.0em; } | |||
| .em85 input[size='1'] { width: 0.85em; } .em85 input[size='2'] { width: 1.7em; } .em85 input[size='3'] { width: 2.55em; } .em85 input[size='4'] { width: 3.4em; } .em85 input[size='5'] { width: 4.25em; } .em85 input[size='6'] { width: 5.1em; } .em85 input[size='7'] { width: 5.95em; } .em85 input[size='8'] { width: 6.8em; } .em85 input[size='9'] { width: 7.65em; } .em85 input[size='10'] { width: 8.5em; } .em85 input[size='11'] { width: 9.35em; } .em85 input[size='12'] { width: 10.2em; } .em85 input[size='13'] { width: 11.05em; } .em85 input[size='14'] { width: 11.9em; } .em85 input[size='15'] { width: 12.75em; } .em85 input[size='16'] { width: 13.6em; } .em85 input[size='17'] { width: 14.45em; } .em85 input[size='18'] { width: 15.3em; } .em85 input[size='19'] { width: 16.15em; } .em85 input[size='20'] { width: 17.0em; } | |||
| .em90 input[size='1'] { width: 0.9em; } .em90 input[size='2'] { width: 1.8em; } .em90 input[size='3'] { width: 2.7em; } .em90 input[size='4'] { width: 3.6em; } .em90 input[size='5'] { width: 4.5em; } .em90 input[size='6'] { width: 5.4em; } .em90 input[size='7'] { width: 6.3em; } .em90 input[size='8'] { width: 7.2em; } .em90 input[size='9'] { width: 8.1em; } .em90 input[size='10'] { width: 9.0em; } .em90 input[size='11'] { width: 9.9em; } .em90 input[size='12'] { width: 10.8em; } .em90 input[size='13'] { width: 11.7em; } .em90 input[size='14'] { width: 12.6em; } .em90 input[size='15'] { width: 13.5em; } .em90 input[size='16'] { width: 14.4em; } .em90 input[size='17'] { width: 15.3em; } .em90 input[size='18'] { width: 16.2em; } .em90 input[size='19'] { width: 17.1em; } .em90 input[size='20'] { width: 18.0em; } | |||
| .em95 input[size='1'] { width: 0.95em; } .em95 input[size='2'] { width: 1.9em; } .em95 input[size='3'] { width: 2.85em; } .em95 input[size='4'] { width: 3.8em; } .em95 input[size='5'] { width: 4.75em; } .em95 input[size='6'] { width: 5.7em; } .em95 input[size='7'] { width: 6.65em; } .em95 input[size='8'] { width: 7.6em; } .em95 input[size='9'] { width: 8.55em; } .em95 input[size='10'] { width: 9.5em; } .em95 input[size='11'] { width: 10.45em; } .em95 input[size='12'] { width: 11.4em; } .em95 input[size='13'] { width: 12.35em; } .em95 input[size='14'] { width: 13.3em; } .em95 input[size='15'] { width: 14.25em; } .em95 input[size='16'] { width: 15.2em; } .em95 input[size='17'] { width: 16.15em; } .em95 input[size='18'] { width: 17.1em; } .em95 input[size='19'] { width: 18.05em; } .em95 input[size='20'] { width: 19.0em; } | |||
| .em100 input[size='1'] { width: 1.0em; } .em100 input[size='2'] { width: 2.0em; } .em100 input[size='3'] { width: 3.0em; } .em100 input[size='4'] { width: 4.0em; } .em100 input[size='5'] { width: 5.0em; } .em100 input[size='6'] { width: 6.0em; } .em100 input[size='7'] { width: 7.0em; } .em100 input[size='8'] { width: 8.0em; } .em100 input[size='9'] { width: 9.0em; } .em100 input[size='10'] { width: 10.0em; } .em100 input[size='11'] { width: 11.0em; } .em100 input[size='12'] { width: 12.0em; } .em100 input[size='13'] { width: 13.0em; } .em100 input[size='14'] { width: 14.0em; } .em100 input[size='15'] { width: 15.0em; } .em100 input[size='16'] { width: 16.0em; } .em100 input[size='17'] { width: 17.0em; } .em100 input[size='18'] { width: 18.0em; } .em100 input[size='19'] { width: 19.0em; } .em100 input[size='20'] { width: 20.0em; } | |||
| input.Folded { cursor: default; } | |||
| .Operator { color: #C678DD; } | |||
| .Type { color: #E5C07B; } | |||
| .Constant { color: #56B6C2; } | |||
| .String { color: #98C379; } | |||
| .Include { color: #61AFEF; } | |||
| .Special { color: #61AFEF; } | |||
| .Float { color: #D19A66; } | |||
| .Keyword { color: #E06C75; } | |||
| --> | |||
| </style> | |||
| <script type='text/javascript'> | |||
| <!-- | |||
| /* simulate a "ch" unit by asking the browser how big a zero character is */ | |||
| function FixCharWidth() { | |||
| /* get the hidden element which gives the width of a single character */ | |||
| var goodWidth = document.getElementById("oneCharWidth").clientWidth; | |||
| /* get all input elements, we'll filter on class later */ | |||
| var inputTags = document.getElementsByTagName("input"); | |||
| var ratio = 5; | |||
| var inputWidth = document.getElementById("oneInputWidth").clientWidth; | |||
| var emWidth = document.getElementById("oneEmWidth").clientWidth; | |||
| if (inputWidth > goodWidth) { | |||
| while (ratio < 100*goodWidth/emWidth && ratio < 100) { | |||
| ratio += 5; | |||
| } | |||
| document.getElementById("vimCodeElement").className = "em"+ratio; | |||
| } | |||
| } | |||
| --> | |||
| </script> | |||
| </head> | |||
| <body onload='FixCharWidth();'> | |||
| <!-- hidden divs used by javascript to get the width of a char --> | |||
| <div id='oneCharWidth'>0</div> | |||
| <div id='oneInputWidth'><input size='1' value='0'></div> | |||
| <div id='oneEmWidth' style='width: 1em;'></div> | |||
| <pre id='vimCodeElement'> | |||
| <span class="Keyword">external</span> <span class="Keyword">val</span> print <span class="Operator">:</span> <span class="Type">'a</span> <span class="Operator">-></span> <span class="Special">unit</span> <span class="Operator">=</span> <span class="String">"print"</span> | |||
| <span class="Keyword">let</span> id x <span class="Operator">=</span> x | |||
| <span class="Keyword">let</span> f <span class="Operator">&</span> g <span class="Operator">=</span> <span class="Keyword">fun</span> x <span class="Operator">-></span> f <span class="Keyword">(</span>g x<span class="Keyword">)</span> | |||
| <span class="Keyword">let</span> const x <span class="Keyword">_</span> <span class="Operator">=</span> x | |||
| <span class="Keyword">let</span> x <span class="Operator">|</span><span class="Operator">></span> f <span class="Operator">=</span> f x | |||
| <span class="Keyword">let</span> fst <span class="Keyword">(</span>x<span class="Operator">,</span> <span class="Keyword">_</span><span class="Keyword">)</span> <span class="Operator">=</span> x | |||
| <span class="Keyword">let</span> snd <span class="Keyword">(</span><span class="Keyword">_</span><span class="Operator">,</span> x<span class="Keyword">)</span> <span class="Operator">=</span> x | |||
| <span class="Keyword">let</span> uncurry f <span class="Keyword">(</span>x<span class="Operator">,</span> y<span class="Keyword">)</span> <span class="Operator">=</span> f x y | |||
| <span class="Keyword">let</span> fork f g x <span class="Operator">=</span> <span class="Keyword">(</span>f x<span class="Operator">,</span> g x<span class="Keyword">)</span> | |||
| <span class="Keyword">class</span> profunctor <span class="Type">'p</span> <span class="Keyword">begin</span> | |||
| <span class="Keyword">val</span> dimap <span class="Operator">:</span> <span class="Keyword">forall</span> <span class="Type">'a</span> <span class="Type">'b</span> <span class="Type">'c</span> <span class="Type">'d</span><span class="Operator">.</span> <span class="Keyword">(</span><span class="Type">'b</span> <span class="Operator">-></span> <span class="Type">'a</span><span class="Keyword">)</span> <span class="Operator">-></span> <span class="Keyword">(</span><span class="Type">'c</span> <span class="Operator">-></span> <span class="Type">'d</span><span class="Keyword">)</span> | |||
| <span class="Operator">-></span> <span class="Type">'p</span> <span class="Type">'a</span> <span class="Type">'c</span> <span class="Operator">-></span> <span class="Type">'p</span> <span class="Type">'b</span> <span class="Type">'d</span> | |||
| <span class="Keyword">end</span> | |||
| <span class="Keyword">let</span> lmap g <span class="Operator">=</span> dimap g id | |||
| <span class="Keyword">let</span> rmap x <span class="Operator">=</span> dimap id x | |||
| <span class="Keyword">class</span> profunctor <span class="Type">'p</span> <span class="Operator">=</span><span class="Operator">></span> strong <span class="Type">'p</span> <span class="Keyword">begin</span> | |||
| <span class="Keyword">val</span> first <span class="Operator">:</span> <span class="Keyword">forall</span> <span class="Type">'a</span> <span class="Type">'b</span> <span class="Type">'c</span><span class="Operator">.</span> <span class="Type">'p</span> <span class="Type">'a</span> <span class="Type">'b</span> <span class="Operator">-></span> <span class="Type">'p</span> <span class="Keyword">(</span><span class="Type">'a</span> <span class="Operator">*</span> <span class="Type">'c</span><span class="Keyword">)</span> <span class="Keyword">(</span><span class="Type">'b</span> <span class="Operator">*</span> <span class="Type">'c</span><span class="Keyword">)</span> | |||
| <span class="Keyword">val</span> second <span class="Operator">:</span> <span class="Keyword">forall</span> <span class="Type">'a</span> <span class="Type">'b</span> <span class="Type">'c</span><span class="Operator">.</span> <span class="Type">'p</span> <span class="Type">'a</span> <span class="Type">'b</span> <span class="Operator">-></span> <span class="Type">'p</span> <span class="Keyword">(</span><span class="Type">'c</span> <span class="Operator">*</span> <span class="Type">'a</span><span class="Keyword">)</span> <span class="Keyword">(</span><span class="Type">'c</span> <span class="Operator">*</span> <span class="Type">'b</span><span class="Keyword">)</span> | |||
| <span class="Keyword">end</span> | |||
| <span class="Keyword">type</span> <span class="Special">either</span> <span class="Type">'l</span> <span class="Type">'r</span> <span class="Operator">=</span> <span class="Constant">Left</span> <span class="Keyword">of</span> <span class="Type">'l</span> <span class="Operator">|</span> <span class="Constant">Right</span> <span class="Keyword">of</span> <span class="Type">'r</span> | |||
| <span class="Keyword">let</span> <span class="Special">either</span> f g <span class="Operator">=</span> <span class="Keyword">function</span> | |||
| <span class="Operator">|</span> <span class="Constant">Left</span> x <span class="Operator">-></span> f x | |||
| <span class="Operator">|</span> <span class="Constant">Right</span> y <span class="Operator">-></span> g y | |||
| <span class="Keyword">class</span> profunctor <span class="Type">'p</span> <span class="Operator">=</span><span class="Operator">></span> choice <span class="Type">'p</span> <span class="Keyword">begin</span> | |||
| <span class="Keyword">val</span> left <span class="Operator">:</span> <span class="Keyword">forall</span> <span class="Type">'a</span> <span class="Type">'b</span> <span class="Type">'c</span><span class="Operator">.</span> <span class="Type">'p</span> <span class="Type">'a</span> <span class="Type">'b</span> | |||
| <span class="Operator">-></span> <span class="Type">'p</span> <span class="Keyword">(</span><span class="Special">either</span> <span class="Type">'a</span> <span class="Type">'c</span><span class="Keyword">)</span> <span class="Keyword">(</span><span class="Special">either</span> <span class="Type">'b</span> <span class="Type">'c</span><span class="Keyword">)</span> | |||
| <span class="Keyword">val</span> right <span class="Operator">:</span> <span class="Keyword">forall</span> <span class="Type">'a</span> <span class="Type">'b</span> <span class="Type">'c</span><span class="Operator">.</span> <span class="Type">'p</span> <span class="Type">'a</span> <span class="Type">'b</span> | |||
| <span class="Operator">-></span> <span class="Type">'p</span> <span class="Keyword">(</span><span class="Special">either</span> <span class="Type">'c</span> <span class="Type">'a</span><span class="Keyword">)</span> <span class="Keyword">(</span><span class="Special">either</span> <span class="Type">'c</span> <span class="Type">'b</span><span class="Keyword">)</span> | |||
| <span class="Keyword">end</span> | |||
| <span class="Keyword">class</span> monoid <span class="Type">'m</span> <span class="Keyword">begin</span> | |||
| <span class="Keyword">val</span> <span class="Keyword">(</span><span class="Operator"><></span><span class="Keyword">)</span> <span class="Operator">:</span> <span class="Type">'m</span> <span class="Operator">-></span> <span class="Type">'m</span> <span class="Operator">-></span> <span class="Type">'m</span> | |||
| <span class="Keyword">val</span> zero <span class="Operator">:</span> <span class="Type">'m</span> | |||
| <span class="Keyword">end</span> | |||
| <span class="Keyword">type</span> forget <span class="Type">'r</span> <span class="Type">'a</span> <span class="Type">'b</span> <span class="Operator">=</span> <span class="Constant">Forget</span> <span class="Keyword">of</span> <span class="Type">'a</span> <span class="Operator">-></span> <span class="Type">'r</span> | |||
| <span class="Keyword">let</span> remember <span class="Keyword">(</span><span class="Constant">Forget</span> r<span class="Keyword">)</span> <span class="Operator">=</span> r | |||
| <span class="Keyword">instance</span> profunctor <span class="Keyword">(</span><span class="Operator">-></span><span class="Keyword">)</span> | |||
| <span class="Keyword">let</span> dimap f g h <span class="Operator">=</span> g <span class="Operator">&</span> h <span class="Operator">&</span> f | |||
| <span class="Keyword">instance</span> strong <span class="Keyword">(</span><span class="Operator">-></span><span class="Keyword">)</span> | |||
| <span class="Keyword">let</span> first f <span class="Keyword">(</span>x<span class="Operator">,</span> y<span class="Keyword">)</span> <span class="Operator">=</span> <span class="Keyword">(</span>f x<span class="Operator">,</span> y<span class="Keyword">)</span> | |||
| <span class="Keyword">let</span> second f <span class="Keyword">(</span>x<span class="Operator">,</span> y<span class="Keyword">)</span> <span class="Operator">=</span> <span class="Keyword">(</span>x<span class="Operator">,</span> f y<span class="Keyword">)</span> | |||
| <span class="Keyword">instance</span> choice <span class="Keyword">(</span><span class="Operator">-></span><span class="Keyword">)</span> | |||
| <span class="Keyword">let</span> left f <span class="Operator">=</span> <span class="Special">either</span> <span class="Keyword">(</span><span class="Constant">Left</span> <span class="Operator">&</span> f<span class="Keyword">)</span> <span class="Constant">Right</span> | |||
| <span class="Keyword">let</span> right f <span class="Operator">=</span> <span class="Special">either</span> <span class="Constant">Left</span> <span class="Keyword">(</span><span class="Constant">Right</span> <span class="Operator">&</span> f<span class="Keyword">)</span> | |||
| <span class="Keyword">instance</span> profunctor <span class="Keyword">(</span>forget <span class="Type">'r</span><span class="Keyword">)</span> | |||
| <span class="Keyword">let</span> dimap f <span class="Keyword">_</span> <span class="Keyword">(</span><span class="Constant">Forget</span> g<span class="Keyword">)</span> <span class="Operator">=</span> <span class="Constant">Forget</span> <span class="Keyword">(</span>g <span class="Operator">&</span> f<span class="Keyword">)</span> | |||
| <span class="Keyword">instance</span> monoid <span class="Type">'r</span> <span class="Operator">=</span><span class="Operator">></span> choice <span class="Keyword">(</span>forget <span class="Type">'r</span><span class="Keyword">)</span> | |||
| <span class="Keyword">let</span> left <span class="Keyword">(</span><span class="Constant">Forget</span> z<span class="Keyword">)</span> <span class="Operator">=</span> <span class="Constant">Forget</span> <span class="Keyword">(</span><span class="Special">either</span> z <span class="Keyword">(</span>const zero<span class="Keyword">))</span> | |||
| <span class="Keyword">let</span> right <span class="Keyword">(</span><span class="Constant">Forget</span> z<span class="Keyword">)</span> <span class="Operator">=</span> <span class="Constant">Forget</span> <span class="Keyword">(</span><span class="Special">either</span> <span class="Keyword">(</span>const zero<span class="Keyword">)</span> z<span class="Keyword">)</span> | |||
| <span class="Keyword">instance</span> strong <span class="Keyword">(</span>forget <span class="Type">'r</span><span class="Keyword">)</span> | |||
| <span class="Keyword">let</span> first <span class="Keyword">(</span><span class="Constant">Forget</span> z<span class="Keyword">)</span> <span class="Operator">=</span> <span class="Constant">Forget</span> <span class="Keyword">(</span>z <span class="Operator">&</span> fst<span class="Keyword">)</span> | |||
| <span class="Keyword">let</span> second <span class="Keyword">(</span><span class="Constant">Forget</span> z<span class="Keyword">)</span> <span class="Operator">=</span> <span class="Constant">Forget</span> <span class="Keyword">(</span>z <span class="Operator">&</span> snd<span class="Keyword">)</span> | |||
| <span class="Keyword">let</span> lens get set <span class="Operator">=</span> | |||
| dimap <span class="Keyword">(</span>fork get id<span class="Keyword">)</span> <span class="Keyword">(</span>uncurry set<span class="Keyword">)</span> <span class="Operator">&</span> first | |||
| <span class="Keyword">let</span> view l <span class="Operator">=</span> remember <span class="Keyword">(</span>l <span class="Keyword">(</span><span class="Constant">Forget</span> id<span class="Keyword">))</span> | |||
| <span class="Keyword">let</span> over f <span class="Operator">=</span> f | |||
| <span class="Keyword">let</span> set l b <span class="Operator">=</span> over l <span class="Keyword">(</span>const b<span class="Keyword">)</span> | |||
| <span class="Keyword">type</span> pair <span class="Type">'a</span> <span class="Type">'b</span> <span class="Operator">=</span> <span class="Constant">Pair</span> <span class="Keyword">of</span> <span class="Type">'a</span> <span class="Operator">*</span> <span class="Type">'b</span> | |||
| <span class="Keyword">let</span> fst' <span class="Keyword">(</span><span class="Constant">Pair</span> <span class="Keyword">(</span>x<span class="Operator">,</span> <span class="Keyword">_</span><span class="Keyword">))</span> <span class="Operator">=</span> x | |||
| <span class="Keyword">let</span> snd' <span class="Keyword">(</span><span class="Constant">Pair</span> <span class="Keyword">(</span><span class="Keyword">_</span><span class="Operator">,</span> x<span class="Keyword">))</span> <span class="Operator">=</span> x | |||
| <span class="Keyword">let</span> first' x <span class="Operator">=</span> lens fst' <span class="Keyword">(fun</span> x <span class="Keyword">(</span><span class="Constant">Pair</span> <span class="Keyword">(</span><span class="Keyword">_</span><span class="Operator">,</span> y<span class="Keyword">))</span> <span class="Operator">-></span> <span class="Constant">Pair</span> <span class="Keyword">(</span>x<span class="Operator">,</span> y<span class="Keyword">))</span> x | |||
| <span class="Keyword">let</span> second' x <span class="Operator">=</span> lens snd' <span class="Keyword">(fun</span> y <span class="Keyword">(</span><span class="Constant">Pair</span> <span class="Keyword">(</span>x<span class="Operator">,</span> <span class="Keyword">_</span><span class="Keyword">))</span> <span class="Operator">-></span> <span class="Constant">Pair</span> <span class="Keyword">(</span>x<span class="Operator">,</span> y<span class="Keyword">))</span> x | |||
| <span class="Keyword">type</span> proxy <span class="Type">'a</span> <span class="Operator">=</span> <span class="Constant">Proxy</span> | |||
| <span class="Keyword">type</span> lens <span class="Type">'s</span> <span class="Type">'t</span> <span class="Type">'a</span> <span class="Type">'b</span> <span class="Operator"><-</span> <span class="Keyword">forall</span> <span class="Type">'p</span><span class="Operator">.</span> strong <span class="Type">'p</span> <span class="Operator">=</span><span class="Operator">></span> <span class="Type">'p</span> <span class="Type">'a</span> <span class="Type">'b</span> <span class="Operator">-></span> <span class="Type">'p</span> <span class="Type">'s</span> <span class="Type">'t</span> | |||
| <span class="Keyword">type</span> lens' <span class="Type">'s</span> <span class="Type">'a</span> <span class="Operator"><-</span> lens <span class="Type">'s</span> <span class="Type">'s</span> <span class="Type">'a</span> <span class="Type">'a</span> | |||
| <span class="Keyword">class</span> <span class="Include">Amc</span>.row_cons <span class="Type">'record</span> <span class="Type">'key</span> <span class="Type">'type</span> <span class="Type">'new</span> <span class="Operator">=</span><span class="Operator">></span> has_lens <span class="Type">'record</span> <span class="Type">'key</span> <span class="Type">'type</span> <span class="Type">'new</span> <span class="Operator">|</span> <span class="Type">'key</span> <span class="Type">'new</span> <span class="Operator">-></span> <span class="Type">'record</span> <span class="Type">'type</span> <span class="Keyword">begin</span> | |||
| <span class="Keyword">val</span> rlens <span class="Operator">:</span> <span class="Keyword">forall</span> <span class="Type">'p</span><span class="Operator">.</span> strong <span class="Type">'p</span> <span class="Operator">=</span><span class="Operator">></span> proxy <span class="Type">'key</span> <span class="Operator">-></span> <span class="Type">'p</span> <span class="Type">'type</span> <span class="Type">'type</span> <span class="Operator">-></span> <span class="Type">'p</span> <span class="Type">'new</span> <span class="Type">'new</span> | |||
| <span class="Keyword">end</span> | |||
| <span class="Keyword">instance</span> <span class="Include">Amc</span>.known_string <span class="Type">'key</span> <span class="Operator">*</span> <span class="Include">Amc</span>.row_cons <span class="Type">'record</span> <span class="Type">'key</span> <span class="Type">'type</span> <span class="Type">'new</span> <span class="Operator">=</span><span class="Operator">></span> has_lens <span class="Type">'record</span> <span class="Type">'key</span> <span class="Type">'type</span> <span class="Type">'new</span> <span class="Keyword">begin</span> | |||
| <span class="Keyword">let</span> rlens <span class="Keyword">_</span> <span class="Operator">=</span> | |||
| <span class="Keyword">let</span> view r <span class="Operator">=</span> | |||
| <span class="Keyword">let</span> <span class="Keyword">(</span>x<span class="Operator">,</span> <span class="Keyword">_</span><span class="Keyword">)</span> <span class="Operator">=</span> <span class="Include">Amc</span>.restrict_row <span class="Operator">@</span><span class="Type">'key</span> r | |||
| x | |||
| <span class="Keyword">let</span> set x r <span class="Operator">=</span> | |||
| <span class="Keyword">let</span> <span class="Keyword">(</span><span class="Keyword">_</span><span class="Operator">,</span> r'<span class="Keyword">)</span> <span class="Operator">=</span> <span class="Include">Amc</span>.restrict_row <span class="Operator">@</span><span class="Type">'key</span> r | |||
| <span class="Include">Amc</span>.extend_row <span class="Operator">@</span><span class="Type">'key</span> x r' | |||
| lens view set | |||
| <span class="Keyword">end</span> | |||
| <span class="Keyword">let</span> r <span class="Operator">:</span> <span class="Keyword">forall</span> <span class="Type">'key</span> <span class="Operator">-></span> <span class="Keyword">forall</span> <span class="Type">'record</span> <span class="Type">'type</span> <span class="Type">'new</span> <span class="Type">'p</span><span class="Operator">.</span> <span class="Include">Amc</span>.known_string <span class="Type">'key</span> <span class="Operator">*</span> has_lens <span class="Type">'record</span> <span class="Type">'key</span> <span class="Type">'type</span> <span class="Type">'new</span> <span class="Operator">*</span> strong <span class="Type">'p</span> <span class="Operator">=</span><span class="Operator">></span> <span class="Type">'p</span> <span class="Type">'type</span> <span class="Type">'type</span> <span class="Operator">-></span> <span class="Type">'p</span> <span class="Type">'new</span> <span class="Type">'new</span> <span class="Operator">=</span> | |||
| <span class="Keyword">fun</span> x <span class="Operator">-></span> rlens <span class="Operator">@</span><span class="Type">'record</span> <span class="Keyword">(</span><span class="Constant">Proxy</span> <span class="Operator">:</span> proxy <span class="Type">'key</span><span class="Keyword">)</span> x | |||
| <span class="Keyword">let</span> x <span class="Operator">::</span> xs <span class="Operator">=</span> <span class="Constant">Cons</span> <span class="Keyword">(</span>x<span class="Operator">,</span> xs<span class="Keyword">)</span> | |||
| <span class="Keyword">let</span> lens_list <span class="Constant">()</span> <span class="Operator">=</span> <span class="Keyword">(fun</span> x <span class="Operator">-></span> r <span class="Operator">@</span><span class="String">"foo"</span> x<span class="Keyword">)</span> <span class="Operator">::</span> <span class="Keyword">(fun</span> x <span class="Operator">-></span> r <span class="Operator">@</span><span class="String">"bar"</span> x<span class="Keyword">)</span> <span class="Operator">::</span> <span class="Constant">Nil</span> <span class="Operator">@</span><span class="Keyword">(</span>lens' <span class="Keyword">_</span> <span class="Keyword">_</span><span class="Keyword">)</span> | |||
| <span class="Keyword">let</span> map f xs <span class="Operator">=</span> <span class="Keyword">[</span> f x <span class="Operator">|</span> <span class="Keyword">with</span> x <span class="Operator"><-</span> xs <span class="Keyword">]</span> | |||
| <span class="Keyword">let</span> x <span class="Operator">=</span> <span class="Keyword">{</span> foo <span class="Operator">=</span> <span class="Float">1</span><span class="Operator">,</span> bar <span class="Operator">=</span> <span class="Float">2</span> <span class="Keyword">}</span> | |||
| <span class="Keyword">let</span> xs <span class="Operator">=</span> map <span class="Keyword">(</span>`view` x<span class="Keyword">)</span> <span class="Keyword">(</span>lens_list <span class="Constant">()</span><span class="Keyword">)</span> | |||
| </pre> | |||
| </body> | |||
| </html> | |||
| <!-- vim: set foldmethod=manual : --> | |||
+ 224
- 0
static/profunctors.ml.html
View File
| @ -0,0 +1,224 @@ | |||
| <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd"> | |||
| <html> | |||
| <head> | |||
| <meta http-equiv="content-type" content="text/html; charset=UTF-8"> | |||
| <title>~/Projects/amulet/profunctors.ml.html</title> | |||
| <meta name="Generator" content="Vim/8.0"> | |||
| <meta name="plugin-version" content="vim8.1_v1"> | |||
| <meta name="syntax" content="amulet"> | |||
| <meta name="settings" content="use_css,pre_wrap,no_foldcolumn,expand_tabs,prevent_copy=t"> | |||
| <meta name="colorscheme" content="onedark"> | |||
| <style type="text/css"> | |||
| <!-- | |||
| pre { white-space: pre-wrap; font-family: 'Iosevka','Iosevka Term', monospace; color: #ABB2BF; background-color: #282C34; } | |||
| body { font-family: 'Iosevka','Iosevka Term', monospace; color: #ABB2BF; background-color: #282C34; } | |||
| * { font-size: 1em; } | |||
| input { border: none; margin: 0; padding: 0; font-family: 'Iosevka','Iosevka Term', monospace; } | |||
| input[size='1'] { width: 1em; width: 1ch; } | |||
| input[size='2'] { width: 2em; width: 2ch; } | |||
| input[size='3'] { width: 3em; width: 3ch; } | |||
| input[size='4'] { width: 4em; width: 4ch; } | |||
| input[size='5'] { width: 5em; width: 5ch; } | |||
| input[size='6'] { width: 6em; width: 6ch; } | |||
| input[size='7'] { width: 7em; width: 7ch; } | |||
| input[size='8'] { width: 8em; width: 8ch; } | |||
| input[size='9'] { width: 9em; width: 9ch; } | |||
| input[size='10'] { width: 10em; width: 10ch; } | |||
| input[size='11'] { width: 11em; width: 11ch; } | |||
| input[size='12'] { width: 12em; width: 12ch; } | |||
| input[size='13'] { width: 13em; width: 13ch; } | |||
| input[size='14'] { width: 14em; width: 14ch; } | |||
| input[size='15'] { width: 15em; width: 15ch; } | |||
| input[size='16'] { width: 16em; width: 16ch; } | |||
| input[size='17'] { width: 17em; width: 17ch; } | |||
| input[size='18'] { width: 18em; width: 18ch; } | |||
| input[size='19'] { width: 19em; width: 19ch; } | |||
| input[size='20'] { width: 20em; width: 20ch; } | |||
| #oneCharWidth, #oneEmWidth, #oneInputWidth { padding: 0; margin: 0; position: absolute; left: -999999px; visibility: hidden; } | |||
| .em5 input[size='1'] { width: 0.05em; } .em5 input[size='2'] { width: 0.1em; } .em5 input[size='3'] { width: 0.15em; } .em5 input[size='4'] { width: 0.2em; } .em5 input[size='5'] { width: 0.25em; } .em5 input[size='6'] { width: 0.3em; } .em5 input[size='7'] { width: 0.35em; } .em5 input[size='8'] { width: 0.4em; } .em5 input[size='9'] { width: 0.45em; } .em5 input[size='10'] { width: 0.5em; } .em5 input[size='11'] { width: 0.55em; } .em5 input[size='12'] { width: 0.6em; } .em5 input[size='13'] { width: 0.65em; } .em5 input[size='14'] { width: 0.7em; } .em5 input[size='15'] { width: 0.75em; } .em5 input[size='16'] { width: 0.8em; } .em5 input[size='17'] { width: 0.85em; } .em5 input[size='18'] { width: 0.9em; } .em5 input[size='19'] { width: 0.95em; } .em5 input[size='20'] { width: 1.0em; } | |||
| .em10 input[size='1'] { width: 0.1em; } .em10 input[size='2'] { width: 0.2em; } .em10 input[size='3'] { width: 0.3em; } .em10 input[size='4'] { width: 0.4em; } .em10 input[size='5'] { width: 0.5em; } .em10 input[size='6'] { width: 0.6em; } .em10 input[size='7'] { width: 0.7em; } .em10 input[size='8'] { width: 0.8em; } .em10 input[size='9'] { width: 0.9em; } .em10 input[size='10'] { width: 1.0em; } .em10 input[size='11'] { width: 1.1em; } .em10 input[size='12'] { width: 1.2em; } .em10 input[size='13'] { width: 1.3em; } .em10 input[size='14'] { width: 1.4em; } .em10 input[size='15'] { width: 1.5em; } .em10 input[size='16'] { width: 1.6em; } .em10 input[size='17'] { width: 1.7em; } .em10 input[size='18'] { width: 1.8em; } .em10 input[size='19'] { width: 1.9em; } .em10 input[size='20'] { width: 2.0em; } | |||
| .em15 input[size='1'] { width: 0.15em; } .em15 input[size='2'] { width: 0.3em; } .em15 input[size='3'] { width: 0.45em; } .em15 input[size='4'] { width: 0.6em; } .em15 input[size='5'] { width: 0.75em; } .em15 input[size='6'] { width: 0.9em; } .em15 input[size='7'] { width: 1.05em; } .em15 input[size='8'] { width: 1.2em; } .em15 input[size='9'] { width: 1.35em; } .em15 input[size='10'] { width: 1.5em; } .em15 input[size='11'] { width: 1.65em; } .em15 input[size='12'] { width: 1.8em; } .em15 input[size='13'] { width: 1.95em; } .em15 input[size='14'] { width: 2.1em; } .em15 input[size='15'] { width: 2.25em; } .em15 input[size='16'] { width: 2.4em; } .em15 input[size='17'] { width: 2.55em; } .em15 input[size='18'] { width: 2.7em; } .em15 input[size='19'] { width: 2.85em; } .em15 input[size='20'] { width: 3.0em; } | |||
| .em20 input[size='1'] { width: 0.2em; } .em20 input[size='2'] { width: 0.4em; } .em20 input[size='3'] { width: 0.6em; } .em20 input[size='4'] { width: 0.8em; } .em20 input[size='5'] { width: 1.0em; } .em20 input[size='6'] { width: 1.2em; } .em20 input[size='7'] { width: 1.4em; } .em20 input[size='8'] { width: 1.6em; } .em20 input[size='9'] { width: 1.8em; } .em20 input[size='10'] { width: 2.0em; } .em20 input[size='11'] { width: 2.2em; } .em20 input[size='12'] { width: 2.4em; } .em20 input[size='13'] { width: 2.6em; } .em20 input[size='14'] { width: 2.8em; } .em20 input[size='15'] { width: 3.0em; } .em20 input[size='16'] { width: 3.2em; } .em20 input[size='17'] { width: 3.4em; } .em20 input[size='18'] { width: 3.6em; } .em20 input[size='19'] { width: 3.8em; } .em20 input[size='20'] { width: 4.0em; } | |||
| .em25 input[size='1'] { width: 0.25em; } .em25 input[size='2'] { width: 0.5em; } .em25 input[size='3'] { width: 0.75em; } .em25 input[size='4'] { width: 1.0em; } .em25 input[size='5'] { width: 1.25em; } .em25 input[size='6'] { width: 1.5em; } .em25 input[size='7'] { width: 1.75em; } .em25 input[size='8'] { width: 2.0em; } .em25 input[size='9'] { width: 2.25em; } .em25 input[size='10'] { width: 2.5em; } .em25 input[size='11'] { width: 2.75em; } .em25 input[size='12'] { width: 3.0em; } .em25 input[size='13'] { width: 3.25em; } .em25 input[size='14'] { width: 3.5em; } .em25 input[size='15'] { width: 3.75em; } .em25 input[size='16'] { width: 4.0em; } .em25 input[size='17'] { width: 4.25em; } .em25 input[size='18'] { width: 4.5em; } .em25 input[size='19'] { width: 4.75em; } .em25 input[size='20'] { width: 5.0em; } | |||
| .em30 input[size='1'] { width: 0.3em; } .em30 input[size='2'] { width: 0.6em; } .em30 input[size='3'] { width: 0.9em; } .em30 input[size='4'] { width: 1.2em; } .em30 input[size='5'] { width: 1.5em; } .em30 input[size='6'] { width: 1.8em; } .em30 input[size='7'] { width: 2.1em; } .em30 input[size='8'] { width: 2.4em; } .em30 input[size='9'] { width: 2.7em; } .em30 input[size='10'] { width: 3.0em; } .em30 input[size='11'] { width: 3.3em; } .em30 input[size='12'] { width: 3.6em; } .em30 input[size='13'] { width: 3.9em; } .em30 input[size='14'] { width: 4.2em; } .em30 input[size='15'] { width: 4.5em; } .em30 input[size='16'] { width: 4.8em; } .em30 input[size='17'] { width: 5.1em; } .em30 input[size='18'] { width: 5.4em; } .em30 input[size='19'] { width: 5.7em; } .em30 input[size='20'] { width: 6.0em; } | |||
| .em35 input[size='1'] { width: 0.35em; } .em35 input[size='2'] { width: 0.7em; } .em35 input[size='3'] { width: 1.05em; } .em35 input[size='4'] { width: 1.4em; } .em35 input[size='5'] { width: 1.75em; } .em35 input[size='6'] { width: 2.1em; } .em35 input[size='7'] { width: 2.45em; } .em35 input[size='8'] { width: 2.8em; } .em35 input[size='9'] { width: 3.15em; } .em35 input[size='10'] { width: 3.5em; } .em35 input[size='11'] { width: 3.85em; } .em35 input[size='12'] { width: 4.2em; } .em35 input[size='13'] { width: 4.55em; } .em35 input[size='14'] { width: 4.9em; } .em35 input[size='15'] { width: 5.25em; } .em35 input[size='16'] { width: 5.6em; } .em35 input[size='17'] { width: 5.95em; } .em35 input[size='18'] { width: 6.3em; } .em35 input[size='19'] { width: 6.65em; } .em35 input[size='20'] { width: 7.0em; } | |||
| .em40 input[size='1'] { width: 0.4em; } .em40 input[size='2'] { width: 0.8em; } .em40 input[size='3'] { width: 1.2em; } .em40 input[size='4'] { width: 1.6em; } .em40 input[size='5'] { width: 2.0em; } .em40 input[size='6'] { width: 2.4em; } .em40 input[size='7'] { width: 2.8em; } .em40 input[size='8'] { width: 3.2em; } .em40 input[size='9'] { width: 3.6em; } .em40 input[size='10'] { width: 4.0em; } .em40 input[size='11'] { width: 4.4em; } .em40 input[size='12'] { width: 4.8em; } .em40 input[size='13'] { width: 5.2em; } .em40 input[size='14'] { width: 5.6em; } .em40 input[size='15'] { width: 6.0em; } .em40 input[size='16'] { width: 6.4em; } .em40 input[size='17'] { width: 6.8em; } .em40 input[size='18'] { width: 7.2em; } .em40 input[size='19'] { width: 7.6em; } .em40 input[size='20'] { width: 8.0em; } | |||
| .em45 input[size='1'] { width: 0.45em; } .em45 input[size='2'] { width: 0.9em; } .em45 input[size='3'] { width: 1.35em; } .em45 input[size='4'] { width: 1.8em; } .em45 input[size='5'] { width: 2.25em; } .em45 input[size='6'] { width: 2.7em; } .em45 input[size='7'] { width: 3.15em; } .em45 input[size='8'] { width: 3.6em; } .em45 input[size='9'] { width: 4.05em; } .em45 input[size='10'] { width: 4.5em; } .em45 input[size='11'] { width: 4.95em; } .em45 input[size='12'] { width: 5.4em; } .em45 input[size='13'] { width: 5.85em; } .em45 input[size='14'] { width: 6.3em; } .em45 input[size='15'] { width: 6.75em; } .em45 input[size='16'] { width: 7.2em; } .em45 input[size='17'] { width: 7.65em; } .em45 input[size='18'] { width: 8.1em; } .em45 input[size='19'] { width: 8.55em; } .em45 input[size='20'] { width: 9.0em; } | |||
| .em50 input[size='1'] { width: 0.5em; } .em50 input[size='2'] { width: 1.0em; } .em50 input[size='3'] { width: 1.5em; } .em50 input[size='4'] { width: 2.0em; } .em50 input[size='5'] { width: 2.5em; } .em50 input[size='6'] { width: 3.0em; } .em50 input[size='7'] { width: 3.5em; } .em50 input[size='8'] { width: 4.0em; } .em50 input[size='9'] { width: 4.5em; } .em50 input[size='10'] { width: 5.0em; } .em50 input[size='11'] { width: 5.5em; } .em50 input[size='12'] { width: 6.0em; } .em50 input[size='13'] { width: 6.5em; } .em50 input[size='14'] { width: 7.0em; } .em50 input[size='15'] { width: 7.5em; } .em50 input[size='16'] { width: 8.0em; } .em50 input[size='17'] { width: 8.5em; } .em50 input[size='18'] { width: 9.0em; } .em50 input[size='19'] { width: 9.5em; } .em50 input[size='20'] { width: 10.0em; } | |||
| .em55 input[size='1'] { width: 0.55em; } .em55 input[size='2'] { width: 1.1em; } .em55 input[size='3'] { width: 1.65em; } .em55 input[size='4'] { width: 2.2em; } .em55 input[size='5'] { width: 2.75em; } .em55 input[size='6'] { width: 3.3em; } .em55 input[size='7'] { width: 3.85em; } .em55 input[size='8'] { width: 4.4em; } .em55 input[size='9'] { width: 4.95em; } .em55 input[size='10'] { width: 5.5em; } .em55 input[size='11'] { width: 6.05em; } .em55 input[size='12'] { width: 6.6em; } .em55 input[size='13'] { width: 7.15em; } .em55 input[size='14'] { width: 7.7em; } .em55 input[size='15'] { width: 8.25em; } .em55 input[size='16'] { width: 8.8em; } .em55 input[size='17'] { width: 9.35em; } .em55 input[size='18'] { width: 9.9em; } .em55 input[size='19'] { width: 10.45em; } .em55 input[size='20'] { width: 11.0em; } | |||
| .em60 input[size='1'] { width: 0.6em; } .em60 input[size='2'] { width: 1.2em; } .em60 input[size='3'] { width: 1.8em; } .em60 input[size='4'] { width: 2.4em; } .em60 input[size='5'] { width: 3.0em; } .em60 input[size='6'] { width: 3.6em; } .em60 input[size='7'] { width: 4.2em; } .em60 input[size='8'] { width: 4.8em; } .em60 input[size='9'] { width: 5.4em; } .em60 input[size='10'] { width: 6.0em; } .em60 input[size='11'] { width: 6.6em; } .em60 input[size='12'] { width: 7.2em; } .em60 input[size='13'] { width: 7.8em; } .em60 input[size='14'] { width: 8.4em; } .em60 input[size='15'] { width: 9.0em; } .em60 input[size='16'] { width: 9.6em; } .em60 input[size='17'] { width: 10.2em; } .em60 input[size='18'] { width: 10.8em; } .em60 input[size='19'] { width: 11.4em; } .em60 input[size='20'] { width: 12.0em; } | |||
| .em65 input[size='1'] { width: 0.65em; } .em65 input[size='2'] { width: 1.3em; } .em65 input[size='3'] { width: 1.95em; } .em65 input[size='4'] { width: 2.6em; } .em65 input[size='5'] { width: 3.25em; } .em65 input[size='6'] { width: 3.9em; } .em65 input[size='7'] { width: 4.55em; } .em65 input[size='8'] { width: 5.2em; } .em65 input[size='9'] { width: 5.85em; } .em65 input[size='10'] { width: 6.5em; } .em65 input[size='11'] { width: 7.15em; } .em65 input[size='12'] { width: 7.8em; } .em65 input[size='13'] { width: 8.45em; } .em65 input[size='14'] { width: 9.1em; } .em65 input[size='15'] { width: 9.75em; } .em65 input[size='16'] { width: 10.4em; } .em65 input[size='17'] { width: 11.05em; } .em65 input[size='18'] { width: 11.7em; } .em65 input[size='19'] { width: 12.35em; } .em65 input[size='20'] { width: 13.0em; } | |||
| .em70 input[size='1'] { width: 0.7em; } .em70 input[size='2'] { width: 1.4em; } .em70 input[size='3'] { width: 2.1em; } .em70 input[size='4'] { width: 2.8em; } .em70 input[size='5'] { width: 3.5em; } .em70 input[size='6'] { width: 4.2em; } .em70 input[size='7'] { width: 4.9em; } .em70 input[size='8'] { width: 5.6em; } .em70 input[size='9'] { width: 6.3em; } .em70 input[size='10'] { width: 7.0em; } .em70 input[size='11'] { width: 7.7em; } .em70 input[size='12'] { width: 8.4em; } .em70 input[size='13'] { width: 9.1em; } .em70 input[size='14'] { width: 9.8em; } .em70 input[size='15'] { width: 10.5em; } .em70 input[size='16'] { width: 11.2em; } .em70 input[size='17'] { width: 11.9em; } .em70 input[size='18'] { width: 12.6em; } .em70 input[size='19'] { width: 13.3em; } .em70 input[size='20'] { width: 14.0em; } | |||
| .em75 input[size='1'] { width: 0.75em; } .em75 input[size='2'] { width: 1.5em; } .em75 input[size='3'] { width: 2.25em; } .em75 input[size='4'] { width: 3.0em; } .em75 input[size='5'] { width: 3.75em; } .em75 input[size='6'] { width: 4.5em; } .em75 input[size='7'] { width: 5.25em; } .em75 input[size='8'] { width: 6.0em; } .em75 input[size='9'] { width: 6.75em; } .em75 input[size='10'] { width: 7.5em; } .em75 input[size='11'] { width: 8.25em; } .em75 input[size='12'] { width: 9.0em; } .em75 input[size='13'] { width: 9.75em; } .em75 input[size='14'] { width: 10.5em; } .em75 input[size='15'] { width: 11.25em; } .em75 input[size='16'] { width: 12.0em; } .em75 input[size='17'] { width: 12.75em; } .em75 input[size='18'] { width: 13.5em; } .em75 input[size='19'] { width: 14.25em; } .em75 input[size='20'] { width: 15.0em; } | |||
| .em80 input[size='1'] { width: 0.8em; } .em80 input[size='2'] { width: 1.6em; } .em80 input[size='3'] { width: 2.4em; } .em80 input[size='4'] { width: 3.2em; } .em80 input[size='5'] { width: 4.0em; } .em80 input[size='6'] { width: 4.8em; } .em80 input[size='7'] { width: 5.6em; } .em80 input[size='8'] { width: 6.4em; } .em80 input[size='9'] { width: 7.2em; } .em80 input[size='10'] { width: 8.0em; } .em80 input[size='11'] { width: 8.8em; } .em80 input[size='12'] { width: 9.6em; } .em80 input[size='13'] { width: 10.4em; } .em80 input[size='14'] { width: 11.2em; } .em80 input[size='15'] { width: 12.0em; } .em80 input[size='16'] { width: 12.8em; } .em80 input[size='17'] { width: 13.6em; } .em80 input[size='18'] { width: 14.4em; } .em80 input[size='19'] { width: 15.2em; } .em80 input[size='20'] { width: 16.0em; } | |||
| .em85 input[size='1'] { width: 0.85em; } .em85 input[size='2'] { width: 1.7em; } .em85 input[size='3'] { width: 2.55em; } .em85 input[size='4'] { width: 3.4em; } .em85 input[size='5'] { width: 4.25em; } .em85 input[size='6'] { width: 5.1em; } .em85 input[size='7'] { width: 5.95em; } .em85 input[size='8'] { width: 6.8em; } .em85 input[size='9'] { width: 7.65em; } .em85 input[size='10'] { width: 8.5em; } .em85 input[size='11'] { width: 9.35em; } .em85 input[size='12'] { width: 10.2em; } .em85 input[size='13'] { width: 11.05em; } .em85 input[size='14'] { width: 11.9em; } .em85 input[size='15'] { width: 12.75em; } .em85 input[size='16'] { width: 13.6em; } .em85 input[size='17'] { width: 14.45em; } .em85 input[size='18'] { width: 15.3em; } .em85 input[size='19'] { width: 16.15em; } .em85 input[size='20'] { width: 17.0em; } | |||
| .em90 input[size='1'] { width: 0.9em; } .em90 input[size='2'] { width: 1.8em; } .em90 input[size='3'] { width: 2.7em; } .em90 input[size='4'] { width: 3.6em; } .em90 input[size='5'] { width: 4.5em; } .em90 input[size='6'] { width: 5.4em; } .em90 input[size='7'] { width: 6.3em; } .em90 input[size='8'] { width: 7.2em; } .em90 input[size='9'] { width: 8.1em; } .em90 input[size='10'] { width: 9.0em; } .em90 input[size='11'] { width: 9.9em; } .em90 input[size='12'] { width: 10.8em; } .em90 input[size='13'] { width: 11.7em; } .em90 input[size='14'] { width: 12.6em; } .em90 input[size='15'] { width: 13.5em; } .em90 input[size='16'] { width: 14.4em; } .em90 input[size='17'] { width: 15.3em; } .em90 input[size='18'] { width: 16.2em; } .em90 input[size='19'] { width: 17.1em; } .em90 input[size='20'] { width: 18.0em; } | |||
| .em95 input[size='1'] { width: 0.95em; } .em95 input[size='2'] { width: 1.9em; } .em95 input[size='3'] { width: 2.85em; } .em95 input[size='4'] { width: 3.8em; } .em95 input[size='5'] { width: 4.75em; } .em95 input[size='6'] { width: 5.7em; } .em95 input[size='7'] { width: 6.65em; } .em95 input[size='8'] { width: 7.6em; } .em95 input[size='9'] { width: 8.55em; } .em95 input[size='10'] { width: 9.5em; } .em95 input[size='11'] { width: 10.45em; } .em95 input[size='12'] { width: 11.4em; } .em95 input[size='13'] { width: 12.35em; } .em95 input[size='14'] { width: 13.3em; } .em95 input[size='15'] { width: 14.25em; } .em95 input[size='16'] { width: 15.2em; } .em95 input[size='17'] { width: 16.15em; } .em95 input[size='18'] { width: 17.1em; } .em95 input[size='19'] { width: 18.05em; } .em95 input[size='20'] { width: 19.0em; } | |||
| .em100 input[size='1'] { width: 1.0em; } .em100 input[size='2'] { width: 2.0em; } .em100 input[size='3'] { width: 3.0em; } .em100 input[size='4'] { width: 4.0em; } .em100 input[size='5'] { width: 5.0em; } .em100 input[size='6'] { width: 6.0em; } .em100 input[size='7'] { width: 7.0em; } .em100 input[size='8'] { width: 8.0em; } .em100 input[size='9'] { width: 9.0em; } .em100 input[size='10'] { width: 10.0em; } .em100 input[size='11'] { width: 11.0em; } .em100 input[size='12'] { width: 12.0em; } .em100 input[size='13'] { width: 13.0em; } .em100 input[size='14'] { width: 14.0em; } .em100 input[size='15'] { width: 15.0em; } .em100 input[size='16'] { width: 16.0em; } .em100 input[size='17'] { width: 17.0em; } .em100 input[size='18'] { width: 18.0em; } .em100 input[size='19'] { width: 19.0em; } .em100 input[size='20'] { width: 20.0em; } | |||
| input.Folded { cursor: default; } | |||
| .Operator { color: #C678DD; } | |||
| .Type { color: #E5C07B; } | |||
| .Include { color: #61AFEF; } | |||
| .Special { color: #61AFEF; } | |||
| .String { color: #98C379; } | |||
| .Float { color: #D19A66; } | |||
| .Constant { color: #56B6C2; } | |||
| .Keyword { color: #E06C75; } | |||
| --> | |||
| </style> | |||
| <script type='text/javascript'> | |||
| <!-- | |||
| /* simulate a "ch" unit by asking the browser how big a zero character is */ | |||
| function FixCharWidth() { | |||
| /* get the hidden element which gives the width of a single character */ | |||
| var goodWidth = document.getElementById("oneCharWidth").clientWidth; | |||
| /* get all input elements, we'll filter on class later */ | |||
| var inputTags = document.getElementsByTagName("input"); | |||
| var ratio = 5; | |||
| var inputWidth = document.getElementById("oneInputWidth").clientWidth; | |||
| var emWidth = document.getElementById("oneEmWidth").clientWidth; | |||
| if (inputWidth > goodWidth) { | |||
| while (ratio < 100*goodWidth/emWidth && ratio < 100) { | |||
| ratio += 5; | |||
| } | |||
| document.getElementById("vimCodeElement").className = "em"+ratio; | |||
| } | |||
| } | |||
| --> | |||
| </script> | |||
| </head> | |||
| <body onload='FixCharWidth();'> | |||
| <!-- hidden divs used by javascript to get the width of a char --> | |||
| <div id='oneCharWidth'>0</div> | |||
| <div id='oneInputWidth'><input size='1' value='0'></div> | |||
| <div id='oneEmWidth' style='width: 1em;'></div> | |||
| <pre id='vimCodeElement'> | |||
| <span class="Keyword">external</span> <span class="Keyword">val</span> print <span class="Operator">:</span> <span class="Type">'a</span> <span class="Keyword">-></span> <span class="Special">unit</span> <span class="Operator">=</span> <span class="String">"print"</span> | |||
| <span class="Keyword">let</span> id x <span class="Operator">=</span> x | |||
| <span class="Keyword">let</span> f <span class="Operator"><<<</span> g <span class="Operator">=</span> <span class="Keyword">fun</span> x <span class="Keyword">-></span> f <span class="Keyword">(</span>g x<span class="Keyword">)</span> | |||
| <span class="Keyword">let</span> const x <span class="Keyword">_</span> <span class="Operator">=</span> x | |||
| <span class="Keyword">let</span> x <span class="Operator">|</span><span class="Operator">></span> f <span class="Operator">=</span> f x | |||
| <span class="Keyword">let</span> fst <span class="Keyword">(</span>x<span class="Operator">,</span> <span class="Keyword">_</span><span class="Keyword">)</span> <span class="Operator">=</span> x | |||
| <span class="Keyword">let</span> snd <span class="Keyword">(</span><span class="Keyword">_</span><span class="Operator">,</span> x<span class="Keyword">)</span> <span class="Operator">=</span> x | |||
| <span class="Keyword">let</span> uncurry f <span class="Keyword">(</span>x<span class="Operator">,</span> y<span class="Keyword">)</span> <span class="Operator">=</span> f x y | |||
| <span class="Keyword">let</span> fork f g x <span class="Operator">=</span> <span class="Keyword">(</span>f x<span class="Operator">,</span> g x<span class="Keyword">)</span> | |||
| <span class="Keyword">class</span> profunctor <span class="Type">'p</span> <span class="Keyword">begin</span> | |||
| <span class="Keyword">val</span> dimap <span class="Operator">:</span> <span class="Keyword">forall</span> <span class="Type">'a</span> <span class="Type">'b</span> <span class="Type">'c</span> <span class="Type">'d</span><span class="Operator">.</span> <span class="Keyword">(</span><span class="Type">'b</span> <span class="Keyword">-></span> <span class="Type">'a</span><span class="Keyword">)</span> <span class="Keyword">-></span> <span class="Keyword">(</span><span class="Type">'c</span> <span class="Keyword">-></span> <span class="Type">'d</span><span class="Keyword">)</span> | |||
| <span class="Keyword">-></span> <span class="Type">'p</span> <span class="Type">'a</span> <span class="Type">'c</span> <span class="Keyword">-></span> <span class="Type">'p</span> <span class="Type">'b</span> <span class="Type">'d</span> | |||
| <span class="Keyword">end</span> | |||
| <span class="Keyword">let</span> lmap g <span class="Operator">=</span> dimap g id | |||
| <span class="Keyword">let</span> rmap x <span class="Operator">=</span> dimap id x | |||
| <span class="Keyword">class</span> profunctor <span class="Type">'p</span> <span class="Operator">=</span><span class="Operator">></span> strong <span class="Type">'p</span> <span class="Keyword">begin</span> | |||
| <span class="Keyword">val</span> first <span class="Operator">:</span> <span class="Keyword">forall</span> <span class="Type">'a</span> <span class="Type">'b</span> <span class="Type">'c</span><span class="Operator">.</span> <span class="Type">'p</span> <span class="Type">'a</span> <span class="Type">'b</span> <span class="Keyword">-></span> <span class="Type">'p</span> <span class="Keyword">(</span><span class="Type">'a</span> <span class="Operator">*</span> <span class="Type">'c</span><span class="Keyword">)</span> <span class="Keyword">(</span><span class="Type">'b</span> <span class="Operator">*</span> <span class="Type">'c</span><span class="Keyword">)</span> | |||
| <span class="Keyword">val</span> second <span class="Operator">:</span> <span class="Keyword">forall</span> <span class="Type">'a</span> <span class="Type">'b</span> <span class="Type">'c</span><span class="Operator">.</span> <span class="Type">'p</span> <span class="Type">'a</span> <span class="Type">'b</span> <span class="Keyword">-></span> <span class="Type">'p</span> <span class="Keyword">(</span><span class="Type">'c</span> <span class="Operator">*</span> <span class="Type">'a</span><span class="Keyword">)</span> <span class="Keyword">(</span><span class="Type">'c</span> <span class="Operator">*</span> <span class="Type">'b</span><span class="Keyword">)</span> | |||
| <span class="Keyword">end</span> | |||
| <span class="Keyword">type</span> <span class="Special">either</span> <span class="Type">'l</span> <span class="Type">'r</span> <span class="Operator">=</span> <span class="Constant">Left</span> <span class="Keyword">of</span> <span class="Type">'l</span> <span class="Operator">|</span> <span class="Constant">Right</span> <span class="Keyword">of</span> <span class="Type">'r</span> | |||
| <span class="Keyword">let</span> <span class="Special">either</span> f g <span class="Operator">=</span> <span class="Keyword">function</span> | |||
| <span class="Operator">|</span> <span class="Constant">Left</span> x <span class="Keyword">-></span> f x | |||
| <span class="Operator">|</span> <span class="Constant">Right</span> y <span class="Keyword">-></span> g y | |||
| <span class="Keyword">class</span> profunctor <span class="Type">'p</span> <span class="Operator">=</span><span class="Operator">></span> choice <span class="Type">'p</span> <span class="Keyword">begin</span> | |||
| <span class="Keyword">val</span> left <span class="Operator">:</span> <span class="Keyword">forall</span> <span class="Type">'a</span> <span class="Type">'b</span> <span class="Type">'c</span><span class="Operator">.</span> <span class="Type">'p</span> <span class="Type">'a</span> <span class="Type">'b</span> | |||
| <span class="Keyword">-></span> <span class="Type">'p</span> <span class="Keyword">(</span><span class="Special">either</span> <span class="Type">'a</span> <span class="Type">'c</span><span class="Keyword">)</span> <span class="Keyword">(</span><span class="Special">either</span> <span class="Type">'b</span> <span class="Type">'c</span><span class="Keyword">)</span> | |||
| <span class="Keyword">val</span> right <span class="Operator">:</span> <span class="Keyword">forall</span> <span class="Type">'a</span> <span class="Type">'b</span> <span class="Type">'c</span><span class="Operator">.</span> <span class="Type">'p</span> <span class="Type">'a</span> <span class="Type">'b</span> | |||
| <span class="Keyword">-></span> <span class="Type">'p</span> <span class="Keyword">(</span><span class="Special">either</span> <span class="Type">'c</span> <span class="Type">'a</span><span class="Keyword">)</span> <span class="Keyword">(</span><span class="Special">either</span> <span class="Type">'c</span> <span class="Type">'b</span><span class="Keyword">)</span> | |||
| <span class="Keyword">end</span> | |||
| <span class="Keyword">class</span> monoid <span class="Type">'m</span> <span class="Keyword">begin</span> | |||
| <span class="Keyword">val</span> <span class="Keyword">(</span><span class="Operator"><></span><span class="Keyword">)</span> <span class="Operator">:</span> <span class="Type">'m</span> <span class="Keyword">-></span> <span class="Type">'m</span> <span class="Keyword">-></span> <span class="Type">'m</span> | |||
| <span class="Keyword">val</span> zero <span class="Operator">:</span> <span class="Type">'m</span> | |||
| <span class="Keyword">end</span> | |||
| <span class="Keyword">type</span> forget <span class="Type">'r</span> <span class="Type">'a</span> <span class="Type">'b</span> <span class="Operator">=</span> <span class="Constant">Forget</span> <span class="Keyword">of</span> <span class="Type">'a</span> <span class="Keyword">-></span> <span class="Type">'r</span> | |||
| <span class="Keyword">let</span> remember <span class="Keyword">(</span><span class="Constant">Forget</span> r<span class="Keyword">)</span> <span class="Operator">=</span> r | |||
| <span class="Keyword">instance</span> profunctor <span class="Keyword">(</span><span class="Keyword">-></span><span class="Keyword">)</span> | |||
| <span class="Keyword">let</span> dimap f g h <span class="Operator">=</span> g <span class="Operator"><<<</span> h <span class="Operator"><<<</span> f | |||
| <span class="Keyword">instance</span> strong <span class="Keyword">(</span><span class="Keyword">-></span><span class="Keyword">)</span> | |||
| <span class="Keyword">let</span> first f <span class="Keyword">(</span>x<span class="Operator">,</span> y<span class="Keyword">)</span> <span class="Operator">=</span> <span class="Keyword">(</span>f x<span class="Operator">,</span> y<span class="Keyword">)</span> | |||
| <span class="Keyword">let</span> second f <span class="Keyword">(</span>x<span class="Operator">,</span> y<span class="Keyword">)</span> <span class="Operator">=</span> <span class="Keyword">(</span>x<span class="Operator">,</span> f y<span class="Keyword">)</span> | |||
| <span class="Keyword">instance</span> choice <span class="Keyword">(</span><span class="Keyword">-></span><span class="Keyword">)</span> | |||
| <span class="Keyword">let</span> left f <span class="Operator">=</span> <span class="Special">either</span> <span class="Keyword">(</span><span class="Constant">Left</span> <span class="Operator"><<<</span> f<span class="Keyword">)</span> <span class="Constant">Right</span> | |||
| <span class="Keyword">let</span> right f <span class="Operator">=</span> <span class="Special">either</span> <span class="Constant">Left</span> <span class="Keyword">(</span><span class="Constant">Right</span> <span class="Operator"><<<</span> f<span class="Keyword">)</span> | |||
| <span class="Keyword">instance</span> profunctor <span class="Keyword">(</span>forget <span class="Type">'r</span><span class="Keyword">)</span> | |||
| <span class="Keyword">let</span> dimap f <span class="Keyword">_</span> <span class="Keyword">(</span><span class="Constant">Forget</span> g<span class="Keyword">)</span> <span class="Operator">=</span> <span class="Constant">Forget</span> <span class="Keyword">(</span>g <span class="Operator"><<<</span> f<span class="Keyword">)</span> | |||
| <span class="Keyword">instance</span> monoid <span class="Type">'r</span> <span class="Operator">=</span><span class="Operator">></span> choice <span class="Keyword">(</span>forget <span class="Type">'r</span><span class="Keyword">)</span> | |||
| <span class="Keyword">let</span> left <span class="Keyword">(</span><span class="Constant">Forget</span> z<span class="Keyword">)</span> <span class="Operator">=</span> <span class="Constant">Forget</span> <span class="Keyword">(</span><span class="Special">either</span> z <span class="Keyword">(</span>const zero<span class="Keyword">))</span> | |||
| <span class="Keyword">let</span> right <span class="Keyword">(</span><span class="Constant">Forget</span> z<span class="Keyword">)</span> <span class="Operator">=</span> <span class="Constant">Forget</span> <span class="Keyword">(</span><span class="Special">either</span> <span class="Keyword">(</span>const zero<span class="Keyword">)</span> z<span class="Keyword">)</span> | |||
| <span class="Keyword">instance</span> strong <span class="Keyword">(</span>forget <span class="Type">'r</span><span class="Keyword">)</span> | |||
| <span class="Keyword">let</span> first <span class="Keyword">(</span><span class="Constant">Forget</span> z<span class="Keyword">)</span> <span class="Operator">=</span> <span class="Constant">Forget</span> <span class="Keyword">(</span>z <span class="Operator"><<<</span> fst<span class="Keyword">)</span> | |||
| <span class="Keyword">let</span> second <span class="Keyword">(</span><span class="Constant">Forget</span> z<span class="Keyword">)</span> <span class="Operator">=</span> <span class="Constant">Forget</span> <span class="Keyword">(</span>z <span class="Operator"><<<</span> snd<span class="Keyword">)</span> | |||
| <span class="Keyword">let</span> lens get set <span class="Operator">=</span> | |||
| dimap <span class="Keyword">(</span>fork get id<span class="Keyword">)</span> <span class="Keyword">(</span>uncurry set<span class="Keyword">)</span> <span class="Operator"><<<</span> first | |||
| <span class="Keyword">let</span> view l <span class="Operator">=</span> remember <span class="Keyword">(</span>l <span class="Keyword">(</span><span class="Constant">Forget</span> id<span class="Keyword">))</span> | |||
| <span class="Keyword">let</span> over f <span class="Operator">=</span> f | |||
| <span class="Keyword">let</span> set l b <span class="Operator">=</span> over l <span class="Keyword">(</span>const b<span class="Keyword">)</span> | |||
| <span class="Keyword">let</span> x <span class="Operator">^.</span> l <span class="Operator">=</span> view l x | |||
| <span class="Keyword">let</span> l <span class="Operator">^</span><span class="Operator">~</span> f <span class="Operator">=</span> over l f | |||
| <span class="Keyword">type</span> pair <span class="Type">'a</span> <span class="Type">'b</span> <span class="Operator">=</span> <span class="Constant">Pair</span> <span class="Keyword">of</span> <span class="Type">'a</span> <span class="Operator">*</span> <span class="Type">'b</span> | |||
| <span class="Keyword">let</span> fst' <span class="Keyword">(</span><span class="Constant">Pair</span> <span class="Keyword">(</span>x<span class="Operator">,</span> <span class="Keyword">_</span><span class="Keyword">))</span> <span class="Operator">=</span> x | |||
| <span class="Keyword">let</span> snd' <span class="Keyword">(</span><span class="Constant">Pair</span> <span class="Keyword">(</span><span class="Keyword">_</span><span class="Operator">,</span> x<span class="Keyword">))</span> <span class="Operator">=</span> x | |||
| <span class="Keyword">let</span> first' x <span class="Operator">=</span> lens fst' <span class="Keyword">(fun</span> x <span class="Keyword">(</span><span class="Constant">Pair</span> <span class="Keyword">(</span><span class="Keyword">_</span><span class="Operator">,</span> y<span class="Keyword">))</span> <span class="Keyword">-></span> <span class="Constant">Pair</span> <span class="Keyword">(</span>x<span class="Operator">,</span> y<span class="Keyword">))</span> x | |||
| <span class="Keyword">let</span> second' x <span class="Operator">=</span> lens snd' <span class="Keyword">(fun</span> y <span class="Keyword">(</span><span class="Constant">Pair</span> <span class="Keyword">(</span>x<span class="Operator">,</span> <span class="Keyword">_</span><span class="Keyword">))</span> <span class="Keyword">-></span> <span class="Constant">Pair</span> <span class="Keyword">(</span>x<span class="Operator">,</span> y<span class="Keyword">))</span> x | |||
| <span class="Keyword">type</span> proxy <span class="Type">'a</span> <span class="Operator">=</span> <span class="Constant">Proxy</span> | |||
| <span class="Keyword">type</span> optic <span class="Type">'p</span> <span class="Type">'a</span> <span class="Type">'s</span> <span class="Operator"><-</span> <span class="Type">'p</span> <span class="Type">'a</span> <span class="Type">'a</span> <span class="Keyword">-></span> <span class="Type">'p</span> <span class="Type">'s</span> <span class="Type">'s</span> | |||
| <span class="Keyword">class</span> | |||
| <span class="Include">Amc</span>.row_cons <span class="Type">'r</span> <span class="Type">'k</span> <span class="Type">'t</span> <span class="Type">'n</span> | |||
| <span class="Operator">=</span><span class="Operator">></span> has_lens <span class="Type">'r</span> <span class="Type">'k</span> <span class="Type">'t</span> <span class="Type">'n</span> | |||
| <span class="Operator">|</span> <span class="Type">'k</span> <span class="Type">'n</span> <span class="Keyword">-></span> <span class="Type">'r</span> <span class="Type">'t</span> | |||
| <span class="Keyword">begin</span> | |||
| <span class="Keyword">val</span> rlens <span class="Operator">:</span> strong <span class="Type">'p</span> <span class="Operator">=</span><span class="Operator">></span> proxy <span class="Type">'k</span> <span class="Keyword">-></span> optic <span class="Type">'p</span> <span class="Type">'t</span> <span class="Type">'n</span> | |||
| <span class="Keyword">end</span> | |||
| <span class="Keyword">instance</span> | |||
| <span class="Include">Amc</span>.known_string <span class="Type">'key</span> | |||
| <span class="Operator">*</span> <span class="Include">Amc</span>.row_cons <span class="Type">'record</span> <span class="Type">'key</span> <span class="Type">'type</span> <span class="Type">'new</span> | |||
| <span class="Operator">=</span><span class="Operator">></span> has_lens <span class="Type">'record</span> <span class="Type">'key</span> <span class="Type">'type</span> <span class="Type">'new</span> | |||
| <span class="Keyword">begin</span> | |||
| <span class="Keyword">let</span> rlens <span class="Keyword">_</span> <span class="Operator">=</span> | |||
| <span class="Keyword">let</span> view r <span class="Operator">=</span> | |||
| <span class="Keyword">let</span> <span class="Keyword">(</span>x<span class="Operator">,</span> <span class="Keyword">_</span><span class="Keyword">)</span> <span class="Operator">=</span> <span class="Include">Amc</span>.restrict_row <span class="Operator">@</span><span class="Type">'key</span> r | |||
| x | |||
| <span class="Keyword">let</span> set x r <span class="Operator">=</span> | |||
| <span class="Keyword">let</span> <span class="Keyword">(</span><span class="Keyword">_</span><span class="Operator">,</span> r'<span class="Keyword">)</span> <span class="Operator">=</span> <span class="Include">Amc</span>.restrict_row <span class="Operator">@</span><span class="Type">'key</span> r | |||
| <span class="Include">Amc</span>.extend_row <span class="Operator">@</span><span class="Type">'key</span> x r' | |||
| lens view set | |||
| <span class="Keyword">end</span> | |||
| <span class="Keyword">let</span> r | |||
| <span class="Operator">:</span> <span class="Keyword">forall</span> <span class="Type">'key</span> <span class="Keyword">-></span> <span class="Keyword">forall</span> <span class="Type">'record</span> <span class="Type">'type</span> <span class="Type">'new</span> <span class="Type">'p</span><span class="Operator">.</span> | |||
| <span class="Include">Amc</span>.known_string <span class="Type">'key</span> | |||
| <span class="Operator">*</span> has_lens <span class="Type">'record</span> <span class="Type">'key</span> <span class="Type">'type</span> <span class="Type">'new</span> | |||
| <span class="Operator">*</span> strong <span class="Type">'p</span> | |||
| <span class="Operator">=</span><span class="Operator">></span> optic <span class="Type">'p</span> <span class="Type">'type</span> <span class="Type">'new</span> <span class="Operator">=</span> | |||
| <span class="Keyword">fun</span> x <span class="Keyword">-></span> rlens <span class="Operator">@</span><span class="Type">'record</span> <span class="Keyword">(</span><span class="Constant">Proxy</span> <span class="Operator">:</span> proxy <span class="Type">'key</span><span class="Keyword">)</span> x | |||
| <span class="Keyword">let</span> succ <span class="Operator">=</span> <span class="Keyword">(</span><span class="Operator">+</span> <span class="Float">1</span><span class="Keyword">)</span> | |||
| </pre> | |||
| </body> | |||
| </html> | |||
| <!-- vim: set foldmethod=manual : --> | |||
+ 26
- 0
static/tasks.lisp
View File
| @ -0,0 +1,26 @@ | |||
| (import urn/control/prompt ()) | |||
| (defun run-tasks (&tasks) ; 1 | |||
| (loop [(queue tasks)] ; 2 | |||
| [(empty? queue)] ; 2 | |||
| (call/p 'task (car queue) | |||
| (lambda (k) | |||
| (when (alive? k) | |||
| (push-cdr! queue k)))) ; 2 | |||
| (recur (cdr queue)))) | |||
| (defun yield () | |||
| (abort-to-prompt 'task)) | |||
| (run-tasks | |||
| (lambda () | |||
| (map (lambda (x) | |||
| (print! $"loop 1: ~{x}") | |||
| (yield)) | |||
| (range :from 1 :to 5))) | |||
| (lambda () | |||
| (map (lambda (x) | |||
| (print! $"loop 2: ~{x}") | |||
| (yield)) | |||
| (range :from 1 :to 5)))) | |||
+ 126
- 0
static/tasks.lisp.html
View File
| @ -0,0 +1,126 @@ | |||
| <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd"> | |||
| <html> | |||
| <head> | |||
| <meta http-equiv="content-type" content="text/html; charset=UTF-8"> | |||
| <title>~/Projects/blag/static/tasks.lisp.html</title> | |||
| <meta name="Generator" content="Vim/7.4"> | |||
| <meta name="plugin-version" content="vim7.4_v2"> | |||
| <meta name="syntax" content="lisp"> | |||
| <meta name="settings" content="use_css,pre_wrap,no_foldcolumn,expand_tabs,prevent_copy=t"> | |||
| <meta name="colorscheme" content="onedark"> | |||
| <style type="text/css"> | |||
| <!-- | |||
| pre { white-space: pre-wrap; font-family: 'Iosevka','Iosevka Term', monospace; color: #ABB2BF; background-color: #282C34; } | |||
| body { font-family: 'Iosevka','Iosevka Term', monospace; color: #ABB2BF; background-color: #282C34; } | |||
| * { font-size: 1em; } | |||
| input { border: none; margin: 0; padding: 0; font-family: 'Iosevka','Iosevka Term', monospace; } | |||
| input[size='1'] { width: 1em; width: 1ch; } | |||
| input[size='2'] { width: 2em; width: 2ch; } | |||
| input[size='3'] { width: 3em; width: 3ch; } | |||
| input[size='4'] { width: 4em; width: 4ch; } | |||
| input[size='5'] { width: 5em; width: 5ch; } | |||
| input[size='6'] { width: 6em; width: 6ch; } | |||
| input[size='7'] { width: 7em; width: 7ch; } | |||
| input[size='8'] { width: 8em; width: 8ch; } | |||
| input[size='9'] { width: 9em; width: 9ch; } | |||
| input[size='10'] { width: 10em; width: 10ch; } | |||
| input[size='11'] { width: 11em; width: 11ch; } | |||
| input[size='12'] { width: 12em; width: 12ch; } | |||
| input[size='13'] { width: 13em; width: 13ch; } | |||
| input[size='14'] { width: 14em; width: 14ch; } | |||
| input[size='15'] { width: 15em; width: 15ch; } | |||
| input[size='16'] { width: 16em; width: 16ch; } | |||
| input[size='17'] { width: 17em; width: 17ch; } | |||
| input[size='18'] { width: 18em; width: 18ch; } | |||
| input[size='19'] { width: 19em; width: 19ch; } | |||
| input[size='20'] { width: 20em; width: 20ch; } | |||
| #oneCharWidth, #oneEmWidth, #oneInputWidth { padding: 0; margin: 0; position: absolute; left: -999999px; visibility: hidden; } | |||
| .em5 input[size='1'] { width: 0.05em; } .em5 input[size='2'] { width: 0.1em; } .em5 input[size='3'] { width: 0.15em; } .em5 input[size='4'] { width: 0.2em; } .em5 input[size='5'] { width: 0.25em; } .em5 input[size='6'] { width: 0.3em; } .em5 input[size='7'] { width: 0.35em; } .em5 input[size='8'] { width: 0.4em; } .em5 input[size='9'] { width: 0.45em; } .em5 input[size='10'] { width: 0.5em; } .em5 input[size='11'] { width: 0.55em; } .em5 input[size='12'] { width: 0.6em; } .em5 input[size='13'] { width: 0.65em; } .em5 input[size='14'] { width: 0.7em; } .em5 input[size='15'] { width: 0.75em; } .em5 input[size='16'] { width: 0.8em; } .em5 input[size='17'] { width: 0.85em; } .em5 input[size='18'] { width: 0.9em; } .em5 input[size='19'] { width: 0.95em; } .em5 input[size='20'] { width: 1.0em; } | |||
| .em10 input[size='1'] { width: 0.1em; } .em10 input[size='2'] { width: 0.2em; } .em10 input[size='3'] { width: 0.3em; } .em10 input[size='4'] { width: 0.4em; } .em10 input[size='5'] { width: 0.5em; } .em10 input[size='6'] { width: 0.6em; } .em10 input[size='7'] { width: 0.7em; } .em10 input[size='8'] { width: 0.8em; } .em10 input[size='9'] { width: 0.9em; } .em10 input[size='10'] { width: 1.0em; } .em10 input[size='11'] { width: 1.1em; } .em10 input[size='12'] { width: 1.2em; } .em10 input[size='13'] { width: 1.3em; } .em10 input[size='14'] { width: 1.4em; } .em10 input[size='15'] { width: 1.5em; } .em10 input[size='16'] { width: 1.6em; } .em10 input[size='17'] { width: 1.7em; } .em10 input[size='18'] { width: 1.8em; } .em10 input[size='19'] { width: 1.9em; } .em10 input[size='20'] { width: 2.0em; } | |||
| .em15 input[size='1'] { width: 0.15em; } .em15 input[size='2'] { width: 0.3em; } .em15 input[size='3'] { width: 0.45em; } .em15 input[size='4'] { width: 0.6em; } .em15 input[size='5'] { width: 0.75em; } .em15 input[size='6'] { width: 0.9em; } .em15 input[size='7'] { width: 1.05em; } .em15 input[size='8'] { width: 1.2em; } .em15 input[size='9'] { width: 1.35em; } .em15 input[size='10'] { width: 1.5em; } .em15 input[size='11'] { width: 1.65em; } .em15 input[size='12'] { width: 1.8em; } .em15 input[size='13'] { width: 1.95em; } .em15 input[size='14'] { width: 2.1em; } .em15 input[size='15'] { width: 2.25em; } .em15 input[size='16'] { width: 2.4em; } .em15 input[size='17'] { width: 2.55em; } .em15 input[size='18'] { width: 2.7em; } .em15 input[size='19'] { width: 2.85em; } .em15 input[size='20'] { width: 3.0em; } | |||
| .em20 input[size='1'] { width: 0.2em; } .em20 input[size='2'] { width: 0.4em; } .em20 input[size='3'] { width: 0.6em; } .em20 input[size='4'] { width: 0.8em; } .em20 input[size='5'] { width: 1.0em; } .em20 input[size='6'] { width: 1.2em; } .em20 input[size='7'] { width: 1.4em; } .em20 input[size='8'] { width: 1.6em; } .em20 input[size='9'] { width: 1.8em; } .em20 input[size='10'] { width: 2.0em; } .em20 input[size='11'] { width: 2.2em; } .em20 input[size='12'] { width: 2.4em; } .em20 input[size='13'] { width: 2.6em; } .em20 input[size='14'] { width: 2.8em; } .em20 input[size='15'] { width: 3.0em; } .em20 input[size='16'] { width: 3.2em; } .em20 input[size='17'] { width: 3.4em; } .em20 input[size='18'] { width: 3.6em; } .em20 input[size='19'] { width: 3.8em; } .em20 input[size='20'] { width: 4.0em; } | |||
| .em25 input[size='1'] { width: 0.25em; } .em25 input[size='2'] { width: 0.5em; } .em25 input[size='3'] { width: 0.75em; } .em25 input[size='4'] { width: 1.0em; } .em25 input[size='5'] { width: 1.25em; } .em25 input[size='6'] { width: 1.5em; } .em25 input[size='7'] { width: 1.75em; } .em25 input[size='8'] { width: 2.0em; } .em25 input[size='9'] { width: 2.25em; } .em25 input[size='10'] { width: 2.5em; } .em25 input[size='11'] { width: 2.75em; } .em25 input[size='12'] { width: 3.0em; } .em25 input[size='13'] { width: 3.25em; } .em25 input[size='14'] { width: 3.5em; } .em25 input[size='15'] { width: 3.75em; } .em25 input[size='16'] { width: 4.0em; } .em25 input[size='17'] { width: 4.25em; } .em25 input[size='18'] { width: 4.5em; } .em25 input[size='19'] { width: 4.75em; } .em25 input[size='20'] { width: 5.0em; } | |||
| .em30 input[size='1'] { width: 0.3em; } .em30 input[size='2'] { width: 0.6em; } .em30 input[size='3'] { width: 0.9em; } .em30 input[size='4'] { width: 1.2em; } .em30 input[size='5'] { width: 1.5em; } .em30 input[size='6'] { width: 1.8em; } .em30 input[size='7'] { width: 2.1em; } .em30 input[size='8'] { width: 2.4em; } .em30 input[size='9'] { width: 2.7em; } .em30 input[size='10'] { width: 3.0em; } .em30 input[size='11'] { width: 3.3em; } .em30 input[size='12'] { width: 3.6em; } .em30 input[size='13'] { width: 3.9em; } .em30 input[size='14'] { width: 4.2em; } .em30 input[size='15'] { width: 4.5em; } .em30 input[size='16'] { width: 4.8em; } .em30 input[size='17'] { width: 5.1em; } .em30 input[size='18'] { width: 5.4em; } .em30 input[size='19'] { width: 5.7em; } .em30 input[size='20'] { width: 6.0em; } | |||
| .em35 input[size='1'] { width: 0.35em; } .em35 input[size='2'] { width: 0.7em; } .em35 input[size='3'] { width: 1.05em; } .em35 input[size='4'] { width: 1.4em; } .em35 input[size='5'] { width: 1.75em; } .em35 input[size='6'] { width: 2.1em; } .em35 input[size='7'] { width: 2.45em; } .em35 input[size='8'] { width: 2.8em; } .em35 input[size='9'] { width: 3.15em; } .em35 input[size='10'] { width: 3.5em; } .em35 input[size='11'] { width: 3.85em; } .em35 input[size='12'] { width: 4.2em; } .em35 input[size='13'] { width: 4.55em; } .em35 input[size='14'] { width: 4.9em; } .em35 input[size='15'] { width: 5.25em; } .em35 input[size='16'] { width: 5.6em; } .em35 input[size='17'] { width: 5.95em; } .em35 input[size='18'] { width: 6.3em; } .em35 input[size='19'] { width: 6.65em; } .em35 input[size='20'] { width: 7.0em; } | |||
| .em40 input[size='1'] { width: 0.4em; } .em40 input[size='2'] { width: 0.8em; } .em40 input[size='3'] { width: 1.2em; } .em40 input[size='4'] { width: 1.6em; } .em40 input[size='5'] { width: 2.0em; } .em40 input[size='6'] { width: 2.4em; } .em40 input[size='7'] { width: 2.8em; } .em40 input[size='8'] { width: 3.2em; } .em40 input[size='9'] { width: 3.6em; } .em40 input[size='10'] { width: 4.0em; } .em40 input[size='11'] { width: 4.4em; } .em40 input[size='12'] { width: 4.8em; } .em40 input[size='13'] { width: 5.2em; } .em40 input[size='14'] { width: 5.6em; } .em40 input[size='15'] { width: 6.0em; } .em40 input[size='16'] { width: 6.4em; } .em40 input[size='17'] { width: 6.8em; } .em40 input[size='18'] { width: 7.2em; } .em40 input[size='19'] { width: 7.6em; } .em40 input[size='20'] { width: 8.0em; } | |||
| .em45 input[size='1'] { width: 0.45em; } .em45 input[size='2'] { width: 0.9em; } .em45 input[size='3'] { width: 1.35em; } .em45 input[size='4'] { width: 1.8em; } .em45 input[size='5'] { width: 2.25em; } .em45 input[size='6'] { width: 2.7em; } .em45 input[size='7'] { width: 3.15em; } .em45 input[size='8'] { width: 3.6em; } .em45 input[size='9'] { width: 4.05em; } .em45 input[size='10'] { width: 4.5em; } .em45 input[size='11'] { width: 4.95em; } .em45 input[size='12'] { width: 5.4em; } .em45 input[size='13'] { width: 5.85em; } .em45 input[size='14'] { width: 6.3em; } .em45 input[size='15'] { width: 6.75em; } .em45 input[size='16'] { width: 7.2em; } .em45 input[size='17'] { width: 7.65em; } .em45 input[size='18'] { width: 8.1em; } .em45 input[size='19'] { width: 8.55em; } .em45 input[size='20'] { width: 9.0em; } | |||
| .em50 input[size='1'] { width: 0.5em; } .em50 input[size='2'] { width: 1.0em; } .em50 input[size='3'] { width: 1.5em; } .em50 input[size='4'] { width: 2.0em; } .em50 input[size='5'] { width: 2.5em; } .em50 input[size='6'] { width: 3.0em; } .em50 input[size='7'] { width: 3.5em; } .em50 input[size='8'] { width: 4.0em; } .em50 input[size='9'] { width: 4.5em; } .em50 input[size='10'] { width: 5.0em; } .em50 input[size='11'] { width: 5.5em; } .em50 input[size='12'] { width: 6.0em; } .em50 input[size='13'] { width: 6.5em; } .em50 input[size='14'] { width: 7.0em; } .em50 input[size='15'] { width: 7.5em; } .em50 input[size='16'] { width: 8.0em; } .em50 input[size='17'] { width: 8.5em; } .em50 input[size='18'] { width: 9.0em; } .em50 input[size='19'] { width: 9.5em; } .em50 input[size='20'] { width: 10.0em; } | |||
| .em55 input[size='1'] { width: 0.55em; } .em55 input[size='2'] { width: 1.1em; } .em55 input[size='3'] { width: 1.65em; } .em55 input[size='4'] { width: 2.2em; } .em55 input[size='5'] { width: 2.75em; } .em55 input[size='6'] { width: 3.3em; } .em55 input[size='7'] { width: 3.85em; } .em55 input[size='8'] { width: 4.4em; } .em55 input[size='9'] { width: 4.95em; } .em55 input[size='10'] { width: 5.5em; } .em55 input[size='11'] { width: 6.05em; } .em55 input[size='12'] { width: 6.6em; } .em55 input[size='13'] { width: 7.15em; } .em55 input[size='14'] { width: 7.7em; } .em55 input[size='15'] { width: 8.25em; } .em55 input[size='16'] { width: 8.8em; } .em55 input[size='17'] { width: 9.35em; } .em55 input[size='18'] { width: 9.9em; } .em55 input[size='19'] { width: 10.45em; } .em55 input[size='20'] { width: 11.0em; } | |||
| .em60 input[size='1'] { width: 0.6em; } .em60 input[size='2'] { width: 1.2em; } .em60 input[size='3'] { width: 1.8em; } .em60 input[size='4'] { width: 2.4em; } .em60 input[size='5'] { width: 3.0em; } .em60 input[size='6'] { width: 3.6em; } .em60 input[size='7'] { width: 4.2em; } .em60 input[size='8'] { width: 4.8em; } .em60 input[size='9'] { width: 5.4em; } .em60 input[size='10'] { width: 6.0em; } .em60 input[size='11'] { width: 6.6em; } .em60 input[size='12'] { width: 7.2em; } .em60 input[size='13'] { width: 7.8em; } .em60 input[size='14'] { width: 8.4em; } .em60 input[size='15'] { width: 9.0em; } .em60 input[size='16'] { width: 9.6em; } .em60 input[size='17'] { width: 10.2em; } .em60 input[size='18'] { width: 10.8em; } .em60 input[size='19'] { width: 11.4em; } .em60 input[size='20'] { width: 12.0em; } | |||
| .em65 input[size='1'] { width: 0.65em; } .em65 input[size='2'] { width: 1.3em; } .em65 input[size='3'] { width: 1.95em; } .em65 input[size='4'] { width: 2.6em; } .em65 input[size='5'] { width: 3.25em; } .em65 input[size='6'] { width: 3.9em; } .em65 input[size='7'] { width: 4.55em; } .em65 input[size='8'] { width: 5.2em; } .em65 input[size='9'] { width: 5.85em; } .em65 input[size='10'] { width: 6.5em; } .em65 input[size='11'] { width: 7.15em; } .em65 input[size='12'] { width: 7.8em; } .em65 input[size='13'] { width: 8.45em; } .em65 input[size='14'] { width: 9.1em; } .em65 input[size='15'] { width: 9.75em; } .em65 input[size='16'] { width: 10.4em; } .em65 input[size='17'] { width: 11.05em; } .em65 input[size='18'] { width: 11.7em; } .em65 input[size='19'] { width: 12.35em; } .em65 input[size='20'] { width: 13.0em; } | |||
| .em70 input[size='1'] { width: 0.7em; } .em70 input[size='2'] { width: 1.4em; } .em70 input[size='3'] { width: 2.1em; } .em70 input[size='4'] { width: 2.8em; } .em70 input[size='5'] { width: 3.5em; } .em70 input[size='6'] { width: 4.2em; } .em70 input[size='7'] { width: 4.9em; } .em70 input[size='8'] { width: 5.6em; } .em70 input[size='9'] { width: 6.3em; } .em70 input[size='10'] { width: 7.0em; } .em70 input[size='11'] { width: 7.7em; } .em70 input[size='12'] { width: 8.4em; } .em70 input[size='13'] { width: 9.1em; } .em70 input[size='14'] { width: 9.8em; } .em70 input[size='15'] { width: 10.5em; } .em70 input[size='16'] { width: 11.2em; } .em70 input[size='17'] { width: 11.9em; } .em70 input[size='18'] { width: 12.6em; } .em70 input[size='19'] { width: 13.3em; } .em70 input[size='20'] { width: 14.0em; } | |||
| .em75 input[size='1'] { width: 0.75em; } .em75 input[size='2'] { width: 1.5em; } .em75 input[size='3'] { width: 2.25em; } .em75 input[size='4'] { width: 3.0em; } .em75 input[size='5'] { width: 3.75em; } .em75 input[size='6'] { width: 4.5em; } .em75 input[size='7'] { width: 5.25em; } .em75 input[size='8'] { width: 6.0em; } .em75 input[size='9'] { width: 6.75em; } .em75 input[size='10'] { width: 7.5em; } .em75 input[size='11'] { width: 8.25em; } .em75 input[size='12'] { width: 9.0em; } .em75 input[size='13'] { width: 9.75em; } .em75 input[size='14'] { width: 10.5em; } .em75 input[size='15'] { width: 11.25em; } .em75 input[size='16'] { width: 12.0em; } .em75 input[size='17'] { width: 12.75em; } .em75 input[size='18'] { width: 13.5em; } .em75 input[size='19'] { width: 14.25em; } .em75 input[size='20'] { width: 15.0em; } | |||
| .em80 input[size='1'] { width: 0.8em; } .em80 input[size='2'] { width: 1.6em; } .em80 input[size='3'] { width: 2.4em; } .em80 input[size='4'] { width: 3.2em; } .em80 input[size='5'] { width: 4.0em; } .em80 input[size='6'] { width: 4.8em; } .em80 input[size='7'] { width: 5.6em; } .em80 input[size='8'] { width: 6.4em; } .em80 input[size='9'] { width: 7.2em; } .em80 input[size='10'] { width: 8.0em; } .em80 input[size='11'] { width: 8.8em; } .em80 input[size='12'] { width: 9.6em; } .em80 input[size='13'] { width: 10.4em; } .em80 input[size='14'] { width: 11.2em; } .em80 input[size='15'] { width: 12.0em; } .em80 input[size='16'] { width: 12.8em; } .em80 input[size='17'] { width: 13.6em; } .em80 input[size='18'] { width: 14.4em; } .em80 input[size='19'] { width: 15.2em; } .em80 input[size='20'] { width: 16.0em; } | |||
| .em85 input[size='1'] { width: 0.85em; } .em85 input[size='2'] { width: 1.7em; } .em85 input[size='3'] { width: 2.55em; } .em85 input[size='4'] { width: 3.4em; } .em85 input[size='5'] { width: 4.25em; } .em85 input[size='6'] { width: 5.1em; } .em85 input[size='7'] { width: 5.95em; } .em85 input[size='8'] { width: 6.8em; } .em85 input[size='9'] { width: 7.65em; } .em85 input[size='10'] { width: 8.5em; } .em85 input[size='11'] { width: 9.35em; } .em85 input[size='12'] { width: 10.2em; } .em85 input[size='13'] { width: 11.05em; } .em85 input[size='14'] { width: 11.9em; } .em85 input[size='15'] { width: 12.75em; } .em85 input[size='16'] { width: 13.6em; } .em85 input[size='17'] { width: 14.45em; } .em85 input[size='18'] { width: 15.3em; } .em85 input[size='19'] { width: 16.15em; } .em85 input[size='20'] { width: 17.0em; } | |||
| .em90 input[size='1'] { width: 0.9em; } .em90 input[size='2'] { width: 1.8em; } .em90 input[size='3'] { width: 2.7em; } .em90 input[size='4'] { width: 3.6em; } .em90 input[size='5'] { width: 4.5em; } .em90 input[size='6'] { width: 5.4em; } .em90 input[size='7'] { width: 6.3em; } .em90 input[size='8'] { width: 7.2em; } .em90 input[size='9'] { width: 8.1em; } .em90 input[size='10'] { width: 9.0em; } .em90 input[size='11'] { width: 9.9em; } .em90 input[size='12'] { width: 10.8em; } .em90 input[size='13'] { width: 11.7em; } .em90 input[size='14'] { width: 12.6em; } .em90 input[size='15'] { width: 13.5em; } .em90 input[size='16'] { width: 14.4em; } .em90 input[size='17'] { width: 15.3em; } .em90 input[size='18'] { width: 16.2em; } .em90 input[size='19'] { width: 17.1em; } .em90 input[size='20'] { width: 18.0em; } | |||
| .em95 input[size='1'] { width: 0.95em; } .em95 input[size='2'] { width: 1.9em; } .em95 input[size='3'] { width: 2.85em; } .em95 input[size='4'] { width: 3.8em; } .em95 input[size='5'] { width: 4.75em; } .em95 input[size='6'] { width: 5.7em; } .em95 input[size='7'] { width: 6.65em; } .em95 input[size='8'] { width: 7.6em; } .em95 input[size='9'] { width: 8.55em; } .em95 input[size='10'] { width: 9.5em; } .em95 input[size='11'] { width: 10.45em; } .em95 input[size='12'] { width: 11.4em; } .em95 input[size='13'] { width: 12.35em; } .em95 input[size='14'] { width: 13.3em; } .em95 input[size='15'] { width: 14.25em; } .em95 input[size='16'] { width: 15.2em; } .em95 input[size='17'] { width: 16.15em; } .em95 input[size='18'] { width: 17.1em; } .em95 input[size='19'] { width: 18.05em; } .em95 input[size='20'] { width: 19.0em; } | |||
| .em100 input[size='1'] { width: 1.0em; } .em100 input[size='2'] { width: 2.0em; } .em100 input[size='3'] { width: 3.0em; } .em100 input[size='4'] { width: 4.0em; } .em100 input[size='5'] { width: 5.0em; } .em100 input[size='6'] { width: 6.0em; } .em100 input[size='7'] { width: 7.0em; } .em100 input[size='8'] { width: 8.0em; } .em100 input[size='9'] { width: 9.0em; } .em100 input[size='10'] { width: 10.0em; } .em100 input[size='11'] { width: 11.0em; } .em100 input[size='12'] { width: 12.0em; } .em100 input[size='13'] { width: 13.0em; } .em100 input[size='14'] { width: 14.0em; } .em100 input[size='15'] { width: 15.0em; } .em100 input[size='16'] { width: 16.0em; } .em100 input[size='17'] { width: 17.0em; } .em100 input[size='18'] { width: 18.0em; } .em100 input[size='19'] { width: 19.0em; } .em100 input[size='20'] { width: 20.0em; } | |||
| input.Folded { cursor: default; } | |||
| .Identifier { color: #E06C75; } | |||
| .Number { color: #D19A66; } | |||
| .Comment { color: #5C6370; } | |||
| .Type { color: #E5C07B; } | |||
| .Statement { color: #C678DD; } | |||
| .String { color: #98C379; } | |||
| --> | |||
| </style> | |||
| <script type='text/javascript'> | |||
| <!-- | |||
| /* simulate a "ch" unit by asking the browser how big a zero character is */ | |||
| function FixCharWidth() { | |||
| /* get the hidden element which gives the width of a single character */ | |||
| var goodWidth = document.getElementById("oneCharWidth").clientWidth; | |||
| /* get all input elements, we'll filter on class later */ | |||
| var inputTags = document.getElementsByTagName("input"); | |||
| var ratio = 5; | |||
| var inputWidth = document.getElementById("oneInputWidth").clientWidth; | |||
| var emWidth = document.getElementById("oneEmWidth").clientWidth; | |||
| if (inputWidth > goodWidth) { | |||
| while (ratio < 100*goodWidth/emWidth && ratio < 100) { | |||
| ratio += 5; | |||
| } | |||
| document.getElementById("vimCodeElement").className = "em"+ratio; | |||
| } | |||
| } | |||
| --> | |||
| </script> | |||
| </head> | |||
| <body onload='FixCharWidth();'> | |||
| <!-- hidden divs used by javascript to get the width of a char --> | |||
| <div id='oneCharWidth'>0</div> | |||
| <div id='oneInputWidth'><input size='1' value='0'></div> | |||
| <div id='oneEmWidth' style='width: 1em;'></div> | |||
| <pre id='vimCodeElement'> | |||
| (<span class="Statement">import</span> urn/control/prompt ()) | |||
| (<span class="Statement">defun</span> run-tasks (&tasks) <span class="Comment">; 1</span> | |||
| (<span class="Statement">loop</span> [(queue tasks)] <span class="Comment">; 2</span> | |||
| [(empty? queue)] <span class="Comment">; 2</span> | |||
| (call/p '<span class="Identifier">task</span> (<span class="Statement">car</span> queue) | |||
| (<span class="Statement">lambda</span> (k) | |||
| (<span class="Statement">when</span> (alive? k) | |||
| (push-cdr! queue k)))) <span class="Comment">; 2</span> | |||
| (recur (<span class="Statement">cdr</span> queue)))) | |||
| (<span class="Statement">defun</span> yield () | |||
| (abort-to-prompt '<span class="Identifier">task</span>)) | |||
| (run-tasks | |||
| (<span class="Statement">lambda</span> () | |||
| (<span class="Statement">map</span> (<span class="Statement">lambda</span> (x) | |||
| (<span class="Statement">print</span>! $<span class="String">"loop 1: ~{x}"</span>) | |||
| (yield)) | |||
| (range <span class="Type">:from</span> <span class="Number">1</span> <span class="Type">:to</span> <span class="Number">5</span>))) | |||
| (<span class="Statement">lambda</span> () | |||
| (<span class="Statement">map</span> (<span class="Statement">lambda</span> (x) | |||
| (<span class="Statement">print</span>! $<span class="String">"loop 2: ~{x}"</span>) | |||
| (yield)) | |||
| (range <span class="Type">:from</span> <span class="Number">1</span> <span class="Type">:to</span> <span class="Number">5</span>)))) | |||
| </pre> | |||
| </body> | |||
| </html> | |||
| <!-- vim: set foldmethod=manual : --> | |||
BIN
static/verify_error.png
View File
{kind=link}
| Before | After |
|---|---|
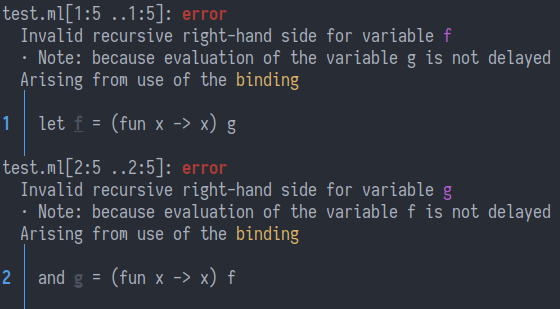
|
|
| Width: 560 | Height: 309 | Size: 34 KiB |
BIN
static/verify_warn.png
View File
{kind=link}
| Before | After |
|---|---|
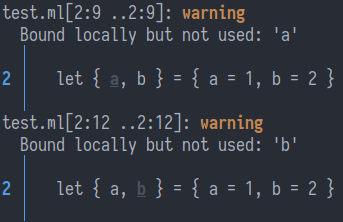
|
|
| Width: 343 | Height: 222 | Size: 17 KiB |
+ 8
- 0
sync
View File
| @ -0,0 +1,8 @@ | |||
| #!/usr/bin/env bash | |||
| if rg fastbuild pages/posts >/dev/null; then | |||
| echo "posts still have fast build, remove and rebuild then repush" | |||
| exit 1 | |||
| fi | |||
| rsync .site/ "${SYNC_SERVER}:/var/www/abby.how/" -vuar0 | |||
+ 190
- 0
syntax/amcprove.xml
View File
| @ -0,0 +1,190 @@ | |||
| <?xml version="1.0" encoding="UTF-8"?> | |||
| <!-- Kate syntax highlighting for Objective Caml version 4.02 in the standard and revised syntaxes, with Ocamldoc comments. --> | |||
| <!DOCTYPE language SYSTEM "language.dtd" | |||
| [ | |||
| <!-- Regular expresion constants: --> | |||
| <!ENTITY LOWER "a-z\300-\326\330-\337"> <!-- Lowercase Latin-1 letters. --> | |||
| <!ENTITY UPPER "A-Z\340-\366\370-\377"> <!-- Uppercase Latin-1 letters. --> | |||
| <!ENTITY LETTER "&LOWER;&UPPER;"> <!-- All Latin-1 letters. --> | |||
| <!ENTITY LIDENT "[&LOWER;_][&LETTER;0-9_']*"> <!-- Lowercase OCaml identifiers. --> | |||
| <!ENTITY UIDENT "`?[&UPPER;][&LETTER;0-9_']*"> <!-- Uppercase OCaml identifiers. --> | |||
| <!ENTITY IDENT "`?[&LETTER;][&LETTER;0-9_']*"> <!-- All OCaml identifiers. --> | |||
| <!ENTITY ESC "(\\[ntbr'"\\]|\\[0-9]{3}|\\x[0-9A-Fa-f]{2})"> <!-- OCaml character code escapes. --> | |||
| <!ENTITY DEC "[0-9][0-9_]*"> <!-- Decimal digits with underscores. --> | |||
| <!ENTITY INFIX "[:!#$%&*+\\/<=>?@^|-~][:!#$%&*+\\/<=>?@^|-~\.]*"> | |||
| ]> | |||
| <language name="amc-prove" | |||
| extensions="*.ml;*.mli" | |||
| mimetype="text/x-amc-prove" | |||
| section="Sources" | |||
| version="6" | |||
| priority="10" | |||
| kateversion="2.4" | |||
| author="Abigail Magalhães ([email protected])" | |||
| license="LGPL" > | |||
| <highlighting> | |||
| <list name="Keywords"> | |||
| <item>forall</item> | |||
| <item>fun</item> | |||
| <item>function</item> | |||
| <item>lazy</item> | |||
| <item>match</item> | |||
| <item>not</item> | |||
| <item>yes</item> | |||
| <item>probably</item> | |||
| </list> | |||
| <list name="Boolean Literals"> | |||
| <item>tt</item> | |||
| <item>ff</item> | |||
| </list> | |||
| <list name="Pervasive Functions"> | |||
| </list> | |||
| <list name="Pervasive Types"> | |||
| </list> | |||
| <list name="Standard Library Modules"> | |||
| <item>Amc</item> | |||
| </list> | |||
| <contexts> | |||
| <context name="Code" lineEndContext="#stay" attribute="Normal"> | |||
| <!-- ] and ]} close code samples in Ocamldoc, so --> | |||
| <!-- nested [ ] and { } brackets have to be allowed for: --> | |||
| <DetectChar char="[" context="Nested Code 1" attribute="Normal" /> | |||
| <DetectChar char="{" context="Nested Code 2" attribute="Normal" /> | |||
| <!-- Comments. --> | |||
| <!-- A (** begins a special comment with Ocamldoc documentation markup. --> | |||
| <Detect2Chars char="(" char1="*" context="Comment" attribute="Comment" beginRegion="comment" /> | |||
| <!-- Interpreter directives. --> | |||
| <!-- (These are lines where the first symbol is a '#' followed by an identifier. --> | |||
| <!-- Such lines could also be part of a method call split over two lines but --> | |||
| <!-- it's unlikey anyone would code like that.) --> | |||
| <!-- String, character and Camlp4 "quotation" constants. --> | |||
| <!-- Note: If you must modify the pattern for characters be precise: --> | |||
| <!-- single quotes have several meanings in Ocaml. --> | |||
| <DetectChar char=""" context="String" attribute="String" /> | |||
| <RegExpr String="'(&ESC;|[^'])'" context="#stay" attribute="Character" /> | |||
| <!-- Identifiers and keywords. --> | |||
| <keyword String="Keywords" context="#stay" attribute="Keyword" /> | |||
| <keyword String="Pervasive Functions" context="#stay" attribute="Pervasive Functions" /> | |||
| <keyword String="Pervasive Types" context="#stay" attribute="Pervasive Types" /> | |||
| <keyword String="Standard Library Modules" context="#stay" attribute="Standard Library Modules" /> | |||
| <keyword String="Boolean Literals" context="#stay" attribute="Boolean Literals" /> | |||
| <RegExpr String="&LIDENT;" context="#stay" attribute="Lowercase Identifier" /> | |||
| <RegExpr String="&UIDENT;" context="#stay" attribute="Uppercase Identifier" /> | |||
| <RegExpr String="'&LIDENT;" context="#stay" attribute="Type Variable" /> | |||
| <RegExpr String="[\-!#\$%&\*\+/<=>\?\@\^\|~\.:]+" | |||
| context="#stay" attribute="Infix Operator" /> | |||
| <!-- Numeric constants. --> | |||
| <!-- Note that they may contain underscores. --> | |||
| <RegExpr String="-?0[xX][0-9A-Fa-f_]+" context="#stay" attribute="Hexadecimal" /> | |||
| <RegExpr String="-?0[oO][0-7_]+" context="#stay" attribute="Octal" /> | |||
| <RegExpr String="-?0[bB][01_]+" context="#stay" attribute="Binary" /> | |||
| <RegExpr String="-?&DEC;(\.&DEC;([eE][-+]?&DEC;)?|[eE][-+]?&DEC;)" context="#stay" attribute="Float" /> | |||
| <RegExpr String="-?&DEC;" context="#stay" attribute="Decimal" /> | |||
| <IncludeRules context="Unmatched Closing Brackets" /> | |||
| </context> | |||
| <context name="Nested Code 1" lineEndContext="#stay" attribute="Normal"> | |||
| <DetectChar char="]" context="#pop" attribute="Normal" /> | |||
| <IncludeRules context="Code" includeAttrib="true" /> | |||
| </context> | |||
| <context name="Nested Code 2" lineEndContext="#stay" attribute="Normal"> | |||
| <DetectChar char="}" context="#pop" attribute="Normal" /> | |||
| <IncludeRules context="Code" includeAttrib="true" /> | |||
| </context> | |||
| <context name="String" lineEndContext="#stay" attribute="String"> | |||
| <DetectChar char=""" context="#pop" attribute="String" /> | |||
| <RegExpr String="&ESC;" context="#stay" attribute="Escaped Characters" /> | |||
| <!-- A backslash at the end of a line in a string indicates --> | |||
| <!-- that the string will continue on the next line: --> | |||
| <RegExpr String="\\$" context="#stay" attribute="Escaped Characters" /> | |||
| </context> | |||
| <context name="Comment" lineEndContext="#stay" attribute="Comment"> | |||
| <Detect2Chars char="*" char1=")" context="#pop" attribute="Comment" endRegion="comment" /> | |||
| <!-- Support for nested comments: --> | |||
| <Detect2Chars char="(" char1="*" context="Comment" attribute="Comment" beginRegion="comment" /> | |||
| <!-- Strings in Ocaml comments must be well-formed: --> | |||
| <DetectChar char=""" context="String in Comment" attribute="String in Comment" /> | |||
| </context> | |||
| <context name="String in Comment" lineEndContext="#stay" attribute="String in Comment"> | |||
| <DetectChar char=""" context="#pop" attribute="String in Comment" /> | |||
| <IncludeRules context="String" /> | |||
| </context> | |||
| <!-- Unmatched closing brackets- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - --> | |||
| <context name="Unmatched Closing Brackets" lineEndContext="#stay" attribute="Normal"> | |||
| <Detect2Chars char="*" char1=")" context="#pop" attribute="Mismatched Brackets" /> | |||
| <Detect2Chars char="v" char1="}" context="#stay" attribute="Mismatched Brackets" /> | |||
| <Detect2Chars char="]" char1="}" context="#stay" attribute="Mismatched Brackets" /> | |||
| <Detect2Chars char="%" char1="}" context="#stay" attribute="Mismatched Brackets" /> | |||
| <DetectChar char="]" context="#stay" attribute="Mismatched Brackets" /> | |||
| <DetectChar char="}" context="#stay" attribute="Mismatched Brackets" /> | |||
| </context> | |||
| </contexts> | |||
| <itemDatas> | |||
| <itemData name="Keyword" defStyleNum="dsKeyword" /> | |||
| <itemData name="Normal" defStyleNum="dsNormal" /> | |||
| <itemData name="Infix Operator" defStyleNum="dsOperator" /> | |||
| <itemData name="Uppercase Identifier" defStyleNum="dsDataType" italic="true" /> | |||
| <itemData name="Lowercase Identifier" defStyleNum="dsVariable" /> | |||
| <!-- Lowercase pervasive identifiers: --> | |||
| <itemData name="Pervasive Functions" defStyleNum="dsFunction" /> | |||
| <itemData name="Pervasive Types" defStyleNum="dsDataType" /> | |||
| <!-- Type variables --> | |||
| <itemData name="Type Variable" defStyleNum="dsSpecialString" /> | |||
| <!-- Uppercase pervasive identifiers: --> | |||
| <itemData name="Standard Library Modules" defStyleNum="dsDataType" italic="true" /> | |||
| <itemData name="Boolean Literals" defStyleNum="dsConstant" /> | |||
| <itemData name="Decimal" defStyleNum="dsDecVal" /> | |||
| <itemData name="Hexadecimal" defStyleNum="dsBaseN" /> | |||
| <itemData name="Octal" defStyleNum="dsBaseN" /> | |||
| <itemData name="Binary" defStyleNum="dsBaseN" /> | |||
| <itemData name="Float" defStyleNum="dsFloat" /> | |||
| <itemData name="Character" defStyleNum="dsChar" /> | |||
| <itemData name="String" defStyleNum="dsString" /> | |||
| <itemData name="Escaped Characters" defStyleNum="dsChar" /> | |||
| <itemData name="Comment" defStyleNum="dsComment" /> | |||
| <itemData name="String in Comment" defStyleNum="dsComment" bold="true" /> | |||
| <itemData name="Mismatched Brackets" defStyleNum="dsError" /> | |||
| </itemDatas> | |||
| </highlighting> | |||
| <general> | |||
| <keywords casesensitive="true" /> | |||
| <comments> | |||
| <comment name="multiLine" start="(*" end="*)" region ="comment" /> | |||
| </comments> | |||
| </general> | |||
| </language> | |||
| <!-- kate: space-indent on; indent-width 2; replace-tabs on; --> | |||
+ 222
- 0
syntax/amulet.xml
View File
| @ -0,0 +1,222 @@ | |||
| <?xml version="1.0" encoding="UTF-8"?> | |||
| <!-- Kate syntax highlighting for Objective Caml version 4.02 in the standard and revised syntaxes, with Ocamldoc comments. --> | |||
| <!DOCTYPE language SYSTEM "language.dtd" | |||
| [ | |||
| <!-- Regular expresion constants: --> | |||
| <!ENTITY LOWER "a-z\300-\326\330-\337"> <!-- Lowercase Latin-1 letters. --> | |||
| <!ENTITY UPPER "A-Z\340-\366\370-\377"> <!-- Uppercase Latin-1 letters. --> | |||
| <!ENTITY LETTER "&LOWER;&UPPER;"> <!-- All Latin-1 letters. --> | |||
| <!ENTITY LIDENT "[&LOWER;_][&LETTER;0-9_']*"> <!-- Lowercase OCaml identifiers. --> | |||
| <!ENTITY UIDENT "`?[&UPPER;][&LETTER;0-9_']*"> <!-- Uppercase OCaml identifiers. --> | |||
| <!ENTITY IDENT "`?[&LETTER;][&LETTER;0-9_']*"> <!-- All OCaml identifiers. --> | |||
| <!ENTITY ESC "(\\[ntbr'"\\]|\\[0-9]{3}|\\x[0-9A-Fa-f]{2})"> <!-- OCaml character code escapes. --> | |||
| <!ENTITY DEC "[0-9][0-9_]*"> <!-- Decimal digits with underscores. --> | |||
| <!ENTITY INFIX "[:!#$%&*+\\/<=>?@^|-~][:!#$%&*+\\/<=>?@^|-~\.]*"> | |||
| ]> | |||
| <language name="Amulet" | |||
| extensions="*.ml;*.mli" | |||
| mimetype="text/x-amulet" | |||
| section="Sources" | |||
| version="6" | |||
| priority="10" | |||
| kateversion="2.4" | |||
| author="Abigail Magalhães ([email protected])" | |||
| license="LGPL" > | |||
| <highlighting> | |||
| <list name="Keywords"> | |||
| <item>as</item> | |||
| <item>forall</item> | |||
| <item>begin</item> | |||
| <item>class</item> | |||
| <item>else</item> | |||
| <item>end</item> | |||
| <item>external</item> | |||
| <item>fun</item> | |||
| <item>function</item> | |||
| <item>if</item> | |||
| <item>in</item> | |||
| <item>lazy</item> | |||
| <item>let</item> | |||
| <item>match</item> | |||
| <item>module</item> | |||
| <item>of</item> | |||
| <item>open</item> | |||
| <item>then</item> | |||
| <item>type</item> | |||
| <item>val</item> | |||
| <item>with</item> | |||
| <item>instance</item> | |||
| <item>rec</item> | |||
| <item>import</item> | |||
| <item>and</item> | |||
| </list> | |||
| <list name="Boolean Literals"> | |||
| <item>true</item> | |||
| <item>false</item> | |||
| </list> | |||
| <list name="Pervasive Functions"> | |||
| </list> | |||
| <list name="Pervasive Types"> | |||
| <item>string</item> | |||
| <item>int</item> | |||
| <item>float</item> | |||
| <item>bool</item> | |||
| <item>unit</item> | |||
| <item>lazy</item> | |||
| <item>list</item> | |||
| <item>constraint</item> | |||
| <item>ref</item> | |||
| <item>known_string</item> | |||
| <item>known_int</item> | |||
| <item>row_cons</item> | |||
| </list> | |||
| <list name="Standard Library Modules"> | |||
| <item>Amc</item> | |||
| </list> | |||
| <contexts> | |||
| <context name="Code" lineEndContext="#stay" attribute="Normal"> | |||
| <!-- ] and ]} close code samples in Ocamldoc, so --> | |||
| <!-- nested [ ] and { } brackets have to be allowed for: --> | |||
| <DetectChar char="[" context="Nested Code 1" attribute="Infix Operator" /> | |||
| <DetectChar char="{" context="Nested Code 2" attribute="Infix Operator" /> | |||
| <!-- Comments. --> | |||
| <!-- A (** begins a special comment with Ocamldoc documentation markup. --> | |||
| <Detect2Chars char="(" char1="*" context="Comment" attribute="Comment" beginRegion="comment" /> | |||
| <!-- Interpreter directives. --> | |||
| <!-- (These are lines where the first symbol is a '#' followed by an identifier. --> | |||
| <!-- Such lines could also be part of a method call split over two lines but --> | |||
| <!-- it's unlikey anyone would code like that.) --> | |||
| <!-- String, character and Camlp4 "quotation" constants. --> | |||
| <!-- Note: If you must modify the pattern for characters be precise: --> | |||
| <!-- single quotes have several meanings in Ocaml. --> | |||
| <DetectChar char=""" context="String" attribute="String" /> | |||
| <RegExpr String="'(&ESC;|[^'])'" context="#stay" attribute="Character" /> | |||
| <!-- Identifiers and keywords. --> | |||
| <keyword String="Keywords" context="#stay" attribute="Keyword" /> | |||
| <keyword String="Pervasive Functions" context="#stay" attribute="Pervasive Functions" /> | |||
| <keyword String="Pervasive Types" context="#stay" attribute="Pervasive Types" /> | |||
| <keyword String="Standard Library Modules" context="#stay" attribute="Standard Library Modules" /> | |||
| <keyword String="Boolean Literals" context="#stay" attribute="Boolean Literals" /> | |||
| <RegExpr String="&LIDENT;" context="#stay" attribute="Lowercase Identifier" /> | |||
| <RegExpr String="&UIDENT;" context="#stay" attribute="Uppercase Identifier" /> | |||
| <RegExpr String="'&LIDENT;" context="#stay" attribute="Type Variable" /> | |||
| <RegExpr String="[\-!#\$%&\*\+/<=>\?\@\^\|~\.:]+" | |||
| context="#stay" attribute="Infix Operator" /> | |||
| <RegExpr String="," context="#stay" attribute="Infix Operator" /> | |||
| <!-- Numeric constants. --> | |||
| <!-- Note that they may contain underscores. --> | |||
| <RegExpr String="-?0[xX][0-9A-Fa-f_]+" context="#stay" attribute="Hexadecimal" /> | |||
| <RegExpr String="-?0[oO][0-7_]+" context="#stay" attribute="Octal" /> | |||
| <RegExpr String="-?0[bB][01_]+" context="#stay" attribute="Binary" /> | |||
| <RegExpr String="-?&DEC;(\.&DEC;([eE][-+]?&DEC;)?|[eE][-+]?&DEC;)" context="#stay" attribute="Float" /> | |||
| <RegExpr String="-?&DEC;" context="#stay" attribute="Decimal" /> | |||
| <IncludeRules context="Unmatched Closing Brackets" /> | |||
| </context> | |||
| <context name="Nested Code 1" lineEndContext="#stay" attribute="Normal"> | |||
| <DetectChar char="]" context="#pop" attribute="Infix Operator" /> | |||
| <IncludeRules context="Code" includeAttrib="true" /> | |||
| </context> | |||
| <context name="Nested Code 2" lineEndContext="#stay" attribute="Normal"> | |||
| <DetectChar char="}" context="#pop" attribute="Infix Operator" /> | |||
| <IncludeRules context="Code" includeAttrib="true" /> | |||
| </context> | |||
| <context name="String" lineEndContext="#stay" attribute="String"> | |||
| <DetectChar char=""" context="#pop" attribute="String" /> | |||
| <RegExpr String="&ESC;" context="#stay" attribute="Escaped Characters" /> | |||
| <!-- A backslash at the end of a line in a string indicates --> | |||
| <!-- that the string will continue on the next line: --> | |||
| <RegExpr String="\\$" context="#stay" attribute="Escaped Characters" /> | |||
| </context> | |||
| <context name="Comment" lineEndContext="#stay" attribute="Comment"> | |||
| <Detect2Chars char="*" char1=")" context="#pop" attribute="Comment" endRegion="comment" /> | |||
| <!-- Support for nested comments: --> | |||
| <Detect2Chars char="(" char1="*" context="Comment" attribute="Comment" beginRegion="comment" /> | |||
| <!-- Strings in Ocaml comments must be well-formed: --> | |||
| <DetectChar char=""" context="String in Comment" attribute="String in Comment" /> | |||
| </context> | |||
| <context name="String in Comment" lineEndContext="#stay" attribute="String in Comment"> | |||
| <DetectChar char=""" context="#pop" attribute="String in Comment" /> | |||
| <IncludeRules context="String" /> | |||
| </context> | |||
| <!-- Unmatched closing brackets- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - --> | |||
| <context name="Unmatched Closing Brackets" lineEndContext="#stay" attribute="Normal"> | |||
| <Detect2Chars char="*" char1=")" context="#pop" attribute="Mismatched Brackets" /> | |||
| <Detect2Chars char="v" char1="}" context="#stay" attribute="Mismatched Brackets" /> | |||
| <Detect2Chars char="]" char1="}" context="#stay" attribute="Mismatched Brackets" /> | |||
| <Detect2Chars char="%" char1="}" context="#stay" attribute="Mismatched Brackets" /> | |||
| <DetectChar char="]" context="#stay" attribute="Mismatched Brackets" /> | |||
| <DetectChar char="}" context="#stay" attribute="Mismatched Brackets" /> | |||
| </context> | |||
| </contexts> | |||
| <itemDatas> | |||
| <itemData name="Keyword" defStyleNum="dsKeyword" /> | |||
| <itemData name="Normal" defStyleNum="dsNormal" /> | |||
| <itemData name="Infix Operator" defStyleNum="dsOperator" /> | |||
| <itemData name="Uppercase Identifier" defStyleNum="dsDataType" italic="true" /> | |||
| <itemData name="Lowercase Identifier" defStyleNum="dsVariable" /> | |||
| <!-- Lowercase pervasive identifiers: --> | |||
| <itemData name="Pervasive Functions" defStyleNum="dsFunction" /> | |||
| <itemData name="Pervasive Types" defStyleNum="dsDataType" /> | |||
| <!-- Type variables --> | |||
| <itemData name="Type Variable" defStyleNum="dsSpecialString" /> | |||
| <!-- Uppercase pervasive identifiers: --> | |||
| <itemData name="Standard Library Modules" defStyleNum="dsDataType" italic="true" /> | |||
| <itemData name="Boolean Literals" defStyleNum="dsConstant" /> | |||
| <itemData name="Decimal" defStyleNum="dsDecVal" /> | |||
| <itemData name="Hexadecimal" defStyleNum="dsBaseN" /> | |||
| <itemData name="Octal" defStyleNum="dsBaseN" /> | |||
| <itemData name="Binary" defStyleNum="dsBaseN" /> | |||
| <itemData name="Float" defStyleNum="dsFloat" /> | |||
| <itemData name="Character" defStyleNum="dsChar" /> | |||
| <itemData name="String" defStyleNum="dsString" /> | |||
| <itemData name="Escaped Characters" defStyleNum="dsChar" /> | |||
| <itemData name="Comment" defStyleNum="dsComment" /> | |||
| <itemData name="String in Comment" defStyleNum="dsComment" bold="true" /> | |||
| <itemData name="Mismatched Brackets" defStyleNum="dsError" /> | |||
| </itemDatas> | |||
| </highlighting> | |||
| <general> | |||
| <keywords casesensitive="true" /> | |||
| <comments> | |||
| <comment name="multiLine" start="(*" end="*)" region ="comment" /> | |||
| </comments> | |||
| </general> | |||
| </language> | |||
| <!-- kate: space-indent on; indent-width 2; replace-tabs on; --> | |||
+ 2
- 0
templates/archive.html
View File
| @ -0,0 +1,2 @@ | |||
| Here you can find all my previous posts: | |||
| $partial("templates/post-list.html")$ | |||
+ 71
- 0
templates/default.html
View File
| @ -0,0 +1,71 @@ | |||
| <!DOCTYPE html> | |||
| <html> | |||
| <head> | |||
| <meta name="viewport" content="width=device-width, initial-scale=1" /> | |||
| <meta http-equiv="Content-Type" content="text/html; charset=UTF-8" /> | |||
| <title>$title$</title> | |||
| <link rel="stylesheet" type="text/css" href="/css/default.css" /> | |||
| <link rel="stylesheet" type="text/css" href="/css/code.css" /> | |||
| <link rel="stylesheet" type="text/css" href="/css/katex.min.css" /> | |||
| <link rel="apple-touch-icon" sizes="180x180" href="/static/icon/apple-touch-icon.png"> | |||
| <link rel="icon" type="image/png" sizes="32x32" href="/static/icon/favicon-32x32.png"> | |||
| <link rel="icon" type="image/png" sizes="16x16" href="/static/icon/favicon-16x16.png"> | |||
| <link rel="alternate" type="application/rss+xml" href="/rss.xml" title="Blog feed for abby.how" /> | |||
| <meta property="og:type" content="website"> | |||
| <meta property="og:title" content="$title$"> | |||
| <meta name="title" content="$title$"> | |||
| <noscript> | |||
| <style> .script { display: none } </style> | |||
| </noscript> | |||
| $if(fastbuild)$ | |||
| <style> | |||
| .math { | |||
| color: red; | |||
| } | |||
| </style> | |||
| $endif$ | |||
| </head> | |||
| <body> | |||
| <a rel="me" href="https://functional.cafe/@hydraz" id=mastodon></a> | |||
| <header> | |||
| <div id="header"> | |||
| <div id="logo"> | |||
| <a href="/">Home</a> | |||
| </div> | |||
| <nav> | |||
| <div id="navigation"> | |||
| <div class="nav-button"><a href="/contact.html">Contact</a></div> | |||
| <div class="nav-button"><a href="/archive.html">Archive</a></div> | |||
| <div class="nav-button"><a href="/oss.html">Licenses</a></div> | |||
| <div class="nav-button"><a href="/feed.xml">RSS</a></div> | |||
| </div> | |||
| </nav> | |||
| </div> | |||
| </header> | |||
| <div id="content"> | |||
| <h1>$title$</h1> | |||
| $body$ | |||
| </div> | |||
| <footer> | |||
| <div id="footer" style="display: flex; justify-content: space-between;"> | |||
| <div> | |||
| </div> | |||
| <div> | |||
| This wobsite is proudly powered by | |||
| <a href="https://haskell.org">Haskell</a>. | |||
| Hosted by <a href="https://shamiko.tmpim.pw">a demon</a>. | |||
| </div> | |||
| </div> | |||
| </footer> | |||
| </body> | |||
| </html> | |||
+ 10
- 0
templates/post-list.html
View File
| @ -0,0 +1,10 @@ | |||
| <ul class="post-list"> | |||
| $for(posts)$ | |||
| <li> | |||
| <div class="post-list-item"> | |||
| <a href="$url$">$title$</a> | |||
| $date$ | |||
| </div> | |||
| </li> | |||
| $endfor$ | |||
| </ul> | |||
+ 10
- 0
templates/post.html
View File
| @ -0,0 +1,10 @@ | |||
| <div class="info"> | |||
| Posted on $date$ | |||
| $if(author)$ | |||
| by $author$ | |||
| $endif$ | |||
| </div> | |||
| <article> | |||
| $body$ | |||
| </article> | |||
+ 20
- 0
templates/tikz.tex
View File
| @ -0,0 +1,20 @@ | |||
| \documentclass{article} | |||
| \usepackage[pdftex,active,tightpage]{preview} | |||
| \usepackage{amsmath} | |||
| \usepackage{amssymb} | |||
| \usepackage{tikz} | |||
| \usetikzlibrary{matrix} | |||
| \usetikzlibrary{calc} | |||
| \usetikzlibrary{arrows.meta} | |||
| \usepackage{xcolor} | |||
| \usepackage{tgpagella} | |||
| \definecolor{red}{RGB}{235, 77, 75} | |||
| \definecolor{blue}{RGB}{9, 123, 227} | |||
| \begin{document} | |||
| \begin{preview} | |||
| \begin{tikzpicture}[auto] | |||
| $body$ | |||
| \end{tikzpicture} | |||
| \end{preview} | |||
| \end{document} | |||